Back to the Color: Learning Depth to Specific Color Transformation for Unsupervised Depth Estimation
2406.07741
0
0
Abstract
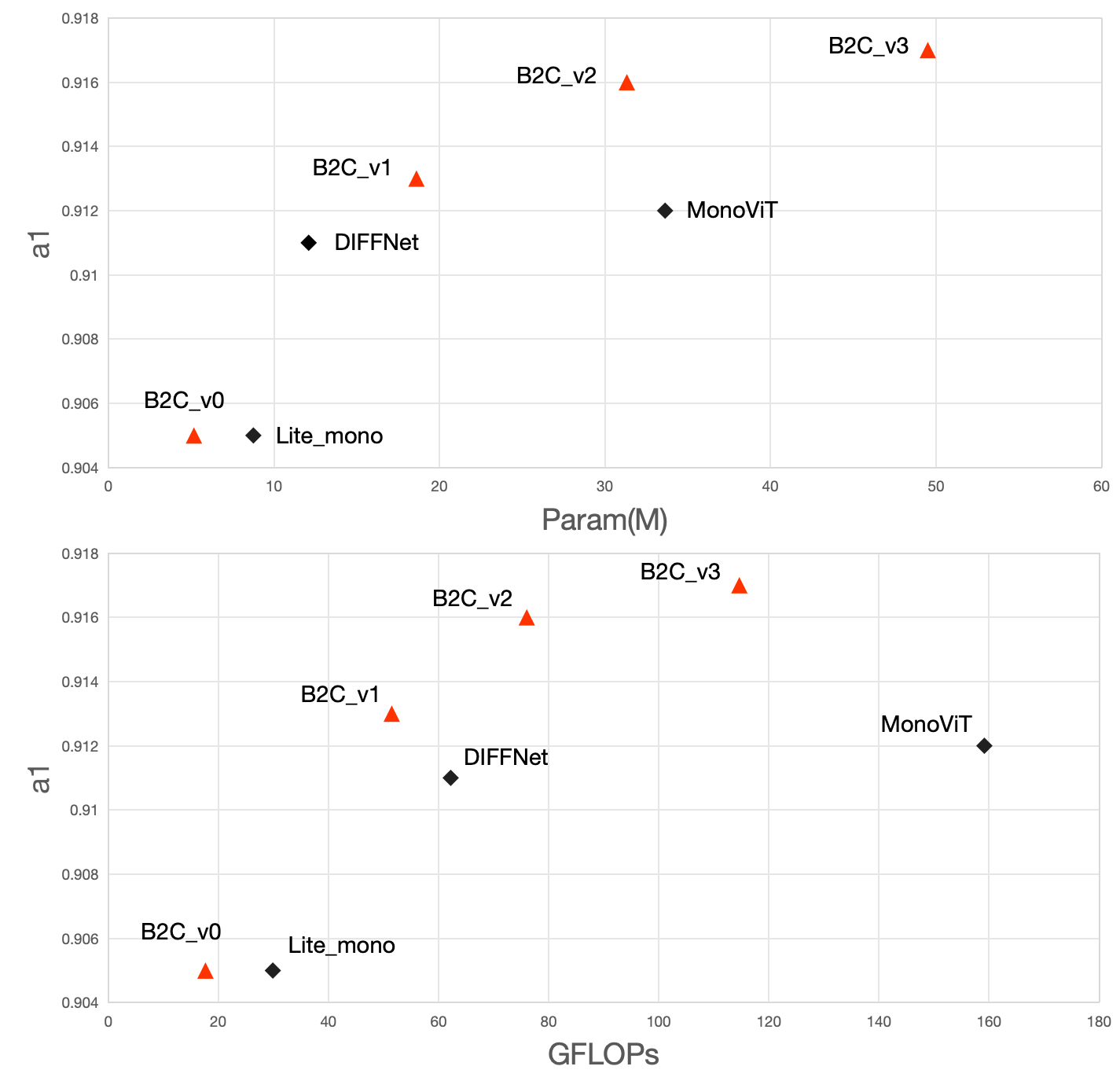
Virtual engines have the capability to generate dense depth maps for various synthetic scenes, making them invaluable for training depth estimation models. However, synthetic colors often exhibit significant discrepancies compared to real-world colors, thereby posing challenges for depth estimation in real-world scenes, particularly in complex and uncertain environments encountered in unsupervised monocular depth estimation tasks. To address this issue, we propose Back2Color, a framework that predicts realistic colors from depth utilizing a model trained on real-world data, thus facilitating the transformation of synthetic colors into real-world counterparts. Additionally, by employing the Syn-Real CutMix method for joint training with both real-world unsupervised and synthetic supervised depth samples, we achieve improved performance in monocular depth estimation for real-world scenes. Moreover, to comprehensively address the impact of non-rigid motions on depth estimation, we propose an auto-learning uncertainty temporal-spatial fusion method (Auto-UTSF), which integrates the benefits of unsupervised learning in both temporal and spatial dimensions. Furthermore, we design a depth estimation network (VADepth) based on the Vision Attention Network. Our Back2Color framework demonstrates state-of-the-art performance, as evidenced by improvements in performance metrics and the production of fine-grained details in our predictions, particularly on challenging datasets such as Cityscapes for unsupervised depth estimation.
Create account to get full access
Overview
- This paper presents a novel unsupervised depth estimation method that learns a depth-to-color transformation to predict depth maps from a single input image.
- The proposed "Vision Attention Depth Network" (VADNet) leverages the relationship between depth and color to learn a depth-to-color mapping without requiring ground truth depth data.
- The method is shown to outperform state-of-the-art unsupervised depth estimation approaches on standard benchmarks.
Plain English Explanation
The paper introduces a new way to estimate the depth of a scene from a single image, without needing any ground truth depth data for training. The key insight is that there is a strong relationship between the colors in an image and the depth of the scene.
The VADNet model learns to map this depth-to-color transformation, allowing it to predict accurate depth maps from color images alone. This is an important advance, as collecting ground truth depth data can be very challenging and expensive, limiting the applicability of supervised depth estimation methods.
By exploiting the inherent connection between color and depth, the new unsupervised approach can learn effective depth prediction models without any labeled depth data. This makes the technique broadly applicable and easy to deploy in real-world scenarios where labeled data may be scarce.
Technical Explanation
The VADNet architecture consists of an encoder-decoder network that takes a color image as input and outputs a corresponding depth map. The core innovation is the inclusion of a "color transformation module" that learns a mapping between the input color features and the target depth values.
This depth-to-color transformation is trained in an unsupervised manner, leveraging the natural correlation between the colors in an image and the underlying scene geometry. By learning this relationship, the model can accurately predict depth without needing any ground truth depth data for supervision.
The VADNet also incorporates a novel "vision attention" mechanism that adaptively focuses on the most informative color features for depth prediction. This helps the model discard irrelevant color variations and better extract the depth-relevant information from the input image.
Experiments on standard benchmarks like KITTI and NYUv2 demonstrate that the proposed VADNet outperforms previous state-of-the-art unsupervised depth estimation methods by a significant margin.
Critical Analysis
The paper presents a compelling unsupervised depth estimation approach that leverages the inherent depth-color relationship in a novel way. The use of the color transformation module and vision attention mechanism are clever techniques that help the model effectively learn depth from color alone.
However, the paper does not address some potential limitations of the method. For example, it is unclear how the approach would perform on more diverse datasets beyond the tested indoor and outdoor scenes. There may also be edge cases or specific environments where the depth-color mapping is less reliable, which could affect the model's generalization.
Additionally, while the unsupervised nature of the method is a strength, it would be interesting to see how the VADNet performs when combined with limited supervised depth data, as in a semi-supervised setting. This could potentially further boost the depth estimation accuracy.
Overall, the VADNet represents an important advance in unsupervised depth estimation, and the authors' insights into the depth-color relationship are a valuable contribution to the field. Further research into the method's robustness and potential extensions could lead to even more impactful applications.
Conclusion
This paper presents a novel unsupervised depth estimation approach called VADNet that learns a depth-to-color transformation to predict accurate depth maps from single input images. By exploiting the inherent relationship between color and depth, the model can learn effective depth prediction without any ground truth depth data for supervision.
The key technical innovations, including the color transformation module and vision attention mechanism, allow the VADNet to outperform state-of-the-art unsupervised depth estimation methods on standard benchmarks. This advance has the potential to significantly expand the applicability of depth estimation, as it removes the need for costly ground truth depth data collection.
While the paper highlights the strengths of the proposed approach, further research into its robustness and potential extensions could lead to even more impactful applications in areas like autonomous navigation, 3D reconstruction, and mixed reality experiences.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Domain-Transferred Synthetic Data Generation for Improving Monocular Depth Estimation
Seungyeop Lee, Knut Peterson, Solmaz Arezoomandan, Bill Cai, Peihan Li, Lifeng Zhou, David Han
0
0
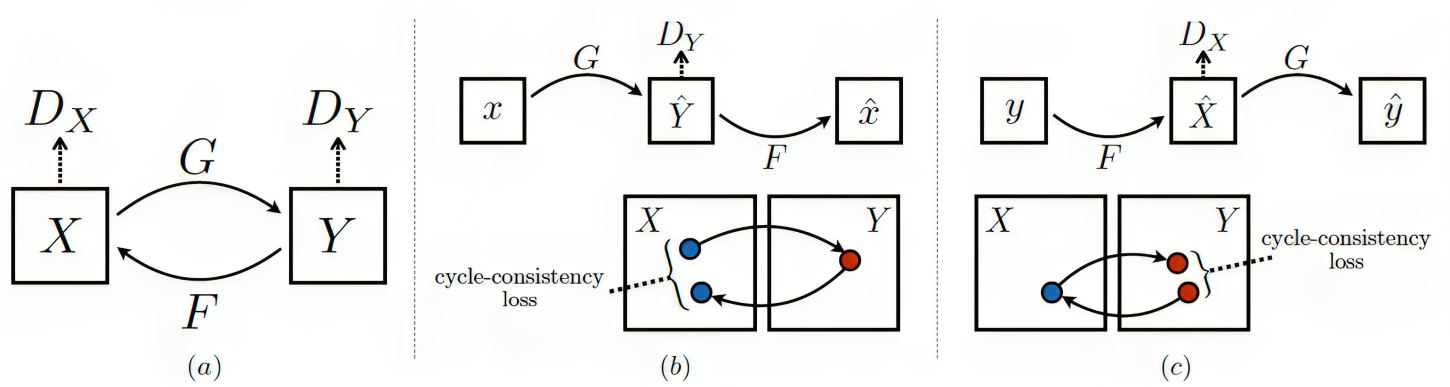
A major obstacle to the development of effective monocular depth estimation algorithms is the difficulty in obtaining high-quality depth data that corresponds to collected RGB images. Collecting this data is time-consuming and costly, and even data collected by modern sensors has limited range or resolution, and is subject to inconsistencies and noise. To combat this, we propose a method of data generation in simulation using 3D synthetic environments and CycleGAN domain transfer. We compare this method of data generation to the popular NYUDepth V2 dataset by training a depth estimation model based on the DenseDepth structure using different training sets of real and simulated data. We evaluate the performance of the models on newly collected images and LiDAR depth data from a Husky robot to verify the generalizability of the approach and show that GAN-transformed data can serve as an effective alternative to real-world data, particularly in depth estimation.
5/3/2024
🔄
Enhanced Object Tracking by Self-Supervised Auxiliary Depth Estimation Learning
Zhenyu Wei, Yujie He, Zhanchuan Cai
0
0
RGB-D tracking significantly improves the accuracy of object tracking. However, its dependency on real depth inputs and the complexity involved in multi-modal fusion limit its applicability across various scenarios. The utilization of depth information in RGB-D tracking inspired us to propose a new method, named MDETrack, which trains a tracking network with an additional capability to understand the depth of scenes, through supervised or self-supervised auxiliary Monocular Depth Estimation learning. The outputs of MDETrack's unified feature extractor are fed to the side-by-side tracking head and auxiliary depth estimation head, respectively. The auxiliary module will be discarded in inference, thus keeping the same inference speed. We evaluated our models with various training strategies on multiple datasets, and the results show an improved tracking accuracy even without real depth. Through these findings we highlight the potential of depth estimation in enhancing object tracking performance.
5/24/2024
Depth Anything V2
Lihe Yang, Bingyi Kang, Zilong Huang, Zhen Zhao, Xiaogang Xu, Jiashi Feng, Hengshuang Zhao
0
0
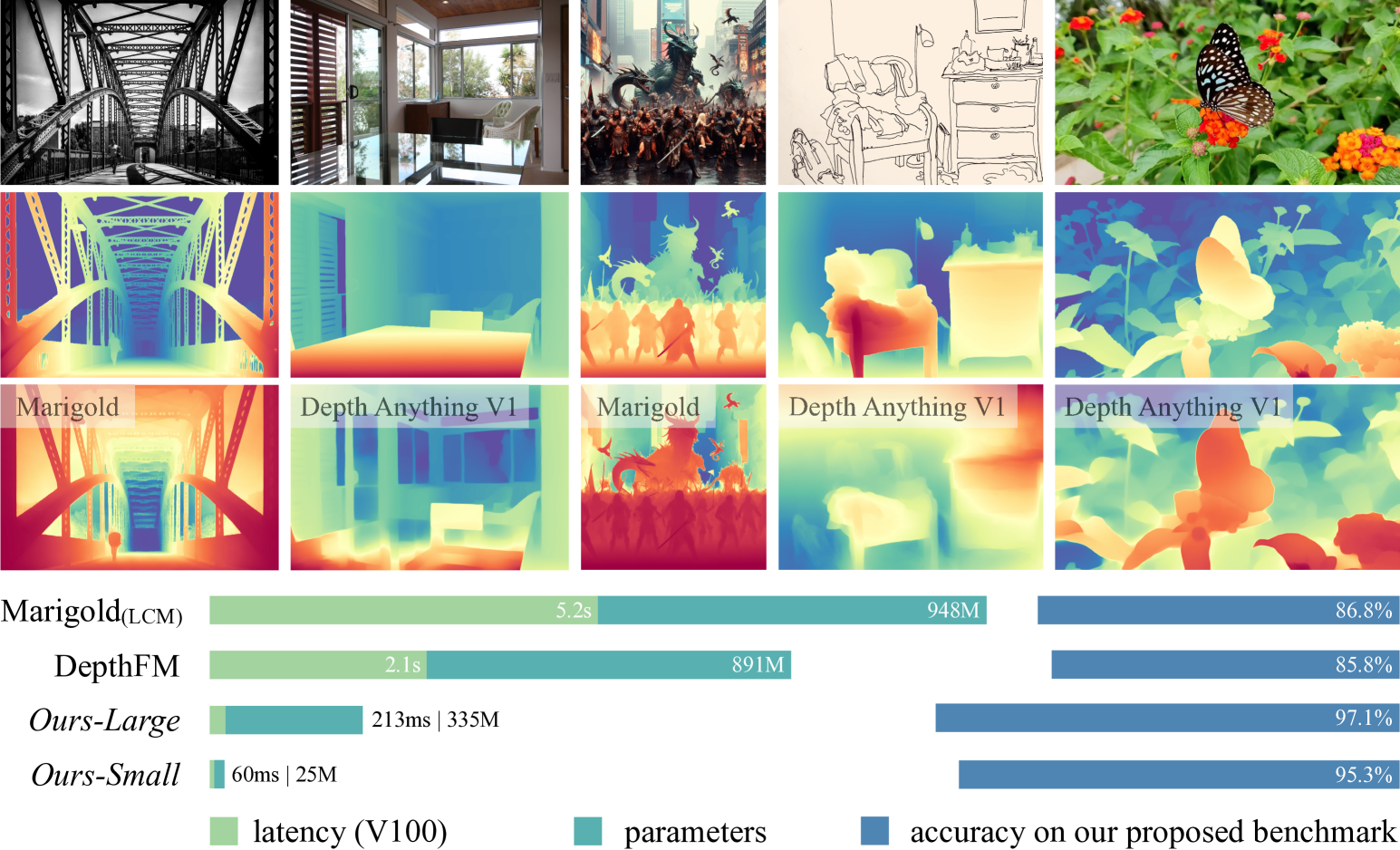
This work presents Depth Anything V2. Without pursuing fancy techniques, we aim to reveal crucial findings to pave the way towards building a powerful monocular depth estimation model. Notably, compared with V1, this version produces much finer and more robust depth predictions through three key practices: 1) replacing all labeled real images with synthetic images, 2) scaling up the capacity of our teacher model, and 3) teaching student models via the bridge of large-scale pseudo-labeled real images. Compared with the latest models built on Stable Diffusion, our models are significantly more efficient (more than 10x faster) and more accurate. We offer models of different scales (ranging from 25M to 1.3B params) to support extensive scenarios. Benefiting from their strong generalization capability, we fine-tune them with metric depth labels to obtain our metric depth models. In addition to our models, considering the limited diversity and frequent noise in current test sets, we construct a versatile evaluation benchmark with precise annotations and diverse scenes to facilitate future research.
6/14/2024
📈
Mining Supervision for Dynamic Regions in Self-Supervised Monocular Depth Estimation
Hoang Chuong Nguyen, Tianyu Wang, Jose M. Alvarez, Miaomiao Liu
0
0
This paper focuses on self-supervised monocular depth estimation in dynamic scenes trained on monocular videos. Existing methods jointly estimate pixel-wise depth and motion, relying mainly on an image reconstruction loss. Dynamic regions1 remain a critical challenge for these methods due to the inherent ambiguity in depth and motion estimation, resulting in inaccurate depth estimation. This paper proposes a self-supervised training framework exploiting pseudo depth labels for dynamic regions from training data. The key contribution of our framework is to decouple depth estimation for static and dynamic regions of images in the training data. We start with an unsupervised depth estimation approach, which provides reliable depth estimates for static regions and motion cues for dynamic regions and allows us to extract moving object information at the instance level. In the next stage, we use an object network to estimate the depth of those moving objects assuming rigid motions. Then, we propose a new scale alignment module to address the scale ambiguity between estimated depths for static and dynamic regions. We can then use the depth labels generated to train an end-to-end depth estimation network and improve its performance. Extensive experiments on the Cityscapes and KITTI datasets show that our self-training strategy consistently outperforms existing self/unsupervised depth estimation methods.
4/24/2024