Domain-Transferred Synthetic Data Generation for Improving Monocular Depth Estimation
2405.01113
0
0
Abstract
A major obstacle to the development of effective monocular depth estimation algorithms is the difficulty in obtaining high-quality depth data that corresponds to collected RGB images. Collecting this data is time-consuming and costly, and even data collected by modern sensors has limited range or resolution, and is subject to inconsistencies and noise. To combat this, we propose a method of data generation in simulation using 3D synthetic environments and CycleGAN domain transfer. We compare this method of data generation to the popular NYUDepth V2 dataset by training a depth estimation model based on the DenseDepth structure using different training sets of real and simulated data. We evaluate the performance of the models on newly collected images and LiDAR depth data from a Husky robot to verify the generalizability of the approach and show that GAN-transformed data can serve as an effective alternative to real-world data, particularly in depth estimation.
Create account to get full access
Overview
- The paper explores using domain-transferred synthetic data to improve monocular depth estimation, a task that aims to predict the depth information of a scene from a single camera image.
- The researchers propose a method to generate synthetic depth data that better matches the target domain, and then use this data to train a depth estimation model.
- The approach involves transferring the style of real-world images to synthetic depth data, resulting in more realistic and useful training samples.
- Experiments show the proposed method outperforms existing approaches for monocular depth estimation on various benchmark datasets.
Plain English Explanation
Monocular depth estimation is the task of predicting the depth or distance information of objects in an image captured by a single camera. This is a challenging problem because cameras only capture 2D information, but we need 3D depth data to understand the scene.
To tackle this, researchers have explored using synthetic depth data to train depth estimation models. However, synthetic data often looks quite different from real-world images, so the models don't perform as well when applied to real scenes.
This paper presents a new approach to generate synthetic depth data that is more similar to real-world images. The key idea is to transfer the style or visual characteristics of real-world images onto the synthetic depth data. This makes the synthetic samples look more realistic and helps the depth estimation model learn features that are useful for real-world scenes.
The researchers demonstrate that depth estimation models trained on this domain-transferred synthetic data outperform models trained on standard synthetic data or real-world data alone. This shows the value of generating synthetic data that better matches the target domain, rather than relying solely on real-world training samples, which can be expensive and time-consuming to collect.
Technical Explanation
The paper proposes a method called Domain-Transferred Synthetic Data Generation for Improving Monocular Depth Estimation. The core idea is to generate synthetic depth data that is stylistically similar to real-world images, in order to improve the performance of monocular depth estimation models.
The method works as follows:
- Synthetic depth data is generated using a graphics engine, producing clean depth maps with perfect ground truth.
- A style transfer network is used to transfer the visual style of real-world images onto the synthetic depth data. This makes the synthetic samples look more realistic and visually similar to the target domain.
- The style-transferred synthetic depth data is then used to train a depth estimation model, along with any available real-world training data.
The researchers evaluate their approach on several monocular depth estimation benchmarks, including NYUv2, KITTI, and CityScapes. They show that models trained on the domain-transferred synthetic data outperform those trained on standard synthetic data or real-world data alone.
The proposed Domain-Transferred Synthetic Data Generation approach provides a way to leverage the benefits of synthetic depth data while overcoming the domain gap between synthetic and real-world images.
Critical Analysis
The paper presents a compelling approach to improving monocular depth estimation by generating more realistic synthetic training data. The style transfer technique used to bridge the domain gap is a clever and effective solution.
One potential limitation is that the style transfer process adds an additional step to the pipeline, which could introduce new sources of error or instability. The authors do not provide a detailed analysis of the failure modes or edge cases of the style transfer component.
Additionally, the paper focuses on evaluating the depth estimation performance on standard benchmarks, but does not explore the real-world deployment implications or potential failure modes in practical applications. Further research could investigate how the domain-transferred synthetic data performs in diverse, unconstrained environments.
Overall, the paper makes a valuable contribution to the field of monocular depth estimation by demonstrating the benefits of using domain-transferred synthetic data. The approach shows promise for improving the robustness and generalization of depth estimation models, and could be extended to other vision tasks that rely on synthetic data.
Conclusion
This paper presents a novel method for generating synthetic depth data that is stylistically similar to real-world images, in order to improve the performance of monocular depth estimation models. By transferring the visual style of real-world images onto synthetic depth data, the researchers are able to create more realistic training samples that help depth estimation models perform better on real-world scenes.
The results show that models trained on this domain-transferred synthetic data outperform those trained on standard synthetic data or real-world data alone. This highlights the value of bridging the gap between synthetic and real-world data, rather than relying solely on scarce real-world training samples.
Overall, the proposed approach represents an important advancement in the field of monocular depth estimation, with potential applications in areas like autonomous vehicles, robotics, and augmented reality. By generating more realistic synthetic training data, the method can help depth estimation models become more robust and generalize better to diverse real-world environments.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤔
Cross-Domain Synthetic-to-Real In-the-Wild Depth and Normal Estimation for 3D Scene Understanding
Jay Bhanushali, Manivannan Muniyandi, Praneeth Chakravarthula
0
0
We present a cross-domain inference technique that learns from synthetic data to estimate depth and normals for in-the-wild omnidirectional 3D scenes encountered in real-world uncontrolled settings. To this end, we introduce UBotNet, an architecture that combines UNet and Bottleneck Transformer elements to predict consistent scene normals and depth. We also introduce the OmniHorizon synthetic dataset containing 24,335 omnidirectional images that represent a wide variety of outdoor environments, including buildings, streets, and diverse vegetation. This dataset is generated from expansive, lifelike virtual spaces and encompasses dynamic scene elements, such as changing lighting conditions, different times of day, pedestrians, and vehicles. Our experiments show that UBotNet achieves significantly improved accuracy in depth estimation and normal estimation compared to existing models. Lastly, we validate cross-domain synthetic-to-real depth and normal estimation on real outdoor images using UBotNet trained solely on our synthetic OmniHorizon dataset, demonstrating the potential of both the synthetic dataset and the proposed network for real-world scene understanding applications.
6/10/2024
🧠
Do More With What You Have: Transferring Depth-Scale from Labeled to Unlabeled Domains
Alexandra Dana, Nadav Carmel, Amit Shomer, Ofer Manela, Tomer Peleg
0
0
Transferring the absolute depth prediction capabilities of an estimator to a new domain is a task with significant real-world applications. This task is specifically challenging when images from the new domain are collected without ground-truth depth measurements, and possibly with sensors of different intrinsics. To overcome such limitations, a recent zero-shot solution was trained on an extensive training dataset and encoded the various camera intrinsics. Other solutions generated synthetic data with depth labels that matched the intrinsics of the new target data to enable depth-scale transfer between the domains. In this work we present an alternative solution that can utilize any existing synthetic or real dataset, that has a small number of images annotated with ground truth depth labels. Specifically, we show that self-supervised depth estimators result in up-to-scale predictions that are linearly correlated to their absolute depth values across the domain, a property that we model in this work using a single scalar. In addition, aligning the field-of-view of two datasets prior to training, results in a common linear relationship for both domains. We use this observed property to transfer the depth-scale from source datasets that have absolute depth labels to new target datasets that lack these measurements, enabling absolute depth predictions in the target domain. The suggested method was successfully demonstrated on the KITTI, DDAD and nuScenes datasets, while using other existing real or synthetic source datasets, that have a different field-of-view, other image style or structural content, achieving comparable or better accuracy than other existing methods that do not use target ground-truth depths.
4/16/2024
🖼️
Repurposing Diffusion-Based Image Generators for Monocular Depth Estimation
Bingxin Ke, Anton Obukhov, Shengyu Huang, Nando Metzger, Rodrigo Caye Daudt, Konrad Schindler
0
0
Monocular depth estimation is a fundamental computer vision task. Recovering 3D depth from a single image is geometrically ill-posed and requires scene understanding, so it is not surprising that the rise of deep learning has led to a breakthrough. The impressive progress of monocular depth estimators has mirrored the growth in model capacity, from relatively modest CNNs to large Transformer architectures. Still, monocular depth estimators tend to struggle when presented with images with unfamiliar content and layout, since their knowledge of the visual world is restricted by the data seen during training, and challenged by zero-shot generalization to new domains. This motivates us to explore whether the extensive priors captured in recent generative diffusion models can enable better, more generalizable depth estimation. We introduce Marigold, a method for affine-invariant monocular depth estimation that is derived from Stable Diffusion and retains its rich prior knowledge. The estimator can be fine-tuned in a couple of days on a single GPU using only synthetic training data. It delivers state-of-the-art performance across a wide range of datasets, including over 20% performance gains in specific cases. Project page: https://marigoldmonodepth.github.io.
4/4/2024
Back to the Color: Learning Depth to Specific Color Transformation for Unsupervised Depth Estimation
Yufan Zhu, Chongzhi Ran, Mingtao Feng, Weisheng Dong, Antonio M. L'opez, Guangming Shi
0
0
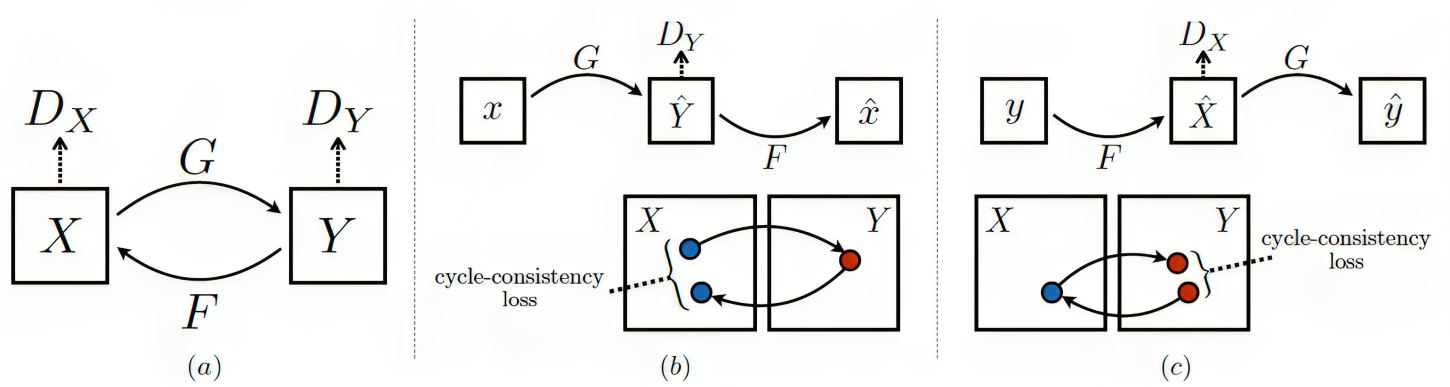
Virtual engines have the capability to generate dense depth maps for various synthetic scenes, making them invaluable for training depth estimation models. However, synthetic colors often exhibit significant discrepancies compared to real-world colors, thereby posing challenges for depth estimation in real-world scenes, particularly in complex and uncertain environments encountered in unsupervised monocular depth estimation tasks. To address this issue, we propose Back2Color, a framework that predicts realistic colors from depth utilizing a model trained on real-world data, thus facilitating the transformation of synthetic colors into real-world counterparts. Additionally, by employing the Syn-Real CutMix method for joint training with both real-world unsupervised and synthetic supervised depth samples, we achieve improved performance in monocular depth estimation for real-world scenes. Moreover, to comprehensively address the impact of non-rigid motions on depth estimation, we propose an auto-learning uncertainty temporal-spatial fusion method (Auto-UTSF), which integrates the benefits of unsupervised learning in both temporal and spatial dimensions. Furthermore, we design a depth estimation network (VADepth) based on the Vision Attention Network. Our Back2Color framework demonstrates state-of-the-art performance, as evidenced by improvements in performance metrics and the production of fine-grained details in our predictions, particularly on challenging datasets such as Cityscapes for unsupervised depth estimation.
6/26/2024