Backward Learning for Goal-Conditioned Policies
2312.05044
0
0

Abstract
Can we learn policies in reinforcement learning without rewards? Can we learn a policy just by trying to reach a goal state? We answer these questions positively by proposing a multi-step procedure that first learns a world model that goes backward in time, secondly generates goal-reaching backward trajectories, thirdly improves those sequences using shortest path finding algorithms, and finally trains a neural network policy by imitation learning. We evaluate our method on a deterministic maze environment where the observations are $64times 64$ pixel bird's eye images and can show that it consistently reaches several goals.
Create account to get full access
Overview
- This paper proposes a new approach called "Backward Learning" for training goal-conditioned policies in reinforcement learning.
- The key idea is to learn the policy by optimizing the expected return in reverse, starting from the goal state and working backwards to the initial state.
- The authors demonstrate that this backward learning approach can lead to faster convergence and better performance compared to standard goal-conditioned policy learning methods.
Plain English Explanation
In reinforcement learning, the goal is to train an agent to perform well on a task, such as navigating a maze or controlling a robot. One common approach is to use goal-conditioned policies, where the agent's actions depend on both the current state and the desired goal state.
The traditional way to learn these goal-conditioned policies is to optimize the expected return starting from the initial state and working forward towards the goal. However, the authors of this paper propose a novel "Backward Learning" approach, where the optimization is performed in reverse, starting from the goal state and working backwards to the initial state.
The intuition behind this backward learning method is that it can be more efficient, as the agent can focus on learning the most important parts of the policy - the steps needed to reach the goal from any given state. By learning the policy in this reverse direction, the agent can converge to a good policy faster and achieve better overall performance.
The paper demonstrates the effectiveness of this backward learning approach through experiments on various reinforcement learning tasks, showing that it can outperform standard goal-conditioned policy learning methods.
Technical Explanation
The key contribution of this paper is the introduction of a "Backward Learning" algorithm for training goal-conditioned policies in reinforcement learning.
In standard goal-conditioned policy learning, the objective is to learn a policy π(a|s,g) that maps the current state s and the desired goal state g to an action a, in order to maximize the expected return starting from the initial state. This is typically done using policy optimization techniques or model-based reinforcement learning approaches.
The key innovation in this paper is to instead optimize the policy in reverse, starting from the goal state and working backwards to the initial state. Specifically, the authors define a "backward" value function V_b(s|g) that represents the expected return when starting from state s and reaching the goal state g. They then use this backward value function to define a new objective function and optimize the policy π(a|s,g) accordingly.
The authors show that this backward learning approach can lead to faster convergence and better final performance compared to standard goal-conditioned policy learning methods. They attribute this to the ability of the backward learning approach to focus on learning the most important parts of the policy - the steps needed to reach the goal from any given state.
The paper also presents a model-based extension of the backward learning algorithm, where a dynamics model is learned in parallel to further accelerate the learning process. This model-based backward learning method is demonstrated to outperform both standard goal-conditioned policy learning and the basic backward learning approach on a range of reinforcement learning tasks.
Critical Analysis
The authors provide a thorough evaluation of their backward learning approach, including comparisons to several baseline methods on a variety of reinforcement learning tasks. The results generally show that the backward learning approach can achieve faster convergence and better final performance, which is a promising finding.
However, the paper does not address some potential limitations or caveats of the approach. For example, the backward learning method may be more sensitive to the quality of the initial policy or the dynamics model (in the model-based case), as errors in these components could propagate more strongly through the backward optimization process.
Additionally, the backward learning approach may face challenges in domains with sparse rewards or complex goal structures, where the backward value function may be more difficult to estimate accurately. The paper does not explore these types of more challenging scenarios in depth.
Overall, the backward learning method presented in this paper is an interesting and potentially impactful contribution to the field of goal-conditioned reinforcement learning. However, further research is needed to better understand the strengths, weaknesses, and broader applicability of this approach, especially in more complex and realistic environments.
Conclusion
This paper introduces a novel "Backward Learning" algorithm for training goal-conditioned policies in reinforcement learning. The key idea is to optimize the policy in reverse, starting from the goal state and working backwards to the initial state, rather than the standard forward optimization approach.
The authors demonstrate that this backward learning method can lead to faster convergence and better final performance compared to standard goal-conditioned policy learning techniques. They also present a model-based extension of the backward learning algorithm that further improves the learning efficiency.
The backward learning approach proposed in this paper represents an innovative and promising direction for advancing the state-of-the-art in goal-conditioned reinforcement learning. While the method shows promising results, further research is needed to fully understand its strengths, limitations, and broader applicability, especially in more complex and challenging environments.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
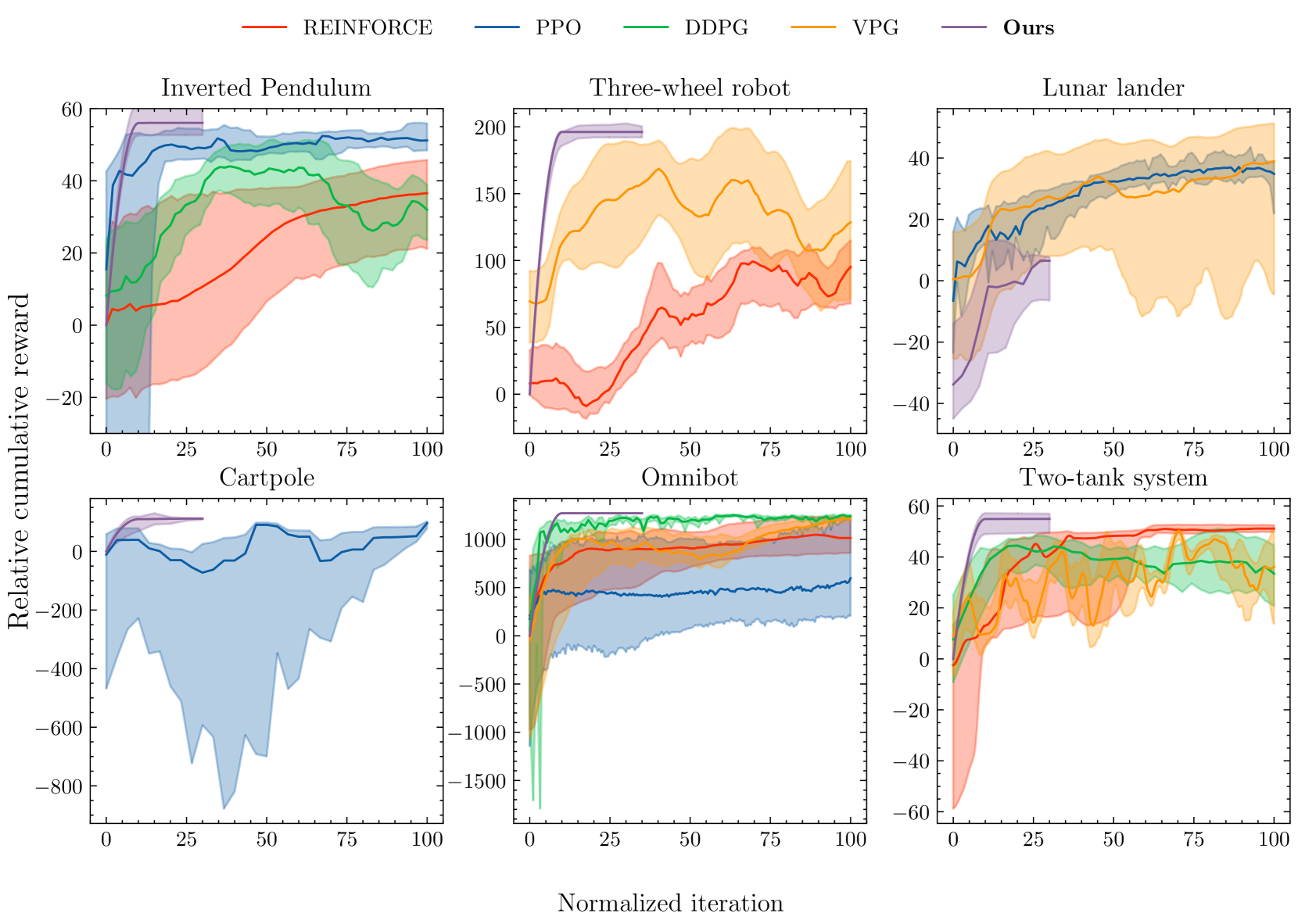
An approach to improve agent learning via guaranteeing goal reaching in all episodes
Pavel Osinenko, Grigory Yaremenko, Georgiy Malaniya, Anton Bolychev
0
0
Reinforcement learning is commonly concerned with problems of maximizing accumulated rewards in Markov decision processes. Oftentimes, a certain goal state or a subset of the state space attain maximal reward. In such a case, the environment may be considered solved when the goal is reached. Whereas numerous techniques, learning or non-learning based, exist for solving environments, doing so optimally is the biggest challenge. Say, one may choose a reward rate which penalizes the action effort. Reinforcement learning is currently among the most actively developed frameworks for solving environments optimally by virtue of maximizing accumulated reward, in other words, returns. Yet, tuning agents is a notoriously hard task as reported in a series of works. Our aim here is to help the agent learn a near-optimal policy efficiently while ensuring a goal reaching property of some basis policy that merely solves the environment. We suggest an algorithm, which is fairly flexible, and can be used to augment practically any agent as long as it comprises of a critic. A formal proof of a goal reaching property is provided. Simulation experiments on six problems under five agents, including the benchmarked one, provided an empirical evidence that the learning can indeed be boosted while ensuring goal reaching property.
5/30/2024

Planning with a Learned Policy Basis to Optimally Solve Complex Tasks
Guillermo Infante, David Kuric, Anders Jonsson, Vicenc{c} G'omez, Herke van Hoof
0
0
Conventional reinforcement learning (RL) methods can successfully solve a wide range of sequential decision problems. However, learning policies that can generalize predictably across multiple tasks in a setting with non-Markovian reward specifications is a challenging problem. We propose to use successor features to learn a policy basis so that each (sub)policy in it solves a well-defined subproblem. In a task described by a finite state automaton (FSA) that involves the same set of subproblems, the combination of these (sub)policies can then be used to generate an optimal solution without additional learning. In contrast to other methods that combine (sub)policies via planning, our method asymptotically attains global optimality, even in stochastic environments.
6/4/2024

New!Revisiting Constant Negative Rewards for Goal-Reaching Tasks in Robot Learning
Gautham Vasan, Yan Wang, Fahim Shahriar, James Bergstra, Martin Jagersand, A. Rupam Mahmood
0
0
Many real-world robot learning problems, such as pick-and-place or arriving at a destination, can be seen as a problem of reaching a goal state as soon as possible. These problems, when formulated as episodic reinforcement learning tasks, can easily be specified to align well with our intended goal: -1 reward every time step with termination upon reaching the goal state, called minimum-time tasks. Despite this simplicity, such formulations are often overlooked in favor of dense rewards due to their perceived difficulty and lack of informativeness. Our studies contrast the two reward paradigms, revealing that the minimum-time task specification not only facilitates learning higher-quality policies but can also surpass dense-reward-based policies on their own performance metrics. Crucially, we also identify the goal-hit rate of the initial policy as a robust early indicator for learning success in such sparse feedback settings. Finally, using four distinct real-robotic platforms, we show that it is possible to learn pixel-based policies from scratch within two to three hours using constant negative rewards.
7/2/2024

Reverse Forward Curriculum Learning for Extreme Sample and Demonstration Efficiency in Reinforcement Learning
Stone Tao, Arth Shukla, Tse-kai Chan, Hao Su
0
0
Reinforcement learning (RL) presents a promising framework to learn policies through environment interaction, but often requires an infeasible amount of interaction data to solve complex tasks from sparse rewards. One direction includes augmenting RL with offline data demonstrating desired tasks, but past work often require a lot of high-quality demonstration data that is difficult to obtain, especially for domains such as robotics. Our approach consists of a reverse curriculum followed by a forward curriculum. Unique to our approach compared to past work is the ability to efficiently leverage more than one demonstration via a per-demonstration reverse curriculum generated via state resets. The result of our reverse curriculum is an initial policy that performs well on a narrow initial state distribution and helps overcome difficult exploration problems. A forward curriculum is then used to accelerate the training of the initial policy to perform well on the full initial state distribution of the task and improve demonstration and sample efficiency. We show how the combination of a reverse curriculum and forward curriculum in our method, RFCL, enables significant improvements in demonstration and sample efficiency compared against various state-of-the-art learning-from-demonstration baselines, even solving previously unsolvable tasks that require high precision and control.
5/7/2024