Model-Based Reinforcement Learning for Atari
1903.00374
58
0
🏅
Abstract
Model-free reinforcement learning (RL) can be used to learn effective policies for complex tasks, such as Atari games, even from image observations. However, this typically requires very large amounts of interaction -- substantially more, in fact, than a human would need to learn the same games. How can people learn so quickly? Part of the answer may be that people can learn how the game works and predict which actions will lead to desirable outcomes. In this paper, we explore how video prediction models can similarly enable agents to solve Atari games with fewer interactions than model-free methods. We describe Simulated Policy Learning (SimPLe), a complete model-based deep RL algorithm based on video prediction models and present a comparison of several model architectures, including a novel architecture that yields the best results in our setting. Our experiments evaluate SimPLe on a range of Atari games in low data regime of 100k interactions between the agent and the environment, which corresponds to two hours of real-time play. In most games SimPLe outperforms state-of-the-art model-free algorithms, in some games by over an order of magnitude.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Model-free reinforcement learning (RL) can be used to solve complex tasks like Atari games from image observations, but requires a lot of interaction.
- In contrast, humans can learn these games much more quickly, likely by understanding how the game works and predicting good actions.
- This paper explores how video prediction models can enable agents to solve Atari games with fewer interactions than model-free methods.
Plain English Explanation
Training an AI system to play Atari games from just the video images can be a challenging task. Typical "model-free" reinforcement learning approaches require the AI to interact with the game environment an enormous number of times before it can learn an effective strategy. This is substantially more interaction than a human would need to learn the same games.
The key insight is that humans don't just blindly try random actions until they succeed. Instead, people develop an understanding of how the game works and can mentally predict which actions are likely to lead to good outcomes. This allows people to learn the games much more efficiently.
The researchers in this paper wondered if AI systems could similarly leverage predictive models of the game environment to learn more quickly. They developed an approach called Simulated Policy Learning (SimPLe) that uses video prediction models to simulate the effects of potential actions, enabling the AI to plan ahead and learn effective strategies with far fewer actual interactions with the game.
Technical Explanation
The core of the SimPLe approach is a video prediction model that can forecast future frames of the game based on the current state and a proposed action. By training this model, the AI can learn to imagine the consequences of different actions without having to actually try them out in the environment.
The researchers experimented with several different neural network architectures for the video prediction model, including a novel design that performed the best in their tests. They then integrated this video prediction model into a reinforcement learning algorithm, allowing the AI to select actions by simulating their likely outcomes.
The team evaluated SimPLe on a range of Atari games, limiting the agent to only 100,000 interactions with the environment (about 2 hours of real-time play). In most games, SimPLe outperformed state-of-the-art model-free RL algorithms, often by a significant margin. This demonstrates the potential of leveraging predictive models to enable more efficient reinforcement learning.
Critical Analysis
The paper provides a compelling demonstration of how predictive models can enhance sample efficiency in reinforcement learning. However, the 100,000 interaction limit is still quite high compared to human learning. Additional research is needed to further bridge this gap and develop AI systems that can learn complex tasks as quickly as people.
Another potential issue is the reliance on accurate video prediction. If the prediction model makes systematic errors, that could lead the agent astray during planning. Techniques to improve model robustness or detect and correct prediction errors may be an important area for future work.
More broadly, the success of model-based RL approaches like SimPLe raises interesting questions about the role of world models in intelligence. If humans truly do learn by developing predictive understanding, as the paper suggests, then enhancing AI's capacity for world modeling could be a key path to more human-like learning and reasoning capabilities.
Conclusion
This paper shows how incorporating video prediction models into a reinforcement learning framework can enable agents to solve complex Atari games using far fewer interactions than standard model-free methods. By allowing the agent to simulate and plan based on predicted game dynamics, this "Simulated Policy Learning" approach narrows the gap between human and machine learning efficiency.
While additional research is needed to fully close this gap, the results highlight the potential of model-based RL techniques to develop more sample-efficient and human-like artificial intelligence. As AI systems become more adept at learning about and modeling their environments, we may see them take major strides towards matching and even exceeding human-level performance on a wide range of complex tasks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
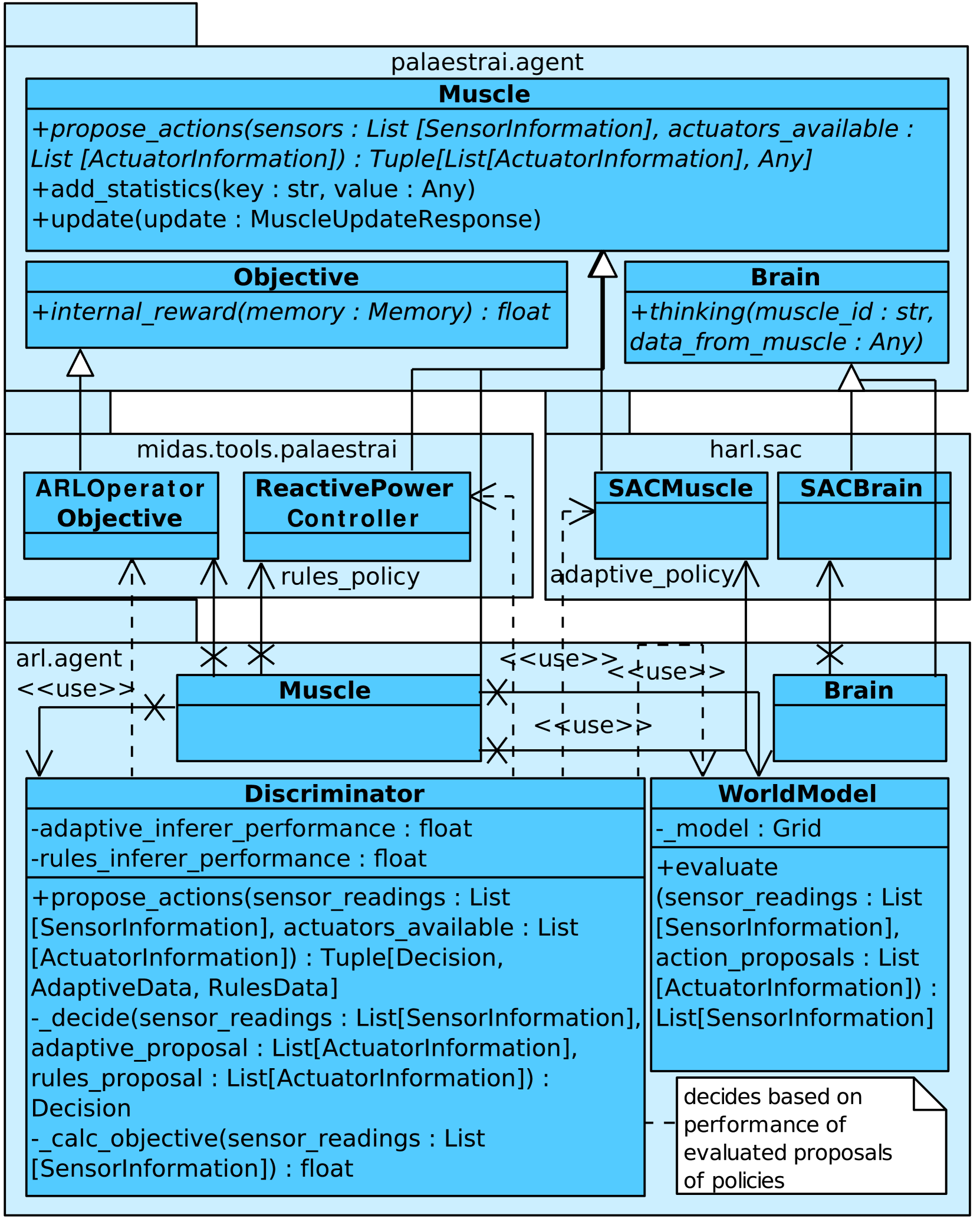
Imitation Game: A Model-based and Imitation Learning Deep Reinforcement Learning Hybrid
Eric MSP Veith, Torben Logemann, Aleksandr Berezin, Arlena Well{ss}ow, Stephan Balduin
0
0
Autonomous and learning systems based on Deep Reinforcement Learning have firmly established themselves as a foundation for approaches to creating resilient and efficient Cyber-Physical Energy Systems. However, most current approaches suffer from two distinct problems: Modern model-free algorithms such as Soft Actor Critic need a high number of samples to learn a meaningful policy, as well as a fallback to ward against concept drifts (e. g., catastrophic forgetting). In this paper, we present the work in progress towards a hybrid agent architecture that combines model-based Deep Reinforcement Learning with imitation learning to overcome both problems.
4/3/2024
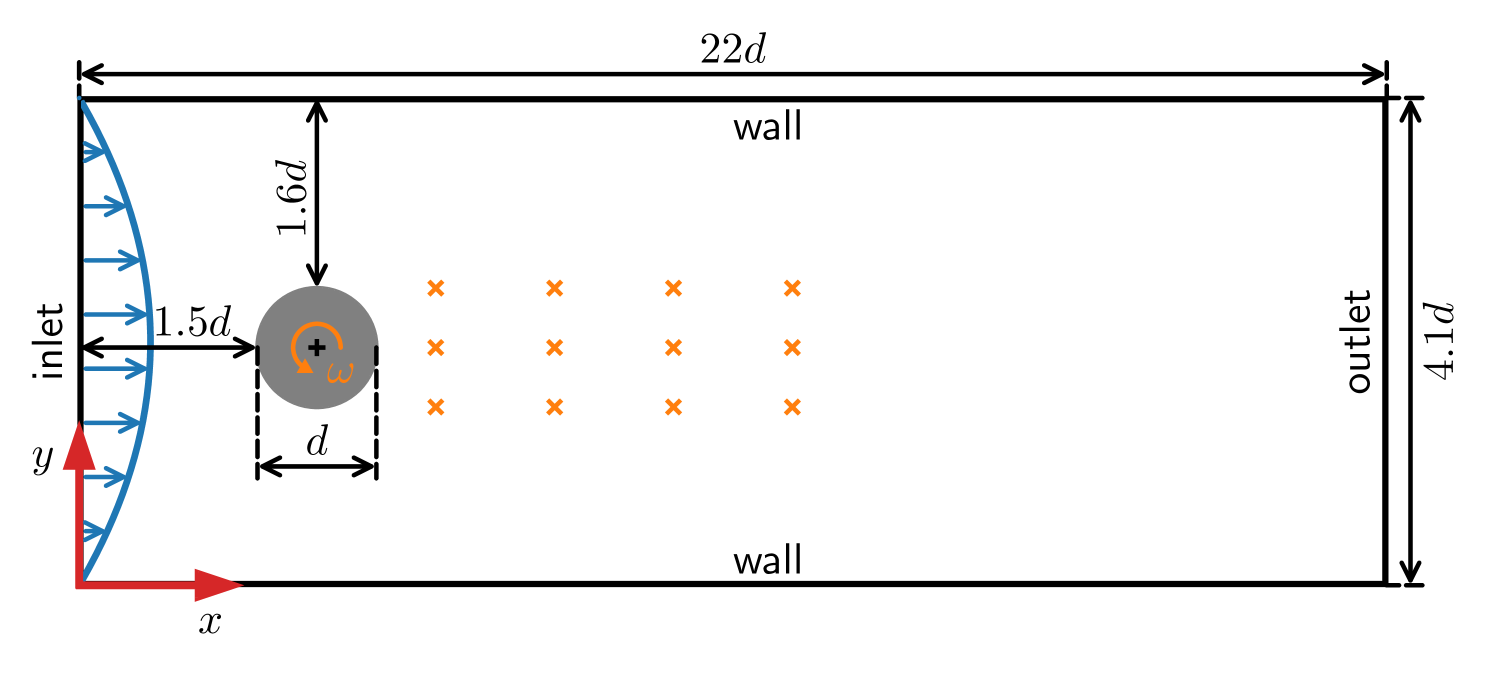
Model-based deep reinforcement learning for accelerated learning from flow simulations
Andre Weiner, Janis Geise
0
0
In recent years, deep reinforcement learning has emerged as a technique to solve closed-loop flow control problems. Employing simulation-based environments in reinforcement learning enables a priori end-to-end optimization of the control system, provides a virtual testbed for safety-critical control applications, and allows to gain a deep understanding of the control mechanisms. While reinforcement learning has been applied successfully in a number of rather simple flow control benchmarks, a major bottleneck toward real-world applications is the high computational cost and turnaround time of flow simulations. In this contribution, we demonstrate the benefits of model-based reinforcement learning for flow control applications. Specifically, we optimize the policy by alternating between trajectories sampled from flow simulations and trajectories sampled from an ensemble of environment models. The model-based learning reduces the overall training time by up to $85%$ for the fluidic pinball test case. Even larger savings are expected for more demanding flow simulations.
4/11/2024
💬
Large Language Models as Generalizable Policies for Embodied Tasks
Andrew Szot, Max Schwarzer, Harsh Agrawal, Bogdan Mazoure, Walter Talbott, Katherine Metcalf, Natalie Mackraz, Devon Hjelm, Alexander Toshev
0
0
We show that large language models (LLMs) can be adapted to be generalizable policies for embodied visual tasks. Our approach, called Large LAnguage model Reinforcement Learning Policy (LLaRP), adapts a pre-trained frozen LLM to take as input text instructions and visual egocentric observations and output actions directly in the environment. Using reinforcement learning, we train LLaRP to see and act solely through environmental interactions. We show that LLaRP is robust to complex paraphrasings of task instructions and can generalize to new tasks that require novel optimal behavior. In particular, on 1,000 unseen tasks it achieves 42% success rate, 1.7x the success rate of other common learned baselines or zero-shot applications of LLMs. Finally, to aid the community in studying language conditioned, massively multi-task, embodied AI problems we release a novel benchmark, Language Rearrangement, consisting of 150,000 training and 1,000 testing tasks for language-conditioned rearrangement. Video examples of LLaRP in unseen Language Rearrangement instructions are at https://llm-rl.github.io.
4/17/2024
🏅
Reducing Risk for Assistive Reinforcement Learning Policies with Diffusion Models
Andrii Tytarenko
0
0
Care-giving and assistive robotics, driven by advancements in AI, offer promising solutions to meet the growing demand for care, particularly in the context of increasing numbers of individuals requiring assistance. This creates a pressing need for efficient and safe assistive devices, particularly in light of heightened demand due to war-related injuries. While cost has been a barrier to accessibility, technological progress is able to democratize these solutions. Safety remains a paramount concern, especially given the intricate interactions between assistive robots and humans. This study explores the application of reinforcement learning (RL) and imitation learning, in improving policy design for assistive robots. The proposed approach makes the risky policies safer without additional environmental interactions. Through experimentation using simulated environments, the enhancement of the conventional RL approaches in tasks related to assistive robotics is demonstrated.
5/14/2024