LLaVA-Gemma: Accelerating Multimodal Foundation Models with a Compact Language Model
2404.01331
0
0
Abstract
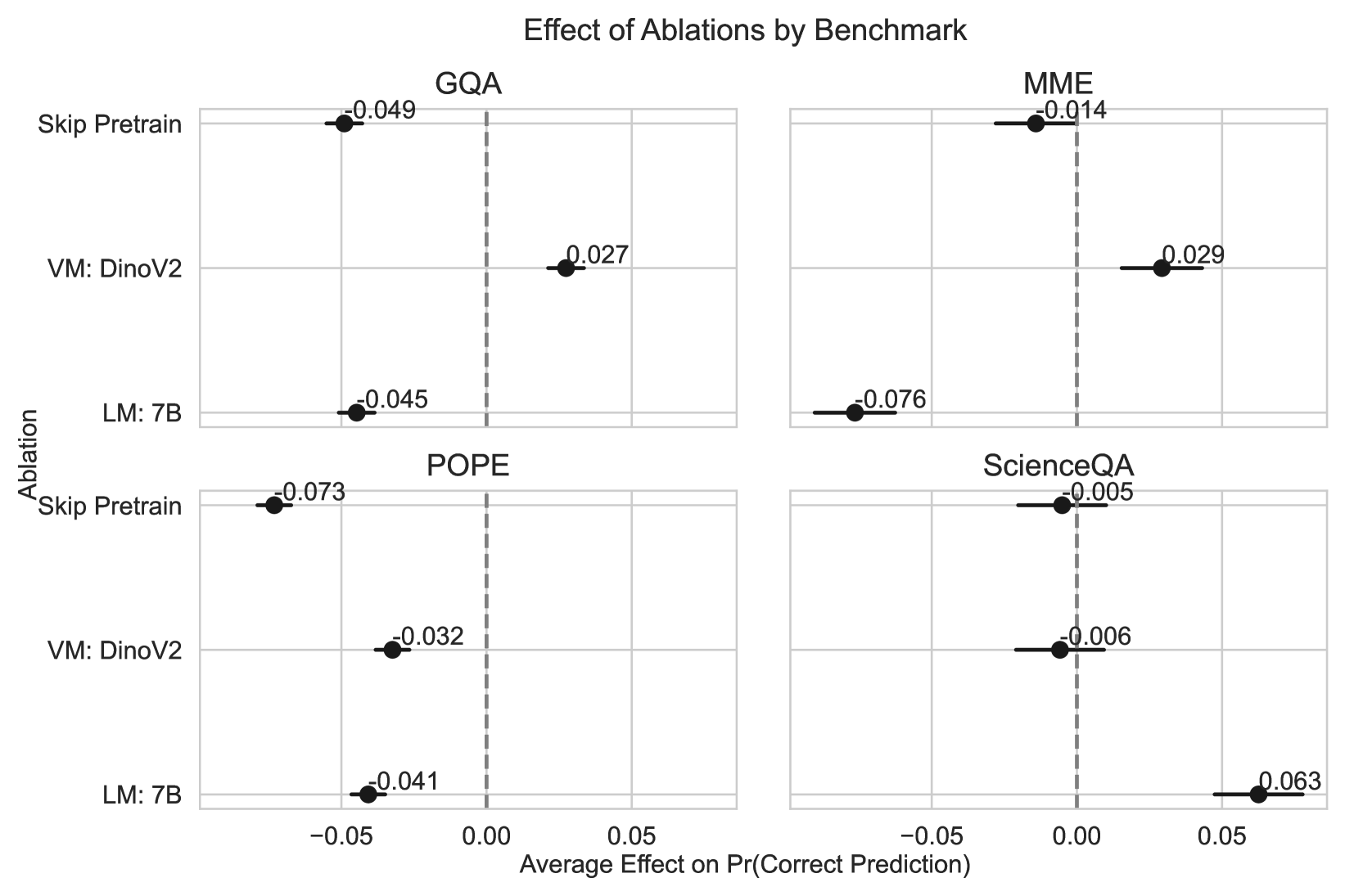
We train a suite of multimodal foundation models (MMFM) using the popular LLaVA framework with the recently released Gemma family of large language models (LLMs). Of particular interest is the 2B parameter Gemma model, which provides opportunities to construct capable small-scale MMFMs. In line with findings from other papers in this space, we test the effect of ablating three design features: pretraining the connector, utilizing a more powerful image backbone, and increasing the size of the language backbone. The resulting models, which we call LLaVA-Gemma, exhibit moderate performance on an array of evaluations, but fail to improve past the current comparably sized SOTA models. Closer analysis of performance shows mixed effects; skipping pretraining tends to reduce performance, larger vision models sometimes improve performance, and increasing language model size has inconsistent effects. We publicly release training recipes, code and weights for our models for the LLaVA-Gemma models.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper presents LLaVA-Gemma, a new approach to accelerating multimodal foundation models by using a compact language model.
- Multimodal foundation models leverage both text and visual data, but can be computationally expensive.
- LLaVA-Gemma aims to improve the efficiency of these models by combining a compact language model with a pre-trained vision model.
Plain English Explanation
Multimodal foundation models are a type of AI system that can understand and process both text and visual information. These models are powerful, but can also be very computationally intensive, requiring a lot of computing power to run.
The researchers behind LLaVA-Gemma wanted to find a way to make these multimodal models more efficient and faster, without sacrificing their capabilities. Their solution was to create a specialized language model - a part of the system that processes the text data - that is more compact and requires less computing power than typical language models.
By pairing this efficient language model with a pre-trained vision model - the part that processes the visual data - the researchers were able to maintain the performance of the overall multimodal system while significantly reducing the computational resources needed to run it. This makes multimodal AI models more accessible and practical for a wider range of applications.
Technical Explanation
The key innovation in LLaVA-Gemma is the use of a compact language model, dubbed "Gemma", that is trained alongside a pre-trained vision model. The Gemma language model has a much smaller parameter count compared to large language models like GPT-3, allowing it to run more efficiently.
To train Gemma, the researchers used a novel pre-training objective that encourages the language model to learn representations that are well-aligned with the pre-trained visual model. This helps the two modalities - text and vision - to work seamlessly together in the final multimodal system.
The researchers evaluated LLaVA-Gemma on a range of multimodal benchmarks, including visual question answering and image-text retrieval tasks. They found that LLaVA-Gemma was able to match or even outperform larger, more computationally-intensive multimodal models, while using a fraction of the computational resources.
Critical Analysis
The authors acknowledge that LLaVA-Gemma, like any model, has limitations. For example, the compact language model may not be able to match the full expressiveness and language understanding capabilities of larger models in certain tasks. Additionally, the authors note that the model's performance could potentially be further improved by exploring more advanced multimodal fusion techniques.
That said, the core idea of combining a compact language model with a pre-trained vision model is a promising direction for making multimodal AI systems more efficient and accessible. As the authors point out, this could have important implications for deploying powerful multimodal models in real-world applications with limited computing resources.
Overall, LLaVA-Gemma represents an interesting and valuable contribution to the field of efficient multimodal AI, and the researchers have provided a solid foundation for further exploration and refinement of this approach.
Conclusion
LLaVA-Gemma demonstrates that it is possible to create highly efficient multimodal foundation models by using a compact language model paired with a pre-trained vision model. This advance could make powerful multimodal AI systems more widely accessible, with applications in areas like image understanding, visual question answering, and beyond. While the model has some limitations, the core ideas behind LLaVA-Gemma represent an important step forward in making multimodal AI more practical and scalable.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
MEGAVERSE: Benchmarking Large Language Models Across Languages, Modalities, Models and Tasks
Sanchit Ahuja, Divyanshu Aggarwal, Varun Gumma, Ishaan Watts, Ashutosh Sathe, Millicent Ochieng, Rishav Hada, Prachi Jain, Maxamed Axmed, Kalika Bali, Sunayana Sitaram
0
0
There has been a surge in LLM evaluation research to understand LLM capabilities and limitations. However, much of this research has been confined to English, leaving LLM building and evaluation for non-English languages relatively unexplored. Several new LLMs have been introduced recently, necessitating their evaluation on non-English languages. This study aims to perform a thorough evaluation of the non-English capabilities of SoTA LLMs (GPT-3.5-Turbo, GPT-4, PaLM2, Gemini-Pro, Mistral, Llama2, and Gemma) by comparing them on the same set of multilingual datasets. Our benchmark comprises 22 datasets covering 83 languages, including low-resource African languages. We also include two multimodal datasets in the benchmark and compare the performance of LLaVA models, GPT-4-Vision and Gemini-Pro-Vision. Our experiments show that larger models such as GPT-4, Gemini-Pro and PaLM2 outperform smaller models on various tasks, notably on low-resource languages, with GPT-4 outperforming PaLM2 and Gemini-Pro on more datasets. We also perform a study on data contamination and find that several models are likely to be contaminated with multilingual evaluation benchmarks, necessitating approaches to detect and handle contamination while assessing the multilingual performance of LLMs.
4/4/2024
❗
Enabling High-Sparsity Foundational Llama Models with Efficient Pretraining and Deployment
Abhinav Agarwalla, Abhay Gupta, Alexandre Marques, Shubhra Pandit, Michael Goin, Eldar Kurtic, Kevin Leong, Tuan Nguyen, Mahmoud Salem, Dan Alistarh, Sean Lie, Mark Kurtz
0
0
Large language models (LLMs) have revolutionized Natural Language Processing (NLP), but their size creates computational bottlenecks. We introduce a novel approach to create accurate, sparse foundational versions of performant LLMs that achieve full accuracy recovery for fine-tuning tasks at up to 70% sparsity. We achieve this for the LLaMA-2 7B model by combining the SparseGPT one-shot pruning method and sparse pretraining of those models on a subset of the SlimPajama dataset mixed with a Python subset of The Stack dataset. We exhibit training acceleration due to sparsity on Cerebras CS-3 chips that closely matches theoretical scaling. In addition, we establish inference acceleration of up to 3x on CPUs by utilizing Neural Magic's DeepSparse engine and 1.7x on GPUs through Neural Magic's nm-vllm engine. The above gains are realized via sparsity alone, thus enabling further gains through additional use of quantization. Specifically, we show a total speedup on CPUs for sparse-quantized LLaMA models of up to 8.6x. We demonstrate these results across diverse, challenging tasks, including chat, instruction following, code generation, arithmetic reasoning, and summarization to prove their generality. This work paves the way for rapidly creating smaller and faster LLMs without sacrificing accuracy.
5/7/2024
💬
Large Language Models for Expansion of Spoken Language Understanding Systems to New Languages
Jakub Hoscilowicz, Pawel Pawlowski, Marcin Skorupa, Marcin Sowa'nski, Artur Janicki
0
0
Spoken Language Understanding (SLU) models are a core component of voice assistants (VA), such as Alexa, Bixby, and Google Assistant. In this paper, we introduce a pipeline designed to extend SLU systems to new languages, utilizing Large Language Models (LLMs) that we fine-tune for machine translation of slot-annotated SLU training data. Our approach improved on the MultiATIS++ benchmark, a primary multi-language SLU dataset, in the cloud scenario using an mBERT model. Specifically, we saw an improvement in the Overall Accuracy metric: from 53% to 62.18%, compared to the existing state-of-the-art method, Fine and Coarse-grained Multi-Task Learning Framework (FC-MTLF). In the on-device scenario (tiny and not pretrained SLU), our method improved the Overall Accuracy from 5.31% to 22.06% over the baseline Global-Local Contrastive Learning Framework (GL-CLeF) method. Contrary to both FC-MTLF and GL-CLeF, our LLM-based machine translation does not require changes in the production architecture of SLU. Additionally, our pipeline is slot-type independent: it does not require any slot definitions or examples.
4/4/2024
🤔
MM1: Methods, Analysis & Insights from Multimodal LLM Pre-training
Brandon McKinzie, Zhe Gan, Jean-Philippe Fauconnier, Sam Dodge, Bowen Zhang, Philipp Dufter, Dhruti Shah, Xianzhi Du, Futang Peng, Floris Weers, Anton Belyi, Haotian Zhang, Karanjeet Singh, Doug Kang, Ankur Jain, Hongyu H`e, Max Schwarzer, Tom Gunter, Xiang Kong, Aonan Zhang, Jianyu Wang, Chong Wang, Nan Du, Tao Lei, Sam Wiseman, Guoli Yin, Mark Lee, Zirui Wang, Ruoming Pang, Peter Grasch, Alexander Toshev, Yinfei Yang
0
0
In this work, we discuss building performant Multimodal Large Language Models (MLLMs). In particular, we study the importance of various architecture components and data choices. Through careful and comprehensive ablations of the image encoder, the vision language connector, and various pre-training data choices, we identified several crucial design lessons. For example, we demonstrate that for large-scale multimodal pre-training using a careful mix of image-caption, interleaved image-text, and text-only data is crucial for achieving state-of-the-art (SOTA) few-shot results across multiple benchmarks, compared to other published pre-training results. Further, we show that the image encoder together with image resolution and the image token count has substantial impact, while the vision-language connector design is of comparatively negligible importance. By scaling up the presented recipe, we build MM1, a family of multimodal models up to 30B parameters, including both dense models and mixture-of-experts (MoE) variants, that are SOTA in pre-training metrics and achieve competitive performance after supervised fine-tuning on a range of established multimodal benchmarks. Thanks to large-scale pre-training, MM1 enjoys appealing properties such as enhanced in-context learning, and multi-image reasoning, enabling few-shot chain-of-thought prompting.
4/22/2024