Bagging Improves Generalization Exponentially

0
🎲
Sign in to get full access
Overview
- Bagging is an ensemble technique that can improve the accuracy of machine learning models.
- The paper proposes a new perspective on bagging, showing that it can improve generalization performance exponentially by aggregating the base learners at the parametrization level, rather than just reducing variance.
- The paper demonstrates how bagging can substantially improve generalization in scenarios with heavy-tailed data that suffer from slow learning rates.
Plain English Explanation
Bagging is a technique that can help make machine learning models more accurate. The basic idea is to train the same model multiple times on slightly different versions of the training data, and then combine the results of those models to make a single, more reliable prediction.
The new perspective presented in this paper is that bagging doesn't just reduce the variance (or "noise") in the model's predictions, which is the typical explanation. Instead, the paper shows that by combining the models at a deeper level - the parameters of the models themselves - bagging can actually improve the model's ability to generalize to new data exponentially. This is a much more powerful effect than just reducing variance.
The researchers demonstrate how this exponential improvement in generalization can be especially helpful in situations where the data has "heavy tails" - meaning there are a lot of outliers or extreme values. In these cases, the model typically learns slowly, but bagging can dramatically speed up the learning process and lead to much better performance.
Technical Explanation
The paper provides a new theoretical understanding of how bagging works. Rather than just reducing the variance of the base models, as is commonly assumed, the authors show that bagging can actually improve the models' generalization performance exponentially.
This powerful effect comes from aggregating the base learners at the parametrization level, rather than just combining their outputs. The authors prove that for a broad class of stochastic optimization problems, bagging can reduce the generalization error from a slow, polynomial decay to an exponential decay.
Furthermore, this exponential improvement in generalization is independent of the specific solution scheme used, whether it's empirical risk minimization, distributionally robust optimization, or various regularization techniques.
The paper demonstrates the practical impact of this new understanding by showing how bagging can substantially improve generalization on datasets with heavy-tailed distributions - a common scenario where models typically learn slowly. By leveraging the exponential improvement provided by bagging, the models are able to achieve much better performance.
Critical Analysis
The paper presents a compelling new perspective on bagging and rigorously proves its theoretical advantages. However, the authors acknowledge that there are some limitations to their analysis. For example, they assume the base learners are already well-trained, and don't consider the effects of bagging on the training process itself.
Additionally, while the paper demonstrates the benefits of bagging on heavy-tailed datasets, it would be interesting to see how the method performs on a wider range of data distributions and problem types. The theoretical guarantees provided in the paper are quite general, but more empirical validation across diverse scenarios would further strengthen the case for this new understanding of bagging.
Overall, this research provides a valuable contribution to the field by shedding new light on the mechanisms underlying one of the most widely used ensemble techniques in machine learning. The exponential improvement in generalization is a significant finding that warrants further exploration and application in real-world settings.
Conclusion
This paper presents a novel perspective on the bagging ensemble technique, showing that it can improve generalization performance exponentially by aggregating the base learners at the parametrization level. This is a much more powerful effect than the typical explanation of just reducing the variance in the models' predictions.
The researchers demonstrate how this exponential improvement in generalization can be particularly beneficial in scenarios with heavy-tailed data, where models typically learn slowly. By leveraging bagging's ability to accelerate learning, the models are able to achieve substantially better performance in these challenging settings.
While the paper provides a strong theoretical foundation for this new understanding of bagging, further empirical validation across a wider range of data and problem types would help solidify its practical significance. Nonetheless, this research represents an important advancement in our knowledge of one of the most widely used ensemble methods in machine learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🎲
0
Bagging Improves Generalization Exponentially
Huajie Qian, Donghao Ying, Henry Lam, Wotao Yin
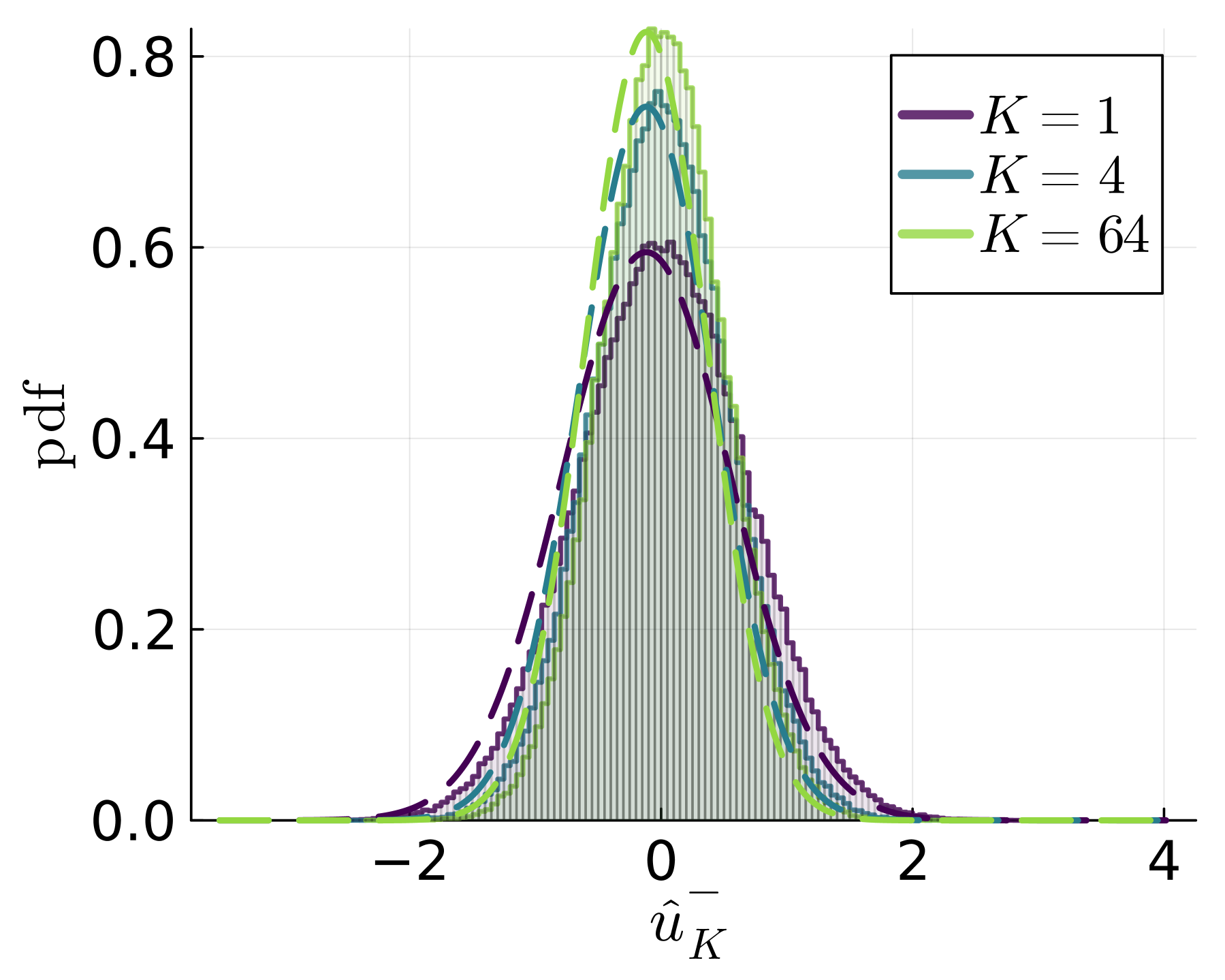
Bagging is a popular ensemble technique to improve the accuracy of machine learning models. It hinges on the well-established rationale that, by repeatedly retraining on resampled data, the aggregated model exhibits lower variance and hence higher stability, especially for discontinuous base learners. In this paper, we provide a new perspective on bagging: By suitably aggregating the base learners at the parametrization instead of the output level, bagging improves generalization performances exponentially, a strength that is significantly more powerful than variance reduction. More precisely, we show that for general stochastic optimization problems that suffer from slowly (i.e., polynomially) decaying generalization errors, bagging can effectively reduce these errors to an exponential decay. Moreover, this power of bagging is agnostic to the solution schemes, including common empirical risk minimization, distributionally robust optimization, and various regularizations. We demonstrate how bagging can substantially improve generalization performances in a range of examples involving heavy-tailed data that suffer from intrinsically slow rates.
Read more5/30/2024
🎲
0
Bagging Provides Assumption-free Stability
Jake A. Soloff, Rina Foygel Barber, Rebecca Willett
Bagging is an important technique for stabilizing machine learning models. In this paper, we derive a finite-sample guarantee on the stability of bagging for any model. Our result places no assumptions on the distribution of the data, on the properties of the base algorithm, or on the dimensionality of the covariates. Our guarantee applies to many variants of bagging and is optimal up to a constant. Empirical results validate our findings, showing that bagging successfully stabilizes even highly unstable base algorithms.
Read more4/26/2024

0
A naive aggregation algorithm for improving generalization in a class of learning problems
Getachew K Befekadu
In this brief paper, we present a naive aggregation algorithm for a typical learning problem with expert advice setting, in which the task of improving generalization, i.e., model validation, is embedded in the learning process as a sequential decision-making problem. In particular, we consider a class of learning problem of point estimations for modeling high-dimensional nonlinear functions, where a group of experts update their parameter estimates using the discrete-time version of gradient systems, with small additive noise term, guided by the corresponding subsample datasets obtained from the original dataset. Here, our main objective is to provide conditions under which such an algorithm will sequentially determine a set of mixing distribution strategies used for aggregating the experts' estimates that ultimately leading to an optimal parameter estimate, i.e., as a consensus solution for all experts, which is better than any individual expert's estimate in terms of improved generalization or learning performances. Finally, as part of this work, we present some numerical results for a typical case of nonlinear regression problem.
Read more9/9/2024
0
A replica analysis of under-bagging
Takashi Takahashi
Under-bagging (UB), which combines under-sampling and bagging, is a popular ensemble learning method for training classifiers on an imbalanced data. Using bagging to reduce the increased variance caused by the reduction in sample size due to under-sampling is a natural approach. However, it has recently been pointed out that in generalized linear models, naive bagging, which does not consider the class imbalance structure, and ridge regularization can produce the same results. Therefore, it is not obvious whether it is better to use UB, which requires an increased computational cost proportional to the number of under-sampled data sets, when training linear models. Given such a situation, in this study, we heuristically derive a sharp asymptotics of UB and use it to compare with several other popular methods for learning from imbalanced data, in the scenario where a linear classifier is trained from a two-component mixture data. The methods compared include the under-sampling (US) method, which trains a model using a single realization of the under-sampled data, and the simple weighting (SW) method, which trains a model with a weighted loss on the entire data. It is shown that the performance of UB is improved by increasing the size of the majority class while keeping the size of the minority fixed, even though the class imbalance can be large, especially when the size of the minority class is small. This is in contrast to US, whose performance is almost independent of the majority class size. In this sense, bagging and simple regularization differ as methods to reduce the variance increased by under-sampling. On the other hand, the performance of SW with the optimal weighting coefficients is almost equal to UB, indicating that the combination of reweighting and regularization may be similar to UB.
Read more7/17/2024