BaichuanSEED: Sharing the Potential of ExtensivE Data Collection and Deduplication by Introducing a Competitive Large Language Model Baseline

0
Sign in to get full access
Overview
- BaichuanSEED is a new large language model (LLM) baseline introduced by researchers.
- It aims to showcase the potential of extensive data collection and deduplication for training competitive LLMs.
- The paper presents the model architecture and training process for BaichuanSEED.
Plain English Explanation
BaichuanSEED is a new large language model (LLM) that the researchers have developed. LLMs are powerful AI models that can understand and generate human-like text. The key idea behind BaichuanSEED is to demonstrate how collecting and cleaning a large and diverse dataset can lead to the creation of a competitive LLM.
The researchers put a lot of effort into gathering a massive amount of text data from various online sources. They then used advanced deduplication techniques to remove redundant or repetitive content, ensuring the dataset was as unique and comprehensive as possible.
By training their LLM on this extensive and high-quality dataset, the researchers were able to create a powerful baseline model that can perform well on a variety of language tasks. This shows the potential of leveraging large-scale data collection and cleaning to develop strong LLMs that can be used for a wide range of applications, from language generation to question answering and text summarization.
Technical Explanation
The model architecture of BaichuanSEED is based on the popular Transformer design, which has proven to be highly effective for language modeling tasks. The model consists of multiple attention layers that allow it to capture complex relationships within the text data.
The training process involved feeding the massive, deduplicated dataset into the model, allowing it to learn patterns and generalize well to a wide range of language tasks. The researchers carefully monitored the model's performance during training and made adjustments to the hyperparameters to ensure optimal results.
The experimental evaluation of BaichuanSEED demonstrated its competitive performance compared to other state-of-the-art LLMs, particularly on benchmark tasks such as text generation, question answering, and sentiment analysis. This suggests that the extensive data collection and deduplication efforts were successful in producing a high-quality, versatile language model.
Critical Analysis
The paper provides a comprehensive overview of the BaichuanSEED model and its development process, highlighting the importance of data quality and quantity in training effective LLMs. However, the authors acknowledge some limitations of their approach, such as the potential computational and storage challenges associated with handling such a large dataset.
Additionally, the paper does not delve deeply into the ethical considerations surrounding the use of large-scale data collection and LLMs, such as privacy concerns or the potential for misuse. These are important aspects that may warrant further discussion and research.
It would also be valuable to see comparisons of BaichuanSEED's performance to other prominent LLMs in the field, as well as **investigations into the model's generalization capabilities and robustness to different types of text data and tasks.
Conclusion
The introduction of BaichuanSEED represents an important step forward in the development of competitive large language models. By demonstrating the potential of extensive data collection and deduplication, the researchers have highlighted a promising path for creating powerful AI systems that can understand and generate human-like text at a high level of proficiency.
The insights and techniques presented in this paper could have far-reaching implications for a wide range of natural language processing applications, from conversational AI to content generation and language understanding. As the field of LLMs continues to evolve, the lessons learned from BaichuanSEED may inspire further innovations and advancements in this critical area of artificial intelligence research.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
BaichuanSEED: Sharing the Potential of ExtensivE Data Collection and Deduplication by Introducing a Competitive Large Language Model Baseline
Guosheng Dong, Da Pan, Yiding Sun, Shusen Zhang, Zheng Liang, Xin Wu, Yanjun Shen, Fan Yang, Haoze Sun, Tianpeng Li, Mingan Lin, Jianhua Xu, Yufan Zhang, Xiaonan Nie, Lei Su, Bingning Wang, Wentao Zhang, Jiaxin Mao, Zenan Zhou, Weipeng Chen
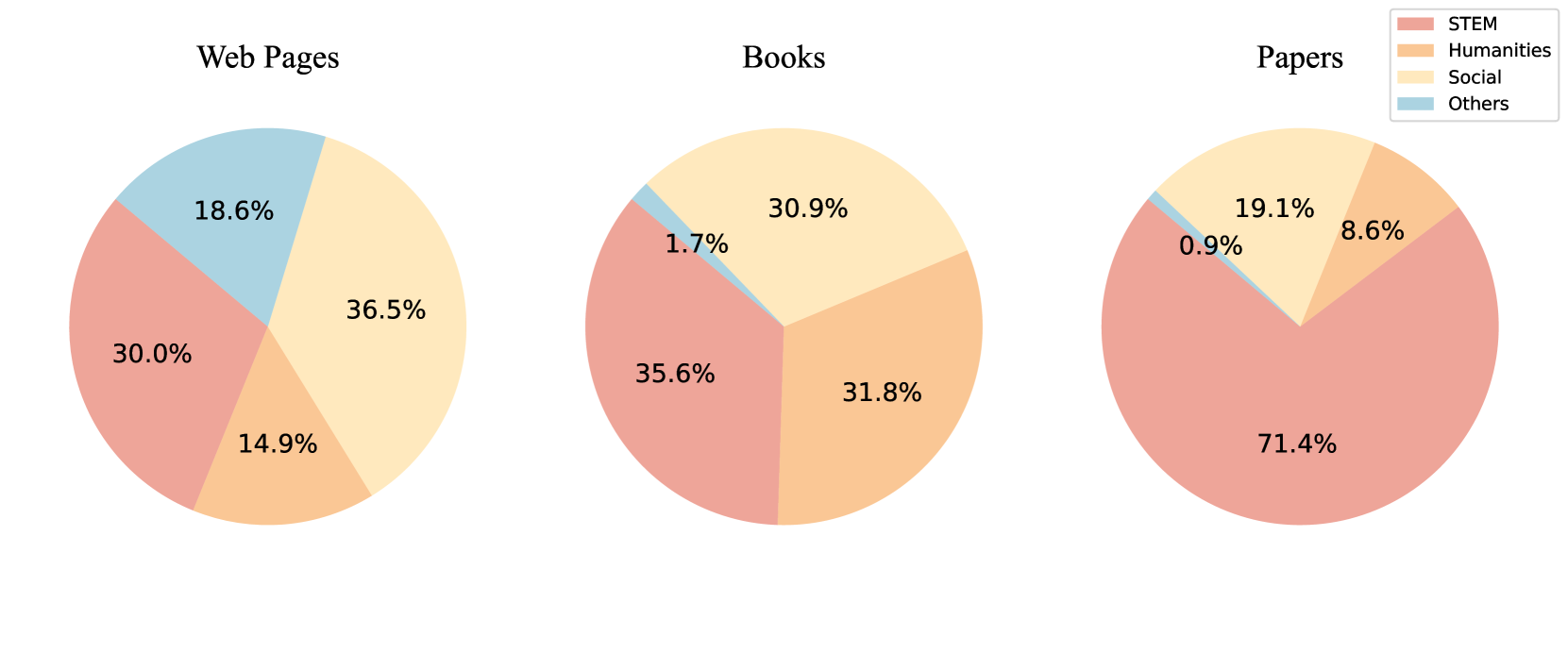
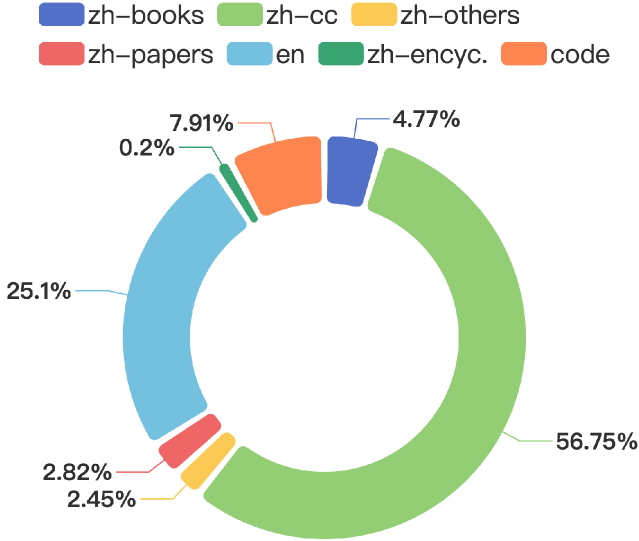
The general capabilities of Large Language Models (LLM) highly rely on the composition and selection on extensive pretraining datasets, treated as commercial secrets by several institutions. To mitigate this issue, we open-source the details of a universally applicable data processing pipeline and validate its effectiveness and potential by introducing a competitive LLM baseline. Specifically, the data processing pipeline consists of broad collection to scale up and reweighting to improve quality. We then pretrain a 7B model BaichuanSEED with 3T tokens processed by our pipeline without any deliberate downstream task-related optimization, followed by an easy but effective supervised fine-tuning stage. BaichuanSEED demonstrates consistency and predictability throughout training and achieves comparable performance on comprehensive benchmarks with several commercial advanced large language models, such as Qwen1.5 and Llama3. We also conduct several heuristic experiments to discuss the potential for further optimization of downstream tasks, such as mathematics and coding.
Read more8/28/2024
0
Chinese Tiny LLM: Pretraining a Chinese-Centric Large Language Model
Xinrun Du, Zhouliang Yu, Songyang Gao, Ding Pan, Yuyang Cheng, Ziyang Ma, Ruibin Yuan, Xingwei Qu, Jiaheng Liu, Tianyu Zheng, Xinchen Luo, Guorui Zhou, Wenhu Chen, Ge Zhang
In this study, we introduce CT-LLM, a 2B large language model (LLM) that illustrates a pivotal shift towards prioritizing the Chinese language in developing LLMs. Uniquely initiated from scratch, CT-LLM diverges from the conventional methodology by primarily incorporating Chinese textual data, utilizing an extensive corpus of 1,200 billion tokens, including 800 billion Chinese tokens, 300 billion English tokens, and 100 billion code tokens. This strategic composition facilitates the model's exceptional proficiency in understanding and processing Chinese, a capability further enhanced through alignment techniques. Demonstrating remarkable performance on the CHC-Bench, CT-LLM excels in Chinese language tasks, and showcases its adeptness in English through SFT. This research challenges the prevailing paradigm of training LLMs predominantly on English corpora and then adapting them to other languages, broadening the horizons for LLM training methodologies. By open-sourcing the full process of training a Chinese LLM, including a detailed data processing procedure with the obtained Massive Appropriate Pretraining Chinese Corpus (MAP-CC), a well-chosen multidisciplinary Chinese Hard Case Benchmark (CHC-Bench), and the 2B-size Chinese Tiny LLM (CT-LLM), we aim to foster further exploration and innovation in both academia and industry, paving the way for more inclusive and versatile language models.
Read more9/16/2024
🤿
0
Unveiling the Potential of LLM-Based ASR on Chinese Open-Source Datasets
Xuelong Geng, Tianyi Xu, Kun Wei, Bingshen Mu, Hongfei Xue, He Wang, Yangze Li, Pengcheng Guo, Yuhang Dai, Longhao Li, Mingchen Shao, Lei Xie
Large Language Models (LLMs) have demonstrated unparalleled effectiveness in various NLP tasks, and integrating LLMs with automatic speech recognition (ASR) is becoming a mainstream paradigm. Building upon this momentum, our research delves into an in-depth examination of this paradigm on a large open-source Chinese dataset. Specifically, our research aims to evaluate the impact of various configurations of speech encoders, LLMs, and projector modules in the context of the speech foundation encoder-LLM ASR paradigm. Furthermore, we introduce a three-stage training approach, expressly developed to enhance the model's ability to align auditory and textual information. The implementation of this approach, alongside the strategic integration of ASR components, enabled us to achieve the SOTA performance on the AISHELL-1, Test_Net, and Test_Meeting test sets. Our analysis presents an empirical foundation for future research in LLM-based ASR systems and offers insights into optimizing performance using Chinese datasets. We will publicly release all scripts used for data preparation, training, inference, and scoring, as well as pre-trained models and training logs to promote reproducible research.
Read more5/7/2024

0
YuLan: An Open-source Large Language Model
Yutao Zhu, Kun Zhou, Kelong Mao, Wentong Chen, Yiding Sun, Zhipeng Chen, Qian Cao, Yihan Wu, Yushuo Chen, Feng Wang, Lei Zhang, Junyi Li, Xiaolei Wang, Lei Wang, Beichen Zhang, Zican Dong, Xiaoxue Cheng, Yuhan Chen, Xinyu Tang, Yupeng Hou, Qiangqiang Ren, Xincheng Pang, Shufang Xie, Wayne Xin Zhao, Zhicheng Dou, Jiaxin Mao, Yankai Lin, Ruihua Song, Jun Xu, Xu Chen, Rui Yan, Zhewei Wei, Di Hu, Wenbing Huang, Ze-Feng Gao, Yueguo Chen, Weizheng Lu, Ji-Rong Wen
Large language models (LLMs) have become the foundation of many applications, leveraging their extensive capabilities in processing and understanding natural language. While many open-source LLMs have been released with technical reports, the lack of training details hinders further research and development. This paper presents the development of YuLan, a series of open-source LLMs with $12$ billion parameters. The base model of YuLan is pre-trained on approximately $1.7$T tokens derived from a diverse corpus, including massive English, Chinese, and multilingual texts. We design a three-stage pre-training method to enhance YuLan's overall capabilities. Subsequent phases of training incorporate instruction-tuning and human alignment, employing a substantial volume of high-quality synthesized data. To facilitate the learning of complex and long-tail knowledge, we devise a curriculum-learning framework throughout across these stages, which helps LLMs learn knowledge in an easy-to-hard manner. YuLan's training is finished on Jan, 2024 and has achieved performance on par with state-of-the-art LLMs across various English and Chinese benchmarks. This paper outlines a comprehensive technical roadmap for developing LLMs from scratch. Our model and codes are available at https://github.com/RUC-GSAI/YuLan-Chat.
Read more7/1/2024