Latent-based Diffusion Model for Long-tailed Recognition
2404.04517
0
0

Abstract
Long-tailed imbalance distribution is a common issue in practical computer vision applications. Previous works proposed methods to address this problem, which can be categorized into several classes: re-sampling, re-weighting, transfer learning, and feature augmentation. In recent years, diffusion models have shown an impressive generation ability in many sub-problems of deep computer vision. However, its powerful generation has not been explored in long-tailed problems. We propose a new approach, the Latent-based Diffusion Model for Long-tailed Recognition (LDMLR), as a feature augmentation method to tackle the issue. First, we encode the imbalanced dataset into features using the baseline model. Then, we train a Denoising Diffusion Implicit Model (DDIM) using these encoded features to generate pseudo-features. Finally, we train the classifier using the encoded and pseudo-features from the previous two steps. The model's accuracy shows an improvement on the CIFAR-LT and ImageNet-LT datasets by using the proposed method.
Create account to get full access
Overview
- Introduces a latent-based diffusion model for long-tailed recognition tasks
- Aims to address the challenge of recognizing rare or under-represented classes in large-scale datasets
- Proposes a novel approach that leverages diffusion models to learn a latent space for improved classification performance
Plain English Explanation
The paper presents a new machine learning model called a "latent-based diffusion model" that is designed to improve the ability of AI systems to accurately recognize objects or classes that are relatively rare or under-represented in the training data. This is a common problem known as the "long-tailed" recognition challenge, where AI models tend to perform poorly on less common classes.
The key insight is to use a diffusion model, which is a type of generative AI that can create new synthetic data, to learn a more useful latent (hidden) representation of the data. This latent space captures important features of the data that can then be leveraged by a classifier to better recognize the rare classes. The paper demonstrates how this approach can outperform standard classification models on long-tailed recognition benchmarks.
Technical Explanation
The paper proposes a Latent-based Diffusion Model for Long-tailed Recognition, which aims to address the challenges of long-tailed recognition by learning a latent space representation using a diffusion model. The key components are:
- Diffusion Model: The model learns a latent space representation of the data using a diffusion process, which gradually adds noise to the input data and then learns to reverse this process to generate new samples.
- Latent Classifier: The learned latent space is then used to train a classifier that can better recognize the rare or under-represented classes in the long-tailed dataset.
- Joint Optimization: The diffusion model and latent classifier are jointly optimized to ensure the learned latent space is well-suited for downstream classification.
The authors evaluate their approach on several long-tailed recognition benchmarks, such as DeiT-LT and [LVIS], and show significant improvements over standard classification models.
Critical Analysis
The paper offers a promising approach to addressing the important challenge of long-tailed recognition in machine learning. By leveraging the representation learning capabilities of diffusion models, the authors demonstrate how a more effective latent space can be learned to improve classification performance on rare classes.
However, the paper does not address some potential limitations of this approach. For example, the computational cost and training complexity of the joint optimization of the diffusion model and classifier may be higher compared to simpler classification methods. Additionally, the paper does not explore the robustness of the latent-based diffusion model to distribution shifts or its ability to generalize to new, unseen classes.
Further research could investigate ways to mitigate these potential issues, such as exploring more efficient optimization strategies or investigating the transfer learning capabilities of the learned latent representations. It would also be valuable to see how the latent-based diffusion model compares to other state-of-the-art approaches for long-tailed recognition, such as DELTA or Diffusion-based DeepFake Detection.
Conclusion
The "Latent-based Diffusion Model for Long-tailed Recognition" presents a novel approach to addressing the important challenge of recognizing rare or under-represented classes in large-scale datasets. By leveraging the representation learning capabilities of diffusion models, the authors demonstrate how a more effective latent space can be learned to improve classification performance on long-tailed recognition tasks.
While the paper offers a promising solution, further research is needed to address potential limitations and compare the approach to other state-of-the-art methods. Nonetheless, this work represents an important contribution to the field of machine learning and has the potential to enable more robust and equitable AI systems that can handle the real-world complexities of class imbalance.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Long Tail Image Generation Through Feature Space Augmentation and Iterated Learning
Rafael Elberg, Denis Parra, Mircea Petrache
0
0
Image and multimodal machine learning tasks are very challenging to solve in the case of poorly distributed data. In particular, data availability and privacy restrictions exacerbate these hurdles in the medical domain. The state of the art in image generation quality is held by Latent Diffusion models, making them prime candidates for tackling this problem. However, a few key issues still need to be solved, such as the difficulty in generating data from under-represented classes and a slow inference process. To mitigate these issues, we propose a new method for image augmentation in long-tailed data based on leveraging the rich latent space of pre-trained Stable Diffusion Models. We create a modified separable latent space to mix head and tail class examples. We build this space via Iterated Learning of underlying sparsified embeddings, which we apply to task-specific saliency maps via a K-NN approach. Code is available at https://github.com/SugarFreeManatee/Feature-Space-Augmentation-and-Iterated-Learning
5/6/2024
❗
Long-Tailed Anomaly Detection with Learnable Class Names
Chih-Hui Ho, Kuan-Chuan Peng, Nuno Vasconcelos
0
0
Anomaly detection (AD) aims to identify defective images and localize their defects (if any). Ideally, AD models should be able to detect defects over many image classes; without relying on hard-coded class names that can be uninformative or inconsistent across datasets; learn without anomaly supervision; and be robust to the long-tailed distributions of real-world applications. To address these challenges, we formulate the problem of long-tailed AD by introducing several datasets with different levels of class imbalance and metrics for performance evaluation. We then propose a novel method, LTAD, to detect defects from multiple and long-tailed classes, without relying on dataset class names. LTAD combines AD by reconstruction and semantic AD modules. AD by reconstruction is implemented with a transformer-based reconstruction module. Semantic AD is implemented with a binary classifier, which relies on learned pseudo class names and a pretrained foundation model. These modules are learned over two phases. Phase 1 learns the pseudo-class names and a variational autoencoder (VAE) for feature synthesis that augments the training data to combat long-tails. Phase 2 then learns the parameters of the reconstruction and classification modules of LTAD. Extensive experiments using the proposed long-tailed datasets show that LTAD substantially outperforms the state-of-the-art methods for most forms of dataset imbalance. The long-tailed dataset split is available at https://zenodo.org/records/10854201 .
4/1/2024
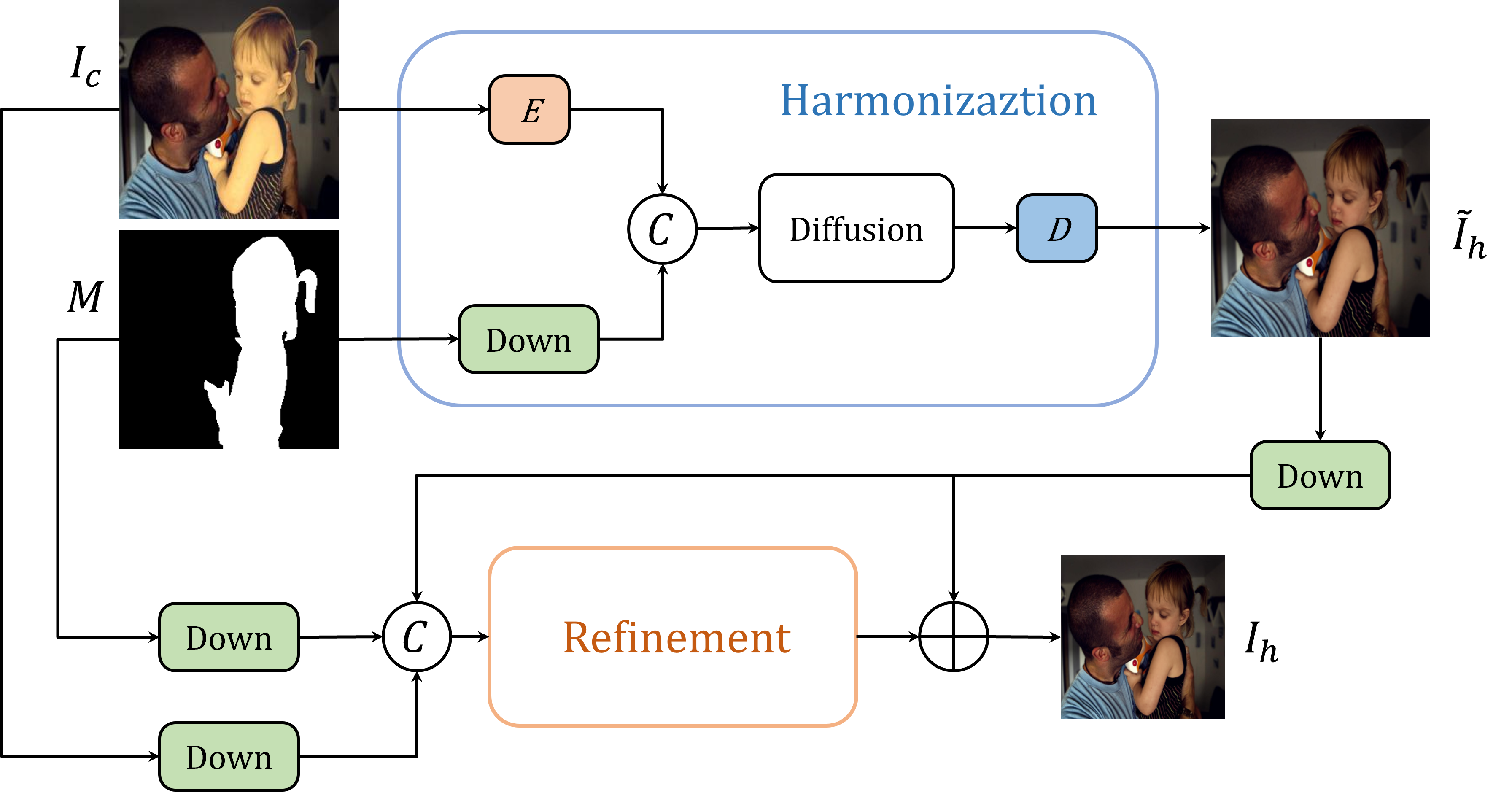
DiffHarmony: Latent Diffusion Model Meets Image Harmonization
Pengfei Zhou, Fangxiang Feng, Xiaojie Wang
0
0
Image harmonization, which involves adjusting the foreground of a composite image to attain a unified visual consistency with the background, can be conceptualized as an image-to-image translation task. Diffusion models have recently promoted the rapid development of image-to-image translation tasks . However, training diffusion models from scratch is computationally intensive. Fine-tuning pre-trained latent diffusion models entails dealing with the reconstruction error induced by the image compression autoencoder, making it unsuitable for image generation tasks that involve pixel-level evaluation metrics. To deal with these issues, in this paper, we first adapt a pre-trained latent diffusion model to the image harmonization task to generate the harmonious but potentially blurry initial images. Then we implement two strategies: utilizing higher-resolution images during inference and incorporating an additional refinement stage, to further enhance the clarity of the initially harmonized images. Extensive experiments on iHarmony4 datasets demonstrate the superiority of our proposed method. The code and model will be made publicly available at https://github.com/nicecv/DiffHarmony .
4/10/2024

DeiT-LT Distillation Strikes Back for Vision Transformer Training on Long-Tailed Datasets
Harsh Rangwani, Pradipto Mondal, Mayank Mishra, Ashish Ramayee Asokan, R. Venkatesh Babu
0
0
Vision Transformer (ViT) has emerged as a prominent architecture for various computer vision tasks. In ViT, we divide the input image into patch tokens and process them through a stack of self attention blocks. However, unlike Convolutional Neural Networks (CNN), ViTs simple architecture has no informative inductive bias (e.g., locality,etc. ). Due to this, ViT requires a large amount of data for pre-training. Various data efficient approaches (DeiT) have been proposed to train ViT on balanced datasets effectively. However, limited literature discusses the use of ViT for datasets with long-tailed imbalances. In this work, we introduce DeiT-LT to tackle the problem of training ViTs from scratch on long-tailed datasets. In DeiT-LT, we introduce an efficient and effective way of distillation from CNN via distillation DIST token by using out-of-distribution images and re-weighting the distillation loss to enhance focus on tail classes. This leads to the learning of local CNN-like features in early ViT blocks, improving generalization for tail classes. Further, to mitigate overfitting, we propose distilling from a flat CNN teacher, which leads to learning low-rank generalizable features for DIST tokens across all ViT blocks. With the proposed DeiT-LT scheme, the distillation DIST token becomes an expert on the tail classes, and the classifier CLS token becomes an expert on the head classes. The experts help to effectively learn features corresponding to both the majority and minority classes using a distinct set of tokens within the same ViT architecture. We show the effectiveness of DeiT-LT for training ViT from scratch on datasets ranging from small-scale CIFAR-10 LT to large-scale iNaturalist-2018.
4/4/2024