Balancing Immediate Revenue and Future Off-Policy Evaluation in Coupon Allocation

0

Sign in to get full access
Overview
- This paper explores the challenge of balancing immediate revenue and future off-policy evaluation in the context of coupon allocation.
- The researchers propose a multi-objective optimization approach to address this problem, aiming to maximize both short-term revenue and the quality of future off-policy evaluation.
- Key techniques used in the paper include offline policy evaluation and robust portfolio optimization.
Plain English Explanation
Coupons are a common marketing strategy used by businesses to attract new customers and encourage existing ones to make purchases. However, the decision of how to allocate these coupons can be challenging, as it involves balancing the immediate revenue gained from coupon redemptions with the long-term value of the data collected from those redemptions.
The researchers in this paper recognized this tradeoff and developed a novel approach to address it. Their key insight was to view the coupon allocation problem as a multi-objective optimization task, where the goal is to simultaneously maximize short-term revenue and the quality of future off-policy evaluation (the ability to accurately assess the performance of alternative coupon allocation strategies).
By framing the problem in this way, the researchers were able to leverage techniques from robust portfolio optimization and offline policy evaluation to develop a practical solution. This approach allows businesses to find the optimal balance between immediate profits and long-term strategic insights, ultimately leading to more informed decision-making and better overall outcomes.
Technical Explanation
The key technical elements of this paper are:
-
Multi-Objective Optimization: The researchers formulated the coupon allocation problem as a multi-objective optimization task, where the goals were to maximize both immediate revenue and the quality of future off-policy evaluation. This approach allowed them to capture the inherent tradeoff between these two objectives.
-
Robust Portfolio Optimization: The researchers adapted techniques from robust portfolio optimization to allocate coupons in a way that is robust to uncertainty in customer behavior and redemption patterns.
-
Offline Policy Evaluation: To assess the quality of future off-policy evaluation, the researchers leveraged techniques from offline policy evaluation and OPERA, which allow for the accurate evaluation of alternative coupon allocation strategies without the need for expensive online experimentation.
-
Combining Experimental and Historical Data: The researchers demonstrated how to combine experimental and historical data to improve the accuracy of off-policy evaluation, further enhancing the practical value of their approach.
By integrating these key technical elements, the researchers were able to develop a policy learning framework that effectively balances immediate revenue and future off-policy evaluation in the context of coupon allocation.
Critical Analysis
One of the key strengths of this research is its recognition of the inherent tradeoff between short-term revenue and long-term strategic insights in coupon allocation. By framing the problem as a multi-objective optimization task, the researchers were able to develop a practical solution that addresses this fundamental challenge.
However, the paper also acknowledges several limitations and areas for further research. For example, the proposed approach relies on accurate modeling of customer behavior and redemption patterns, which may be difficult to achieve in practice. Additionally, the paper does not address the potential ethical implications of using coupon allocation strategies to optimize for revenue at the expense of customer welfare.
Furthermore, while the researchers demonstrated the effectiveness of their approach using simulated data, it would be valuable to see the technique applied and evaluated in real-world business settings to fully assess its practical utility and scalability.
Conclusion
This paper presents a novel approach to the coupon allocation problem that seeks to balance immediate revenue and the long-term value of off-policy evaluation. By leveraging techniques from robust portfolio optimization, offline policy evaluation, and the combination of experimental and historical data, the researchers have developed a compelling framework for addressing this complex challenge.
While the proposed solution has some limitations and areas for further exploration, the core ideas and insights presented in this paper have the potential to significantly impact the way businesses approach coupon allocation and, more broadly, the optimization of marketing strategies in the face of competing objectives. As the field of policy learning continues to evolve, this research represents an important contribution to the ongoing efforts to balance short-term and long-term priorities in decision-making.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Balancing Immediate Revenue and Future Off-Policy Evaluation in Coupon Allocation
Naoki Nishimura, Ken Kobayashi, Kazuhide Nakata
Coupon allocation drives customer purchases and boosts revenue. However, it presents a fundamental trade-off between exploiting the current optimal policy to maximize immediate revenue and exploring alternative policies to collect data for future policy improvement via off-policy evaluation (OPE). To balance this trade-off, we propose a novel approach that combines a model-based revenue maximization policy and a randomized exploration policy for data collection. Our framework enables flexible adjustment of the mixture ratio between these two policies to optimize the balance between short-term revenue and future policy improvement. We formulate the problem of determining the optimal mixture ratio as multi-objective optimization, enabling quantitative evaluation of this trade-off. We empirically verified the effectiveness of the proposed mixed policy using synthetic data. Our main contributions are: (1) Demonstrating a mixed policy combining deterministic and probabilistic policies, flexibly adjusting the data collection vs. revenue trade-off. (2) Formulating the optimal mixture ratio problem as multi-objective optimization, enabling quantitative evaluation of this trade-off.
Read more9/10/2024
🛠️
0
Robust portfolio optimization model for electronic coupon allocation
Yuki Uehara, Naoki Nishimura, Yilin Li, Jie Yang, Deddy Jobson, Koya Ohashi, Takeshi Matsumoto, Noriyoshi Sukegawa, Yuichi Takano
Currently, many e-commerce websites issue online/electronic coupons as an effective tool for promoting sales of various products and services. We focus on the problem of optimally allocating coupons to customers subject to a budget constraint on an e-commerce website. We apply a robust portfolio optimization model based on customer segmentation to the coupon allocation problem. We also validate the efficacy of our method through numerical experiments using actual data from randomly distributed coupons. Main contributions of our research are twofold. First, we handle six types of coupons, thereby making it extremely difficult to accurately estimate the difference in the effects of various coupons. Second, we demonstrate from detailed numerical results that the robust optimization model achieved larger uplifts of sales than did the commonly-used multiple-choice knapsack model and the conventional mean-variance optimization model. Our results open up great potential for robust portfolio optimization as an effective tool for practical coupon allocation.
Read more5/22/2024
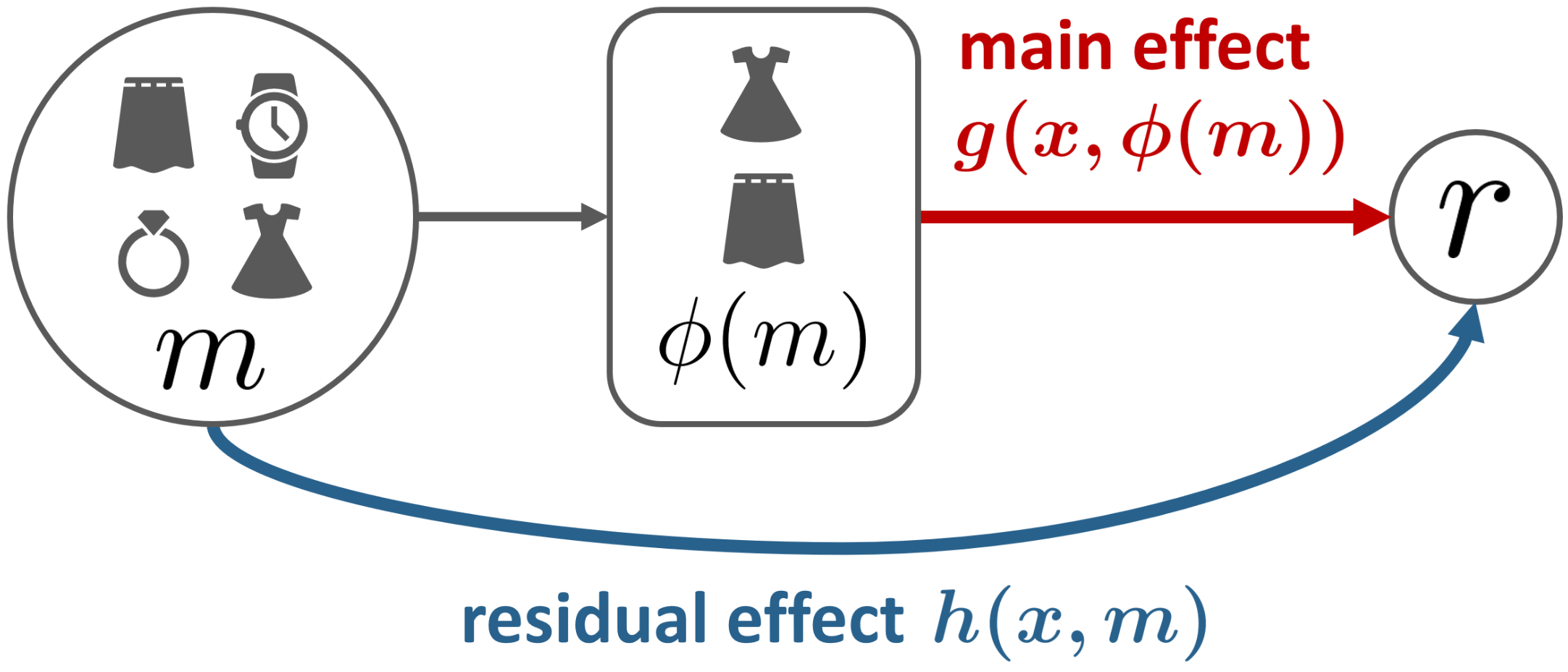
0
Effective Off-Policy Evaluation and Learning in Contextual Combinatorial Bandits
Tatsuhiro Shimizu, Koichi Tanaka, Ren Kishimoto, Haruka Kiyohara, Masahiro Nomura, Yuta Saito
We explore off-policy evaluation and learning (OPE/L) in contextual combinatorial bandits (CCB), where a policy selects a subset in the action space. For example, it might choose a set of furniture pieces (a bed and a drawer) from available items (bed, drawer, chair, etc.) for interior design sales. This setting is widespread in fields such as recommender systems and healthcare, yet OPE/L of CCB remains unexplored in the relevant literature. Typical OPE/L methods such as regression and importance sampling can be applied to the CCB problem, however, they face significant challenges due to high bias or variance, exacerbated by the exponential growth in the number of available subsets. To address these challenges, we introduce a concept of factored action space, which allows us to decompose each subset into binary indicators. This formulation allows us to distinguish between the ''main effect'' derived from the main actions, and the ''residual effect'', originating from the supplemental actions, facilitating more effective OPE. Specifically, our estimator, called OPCB, leverages an importance sampling-based approach to unbiasedly estimate the main effect, while employing regression-based approach to deal with the residual effect with low variance. OPCB achieves substantial variance reduction compared to conventional importance sampling methods and bias reduction relative to regression methods under certain conditions, as illustrated in our theoretical analysis. Experiments demonstrate OPCB's superior performance over typical methods in both OPE and OPL.
Read more8/22/2024

0
Offline Policy Evaluation for Reinforcement Learning with Adaptively Collected Data
Sunil Madhow, Dan Qiao, Ming Yin, Yu-Xiang Wang
Developing theoretical guarantees on the sample complexity of offline RL methods is an important step towards making data-hungry RL algorithms practically viable. Currently, most results hinge on unrealistic assumptions about the data distribution -- namely that it comprises a set of i.i.d. trajectories collected by a single logging policy. We consider a more general setting where the dataset may have been gathered adaptively. We develop theory for the TMIS Offline Policy Evaluation (OPE) estimator in this generalized setting for tabular MDPs, deriving high-probability, instance-dependent bounds on its estimation error. We also recover minimax-optimal offline learning in the adaptive setting. Finally, we conduct simulations to empirically analyze the behavior of these estimators under adaptive and non-adaptive regimes.
Read more5/2/2024