Bayesian Neural Networks: A Min-Max Game Framework

0
🧠
Sign in to get full access
Overview
- This paper presents a game theory formulation of Bayesian Neural Networks (BNNs) to improve their robustness and noise analysis.
- BNNs have been shown to provide some robustness to deep learning, and the minimax method is used to assist the Bayesian method.
- The authors formulate the BNN as a game between a deterministic neural network
fand a sampling networkf + ξorf + r*ξ, inspired by a recent closed-loop transcription neural network.
Plain English Explanation
The paper explores a way to make deep neural networks more robust and better able to handle noise. It uses a technique called Bayesian Neural Networks (BNNs), which can provide some protection against the challenges that deep learning models sometimes face.
The key idea is to set up the BNN as a kind of game between two players: a deterministic neural network f, and a sampling network f + ξ or f + r*ξ. This sampling network represents the potential noise or uncertainty in the system.
By formulating the BNN as a game between these two players, the authors believe they can find a "sweet spot" - a stable solution space that is somewhere between the central network f and the sampling points f + r*ξ. This conservative approach with a well-chosen prior setting is meant to help the model better recognize out-of-distribution or noisy data, even as it continues to learn from real data over time.
The experiments so far have focused on simpler datasets like MNIST and Fashion MNIST. The authors note that more work is needed to test this approach on more complex, realistic datasets and neural network models.
Technical Explanation
The paper proposes a game theory formulation of Bayesian Neural Networks (BNNs) to improve their robustness and noise analysis. BNNs have been shown to provide some robustness to deep learning, and the minimax method is a natural conservative way to assist the Bayesian method.
Inspired by a recent closed-loop transcription neural network, the authors formulate the BNN as a game between a deterministic neural network f and a sampling network f + ξ or f + r*ξ, where ξ represents the potential noise or uncertainty.
Compared to previous BNN approaches, this game theory formulation learns a solution space within a certain gap between the central network f and the sampling points f + r*ξ. This is a more conservative choice with a meaningful prior setting.
Furthermore, the authors find that the minimum points between f and f + r*ξ become stable when the subspace dimension is large enough with a well-trained model f. This means the model f has a higher chance of recognizing out-of-distribution or noise data within this subspace, even as it continues learning from true data.
The experiments so far have been limited to the MNIST and Fashion MNIST datasets. As noted by the authors, more work is needed to validate this approach on more realistic datasets and complex neural network models.
Critical Analysis
The paper presents an interesting game theory formulation of BNNs to improve their robustness and noise handling capabilities. The key idea of framing the BNN as a game between a deterministic network and a sampling network is novel and worth exploring further.
However, the experiments are currently limited to relatively simple datasets like MNIST and Fashion MNIST. More work is needed to test the approach on more complex, realistic datasets and neural network architectures to truly assess its effectiveness.
Additionally, the paper does not provide a detailed analysis of the limitations or potential drawbacks of this game theory approach. For example, it's unclear how the choice of prior and other hyperparameters might impact the performance and stability of the solution space.
It would also be helpful to see a more thorough comparison to other BNN and noise-handling techniques, such as adversarial training or active learning approaches, to better understand the unique advantages and disadvantages of the proposed method.
Conclusion
This paper presents a promising game theory formulation of Bayesian Neural Networks that aims to improve their robustness and noise handling capabilities. By framing the BNN as a game between a deterministic network and a sampling network, the authors believe they can find a stable solution space that helps the model better recognize out-of-distribution and noisy data.
While the initial results on simpler datasets are encouraging, more research is needed to validate this approach on more complex, realistic datasets and neural network architectures. A deeper analysis of the limitations and tradeoffs of this method, as well as comparisons to other noise-handling techniques, would also help contextualize the significance of this work and its potential impact on the field of deep learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🧠
0
Bayesian Neural Networks: A Min-Max Game Framework
Junping Hong, Ercan Engin Kuruoglu
This paper is a preliminary study of the robustness and noise analysis of deep neural networks via a game theory formulation Bayesian Neural Networks (BNN) and the maximal coding rate distortion loss. BNN has been shown to provide some robustness to deep learning, and the minimax method used to be a natural conservative way to assist the Bayesian method. Inspired by the recent closed-loop transcription neural network, we formulate the BNN via game theory between the deterministic neural network $f$ and the sampling network $f + xi$ or $f + r*xi$. Compared with previous BNN, BNN via game theory learns a solution space within a certain gap between the center $f$ and the sampling point $f + r*xi$, and is a conservative choice with a meaningful prior setting compared with previous BNN. Furthermore, the minimum points between $f$ and $f + r*xi$ become stable when the subspace dimension is large enough with a well-trained model $f$. With these, the model $f$ can have a high chance of recognizing the out-of-distribution data or noise data in the subspace rather than the prediction level, even if $f$ is in online training after a few iterations of true data. So far, our experiments are limited to MNIST and Fashion MNIST data sets, more experiments with realistic data sets and complicated neural network models should be implemented to validate the above arguments.
Read more5/30/2024
🧠
0
A Study of Bayesian Neural Network Surrogates for Bayesian Optimization
Yucen Lily Li, Tim G. J. Rudner, Andrew Gordon Wilson
Bayesian optimization is a highly efficient approach to optimizing objective functions which are expensive to query. These objectives are typically represented by Gaussian process (GP) surrogate models which are easy to optimize and support exact inference. While standard GP surrogates have been well-established in Bayesian optimization, Bayesian neural networks (BNNs) have recently become practical function approximators, with many benefits over standard GPs such as the ability to naturally handle non-stationarity and learn representations for high-dimensional data. In this paper, we study BNNs as alternatives to standard GP surrogates for optimization. We consider a variety of approximate inference procedures for finite-width BNNs, including high-quality Hamiltonian Monte Carlo, low-cost stochastic MCMC, and heuristics such as deep ensembles. We also consider infinite-width BNNs, linearized Laplace approximations, and partially stochastic models such as deep kernel learning. We evaluate this collection of surrogate models on diverse problems with varying dimensionality, number of objectives, non-stationarity, and discrete and continuous inputs. We find: (i) the ranking of methods is highly problem dependent, suggesting the need for tailored inductive biases; (ii) HMC is the most successful approximate inference procedure for fully stochastic BNNs; (iii) full stochasticity may be unnecessary as deep kernel learning is relatively competitive; (iv) deep ensembles perform relatively poorly; (v) infinite-width BNNs are particularly promising, especially in high dimensions.
Read more5/9/2024

0
Bayesian Entropy Neural Networks for Physics-Aware Prediction
Rahul Rathnakumar, Jiayu Huang, Hao Yan, Yongming Liu
This paper addresses the need for deep learning models to integrate well-defined constraints into their outputs, driven by their application in surrogate models, learning with limited data and partial information, and scenarios requiring flexible model behavior to incorporate non-data sample information. We introduce Bayesian Entropy Neural Networks (BENN), a framework grounded in Maximum Entropy (MaxEnt) principles, designed to impose constraints on Bayesian Neural Network (BNN) predictions. BENN is capable of constraining not only the predicted values but also their derivatives and variances, ensuring a more robust and reliable model output. To achieve simultaneous uncertainty quantification and constraint satisfaction, we employ the method of multipliers approach. This allows for the concurrent estimation of neural network parameters and the Lagrangian multipliers associated with the constraints. Our experiments, spanning diverse applications such as beam deflection modeling and microstructure generation, demonstrate the effectiveness of BENN. The results highlight significant improvements over traditional BNNs and showcase competitive performance relative to contemporary constrained deep learning methods.
Read more7/2/2024
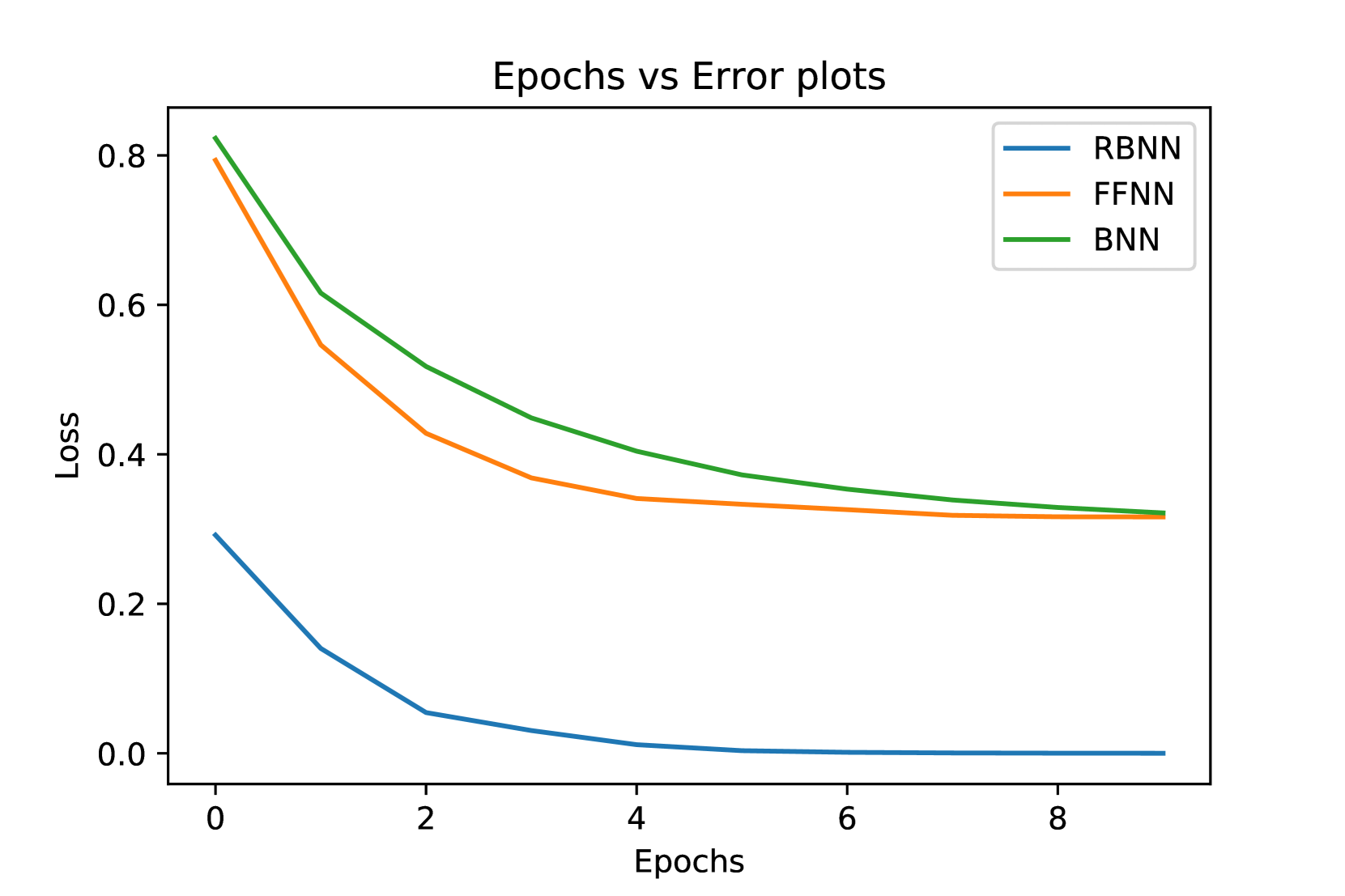
0
Restricted Bayesian Neural Network
Sourav Ganguly, Saprativa Bhattacharjee
Modern deep learning tools are remarkably effective in addressing intricate problems. However, their operation as black-box models introduces increased uncertainty in predictions. Additionally, they contend with various challenges, including the need for substantial storage space in large networks, issues of overfitting, underfitting, vanishing gradients, and more. This study explores the concept of Bayesian Neural Networks, presenting a novel architecture designed to significantly alleviate the storage space complexity of a network. Furthermore, we introduce an algorithm adept at efficiently handling uncertainties, ensuring robust convergence values without becoming trapped in local optima, particularly when the objective function lacks perfect convexity.
Read more4/9/2024