Bayesian Optimization with LLM-Based Acquisition Functions for Natural Language Preference Elicitation

0

Sign in to get full access
Overview
- This paper presents a novel approach to natural language preference elicitation using Bayesian optimization and large language models (LLMs).
- The researchers develop LLM-based acquisition functions to guide the optimization process and efficiently explore the user's preferences.
- The proposed method aims to enable more natural and engaging conversational recommendation systems.
Plain English Explanation
The paper explores a new way to help conversational recommendation systems, such as chatbots or virtual assistants, better understand a user's preferences. Traditionally, these systems might ask a user a series of direct questions to try to figure out what the user likes. But this can feel tedious and impersonal.
The researchers in this paper propose using Bayesian optimization, a powerful machine learning technique, together with large language models (LLMs) like GPT-3. LLMs are very advanced AI systems that can understand and generate human-like language. The key idea is to use the LLM to generate more natural, conversational questions that probe the user's preferences in a more engaging way.
Essentially, the system starts with some initial guesses about the user's preferences. It then uses Bayesian optimization to intelligently decide what question to ask next, choosing questions that are likely to provide the most useful information to refine its understanding of the user. The LLM helps craft these questions in a more natural, human-like way, making the interaction feel more like a conversation.
The researchers show through experiments that this approach can efficiently learn a user's preferences using far fewer questions than traditional methods. This could lead to more seamless, personalized conversational recommendation systems that feel more natural and intuitive to use.
Technical Explanation
The paper introduces a Bayesian optimization framework for natural language preference elicitation. The key innovation is the use of LLM-based acquisition functions to guide the optimization process.
Traditionally, preference elicitation in conversational recommender systems has relied on direct questioning, which can feel impersonal. The authors propose using Bayesian optimization to intelligently select the most informative questions to ask the user. Bayesian optimization is a powerful technique for optimizing black-box functions by building a probabilistic model of the function and using it to guide the search.
In this case, the "black-box function" being optimized is the user's latent preference function. The authors use Gaussian processes to model this function and develop several LLM-based acquisition functions to decide which query to ask next. The acquisition functions leverage the language understanding and generation capabilities of LLMs to produce more natural, conversational queries.
The authors evaluate their approach on both synthetic and real-world datasets, comparing it to baseline methods. The results show that the LLM-based acquisition functions can efficiently learn the user's preferences using far fewer queries than traditional techniques. This suggests the proposed framework could enable more engaging and personalized conversational recommendation systems.
Critical Analysis
The paper presents a promising approach to improving conversational recommendation systems, but there are a few potential limitations and areas for further research:
-
The experiments are still relatively small-scale and focused on simulated scenarios. More research is needed to understand how the approach would scale and perform in real-world, large-scale deployments with diverse user populations.
-
The paper does not address the potential biases or limitations of the LLMs used to generate the acquisition functions. As discussed elsewhere, LLMs can reflect societal biases and may not perform equally well across different demographics.
-
The optimization process assumes the user's preferences are static and do not change over time. In reality, user preferences can evolve, and the system should be able to adapt accordingly. Integrating methods for personalization and adaptation could be an important area for future research.
-
The paper does not explore the potential privacy implications of the proposed approach, where a conversational system collects detailed information about a user's preferences. Addressing privacy concerns will be crucial for the real-world deployment of such systems.
Overall, the paper presents an innovative and promising direction for improving conversational recommendation systems. However, further research is needed to address the potential limitations and ensure the approach is robust, scalable, and respects user privacy.
Conclusion
This paper introduces a novel Bayesian optimization framework for natural language preference elicitation, leveraging the capabilities of large language models to generate more engaging and informative conversational queries. The results suggest this approach can efficiently learn user preferences using far fewer questions than traditional methods, paving the way for more seamless and personalized conversational recommendation systems.
While the research shows promise, there are still important challenges to address, such as scalability, bias, and privacy considerations. Continued advancements in this area could have significant implications for the future of conversational AI and its ability to provide personalized, natural, and valuable experiences for users.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Bayesian Optimization with LLM-Based Acquisition Functions for Natural Language Preference Elicitation
David Eric Austin, Anton Korikov, Armin Toroghi, Scott Sanner
Designing preference elicitation (PE) methodologies that can quickly ascertain a user's top item preferences in a cold-start setting is a key challenge for building effective and personalized conversational recommendation (ConvRec) systems. While large language models (LLMs) enable fully natural language (NL) PE dialogues, we hypothesize that monolithic LLM NL-PE approaches lack the multi-turn, decision-theoretic reasoning required to effectively balance the exploration and exploitation of user preferences towards an arbitrary item set. In contrast, traditional Bayesian optimization PE methods define theoretically optimal PE strategies, but cannot generate arbitrary NL queries or reason over content in NL item descriptions -- requiring users to express preferences via ratings or comparisons of unfamiliar items. To overcome the limitations of both approaches, we formulate NL-PE in a Bayesian Optimization (BO) framework that seeks to actively elicit NL feedback to identify the best recommendation. Key challenges in generalizing BO to deal with natural language feedback include determining: (a) how to leverage LLMs to model the likelihood of NL preference feedback as a function of item utilities, and (b) how to design an acquisition function for NL BO that can elicit preferences in the infinite space of language. We demonstrate our framework in a novel NL-PE algorithm, PEBOL, which uses: 1) Natural Language Inference (NLI) between user preference utterances and NL item descriptions to maintain Bayesian preference beliefs, and 2) BO strategies such as Thompson Sampling (TS) and Upper Confidence Bound (UCB) to steer LLM query generation. We numerically evaluate our methods in controlled simulations, finding that after 10 turns of dialogue, PEBOL can achieve an MRR@10 of up to 0.27 compared to the best monolithic LLM baseline's MRR@10 of 0.17, despite relying on earlier and smaller LLMs.
Read more8/21/2024
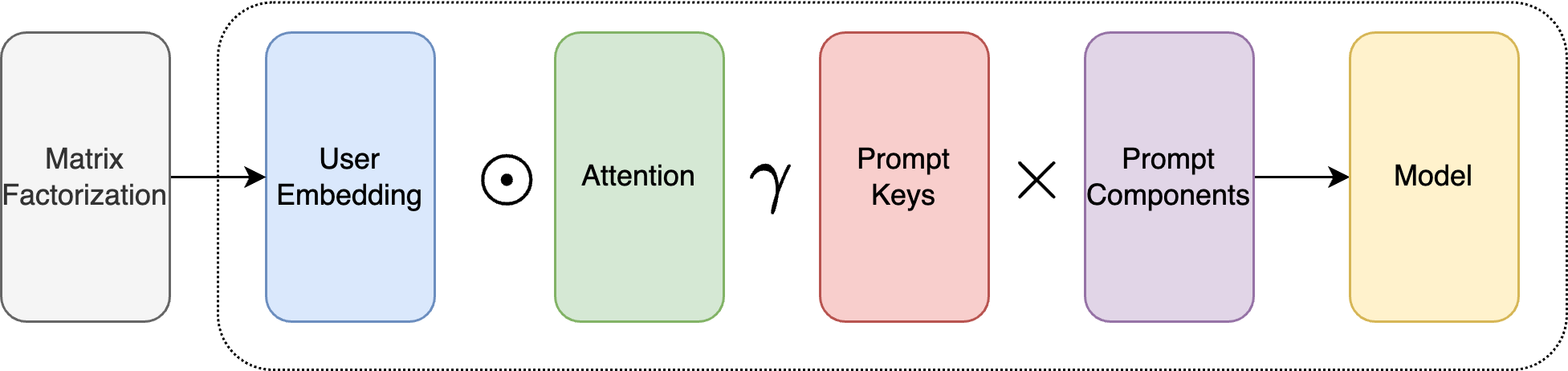
0
Preference Distillation for Personalized Generative Recommendation
Jerome Ramos, Bin Wu, Aldo Lipani
Recently, researchers have investigated the capabilities of Large Language Models (LLMs) for generative recommender systems. Existing LLM-based recommender models are trained by adding user and item IDs to a discrete prompt template. However, the disconnect between IDs and natural language makes it difficult for the LLM to learn the relationship between users. To address this issue, we propose a PErsonAlized PrOmpt Distillation (PeaPOD) approach, to distill user preferences as personalized soft prompts. Considering the complexities of user preferences in the real world, we maintain a shared set of learnable prompts that are dynamically weighted based on the user's interests to construct the user-personalized prompt in a compositional manner. Experimental results on three real-world datasets demonstrate the effectiveness of our PeaPOD model on sequential recommendation, top-n recommendation, and explanation generation tasks.
Read more7/9/2024

0
Deep Bayesian Active Learning for Preference Modeling in Large Language Models
Luckeciano C. Melo, Panagiotis Tigas, Alessandro Abate, Yarin Gal
Leveraging human preferences for steering the behavior of Large Language Models (LLMs) has demonstrated notable success in recent years. Nonetheless, data selection and labeling are still a bottleneck for these systems, particularly at large scale. Hence, selecting the most informative points for acquiring human feedback may considerably reduce the cost of preference labeling and unleash the further development of LLMs. Bayesian Active Learning provides a principled framework for addressing this challenge and has demonstrated remarkable success in diverse settings. However, previous attempts to employ it for Preference Modeling did not meet such expectations. In this work, we identify that naive epistemic uncertainty estimation leads to the acquisition of redundant samples. We address this by proposing the Bayesian Active Learner for Preference Modeling (BAL-PM), a novel stochastic acquisition policy that not only targets points of high epistemic uncertainty according to the preference model but also seeks to maximize the entropy of the acquired prompt distribution in the feature space spanned by the employed LLM. Notably, our experiments demonstrate that BAL-PM requires 33% to 68% fewer preference labels in two popular human preference datasets and exceeds previous stochastic Bayesian acquisition policies.
Read more6/17/2024

0
Strengthening Multimodal Large Language Model with Bootstrapped Preference Optimization
Renjie Pi, Tianyang Han, Wei Xiong, Jipeng Zhang, Runtao Liu, Rui Pan, Tong Zhang
Multimodal Large Language Models (MLLMs) excel in generating responses based on visual inputs. However, they often suffer from a bias towards generating responses similar to their pretraining corpus, overshadowing the importance of visual information. We treat this bias as a preference for pretraining statistics, which hinders the model's grounding in visual input. To mitigate this issue, we propose Bootstrapped Preference Optimization (BPO), which conducts preference learning with datasets containing negative responses bootstrapped from the model itself. Specifically, we propose the following two strategies: 1) using distorted image inputs to the MLLM for eliciting responses that contain signified pretraining bias; 2) leveraging text-based LLM to explicitly inject erroneous but common elements into the original response. Those undesirable responses are paired with original annotated responses from the datasets to construct the preference dataset, which is subsequently utilized to perform preference learning. Our approach effectively suppresses pretrained LLM bias, enabling enhanced grounding in visual inputs. Extensive experimentation demonstrates significant performance improvements across multiple benchmarks, advancing the state-of-the-art in multimodal conversational systems.
Read more4/4/2024