Be like a Goldfish, Don't Memorize! Mitigating Memorization in Generative LLMs

0

Sign in to get full access
Overview
- This paper explores the issue of memorization in large language models (LLMs) and proposes techniques to mitigate it.
- Memorization can cause LLMs to reproduce copyrighted or sensitive content, leading to issues like copyright infringement and privacy violations.
- The authors introduce several methods to reduce memorization, including MemLLM, which fine-tunes LLMs to use explicit read and write operations to access a memory module.
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can generate human-like text on a wide range of topics. However, these models can sometimes memorize and reproduce copyrighted or sensitive information, which can cause problems.
The authors of this paper wanted to find ways to prevent LLMs from memorizing too much. They introduced a few different techniques, including one called MemLLM that trains the LLM to access a separate memory module instead of trying to remember everything.
The goal is for the LLM to be more like a goldfish - able to generate great text without remembering too much of the specific information it was trained on. This could help avoid issues like copyright infringement and protect people's privacy.
Technical Explanation
The paper first reviews related work on identifying and mitigating memorization in LLMs, including techniques like multi-perspective analysis and detecting fuzzy duplicates.
The authors then introduce their main contribution, MemLLM, which fine-tunes LLMs to use explicit read and write operations to access a separate memory module. This allows the model to dynamically retrieve and store information, rather than relying solely on its internal parameters.
Experiments on tabular data and language modeling benchmarks show that MemLLM can significantly reduce memorization while maintaining strong performance. The authors analyze the tradeoffs between memorization, generalization, and task performance.
Critical Analysis
The paper provides a thoughtful approach to mitigating memorization in LLMs, which is an important issue for the responsible development of these powerful models. The authors thoroughly review prior work and introduce a novel technique in MemLLM that shows promising results.
However, the paper does not address some potential limitations or broader concerns. For example, it does not discuss how MemLLM's memory module might be vulnerable to adversarial attacks or how to ensure the privacy and security of the information stored in it.
Additionally, the paper focuses on reducing memorization, but does not explore the potential downsides of this approach. Eliminating all memorization could potentially harm an LLM's ability to learn and retain important factual knowledge.
Further research is needed to better understand the tradeoffs and develop more nuanced solutions that balance the need to prevent harmful memorization with the benefits of robust knowledge retention.
Conclusion
This paper presents an interesting approach, MemLLM, for mitigating memorization in large language models. By training the models to use a separate memory module rather than relying solely on their internal parameters, the authors show they can significantly reduce the reproduction of copyrighted or sensitive content while maintaining strong performance.
While more work is needed to fully address the complexities of this issue, this research represents an important step forward in developing LLMs that are more trustworthy and aligned with societal needs. As these models become increasingly influential, finding ways to prevent harmful memorization will be crucial for ensuring their responsible and beneficial use.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Be like a Goldfish, Don't Memorize! Mitigating Memorization in Generative LLMs
Abhimanyu Hans, Yuxin Wen, Neel Jain, John Kirchenbauer, Hamid Kazemi, Prajwal Singhania, Siddharth Singh, Gowthami Somepalli, Jonas Geiping, Abhinav Bhatele, Tom Goldstein
Large language models can memorize and repeat their training data, causing privacy and copyright risks. To mitigate memorization, we introduce a subtle modification to the next-token training objective that we call the goldfish loss. During training, a randomly sampled subset of tokens are excluded from the loss computation. These dropped tokens are not memorized by the model, which prevents verbatim reproduction of a complete chain of tokens from the training set. We run extensive experiments training billion-scale Llama-2 models, both pre-trained and trained from scratch, and demonstrate significant reductions in extractable memorization with little to no impact on downstream benchmarks.
Read more6/17/2024

0
Uncovering Latent Memories: Assessing Data Leakage and Memorization Patterns in Large Language Models
Sunny Duan, Mikail Khona, Abhiram Iyer, Rylan Schaeffer, Ila R Fiete
Frontier AI systems are making transformative impacts across society, but such benefits are not without costs: models trained on web-scale datasets containing personal and private data raise profound concerns about data privacy and security. Language models are trained on extensive corpora including potentially sensitive or proprietary information, and the risk of data leakage - where the model response reveals pieces of such information - remains inadequately understood. Prior work has investigated what factors drive memorization and have identified that sequence complexity and the number of repetitions drive memorization. Here, we focus on the evolution of memorization over training. We begin by reproducing findings that the probability of memorizing a sequence scales logarithmically with the number of times it is present in the data. We next show that sequences which are apparently not memorized after the first encounter can be uncovered throughout the course of training even without subsequent encounters, a phenomenon we term latent memorization. The presence of latent memorization presents a challenge for data privacy as memorized sequences may be hidden at the final checkpoint of the model but remain easily recoverable. To this end, we develop a diagnostic test relying on the cross entropy loss to uncover latent memorized sequences with high accuracy.
Read more7/26/2024
0
Demystifying Verbatim Memorization in Large Language Models
Jing Huang, Diyi Yang, Christopher Potts
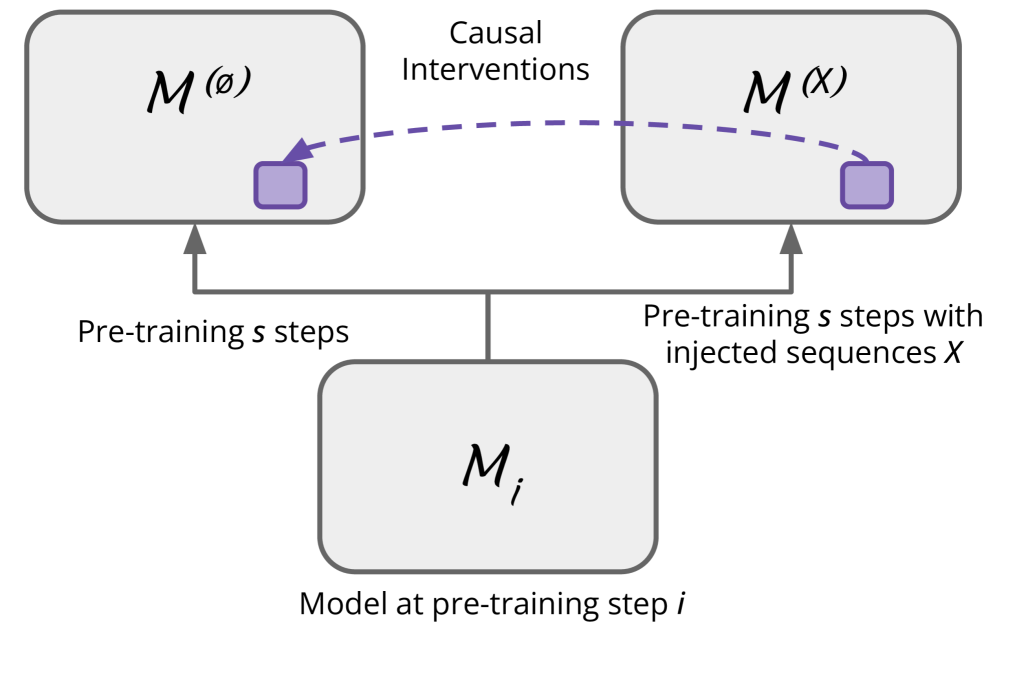
Large Language Models (LLMs) frequently memorize long sequences verbatim, often with serious legal and privacy implications. Much prior work has studied such verbatim memorization using observational data. To complement such work, we develop a framework to study verbatim memorization in a controlled setting by continuing pre-training from Pythia checkpoints with injected sequences. We find that (1) non-trivial amounts of repetition are necessary for verbatim memorization to happen; (2) later (and presumably better) checkpoints are more likely to verbatim memorize sequences, even for out-of-distribution sequences; (3) the generation of memorized sequences is triggered by distributed model states that encode high-level features and makes important use of general language modeling capabilities. Guided by these insights, we develop stress tests to evaluate unlearning methods and find they often fail to remove the verbatim memorized information, while also degrading the LM. Overall, these findings challenge the hypothesis that verbatim memorization stems from specific model weights or mechanisms. Rather, verbatim memorization is intertwined with the LM's general capabilities and thus will be very difficult to isolate and suppress without degrading model quality.
Read more7/26/2024
💬
0
To Each (Textual Sequence) Its Own: Improving Memorized-Data Unlearning in Large Language Models
George-Octavian Barbulescu, Peter Triantafillou
LLMs have been found to memorize training textual sequences and regurgitate verbatim said sequences during text generation time. This fact is known to be the cause of privacy and related (e.g., copyright) problems. Unlearning in LLMs then takes the form of devising new algorithms that will properly deal with these side-effects of memorized data, while not hurting the model's utility. We offer a fresh perspective towards this goal, namely, that each textual sequence to be forgotten should be treated differently when being unlearned based on its degree of memorization within the LLM. We contribute a new metric for measuring unlearning quality, an adversarial attack showing that SOTA algorithms lacking this perspective fail for privacy, and two new unlearning methods based on Gradient Ascent and Task Arithmetic, respectively. A comprehensive performance evaluation across an extensive suite of NLP tasks then mapped the solution space, identifying the best solutions under different scales in model capacities and forget set sizes and quantified the gains of the new approaches.
Read more5/7/2024