Bellman Diffusion Models

0
🤖
Sign in to get full access
Overview
- The paper introduces "Bellman Diffusion Models", a novel approach to diffusion models that incorporates Bellman updates for improved performance on tasks like policy imitation.
- The paper covers the key concepts behind diffusion models and how Bellman updates can be integrated to enhance their capabilities.
- Experiments are conducted to demonstrate the advantages of Bellman Diffusion Models over standard diffusion models on various tasks.
Plain English Explanation
Diffusion models are a type of machine learning model that have shown impressive results in tasks like image generation and audio synthesis. These models work by gradually "diffusing" or adding noise to an input, then learning to reverse this process to generate new samples.
The key innovation in this paper is the introduction of "Bellman Diffusion Models", which incorporate a technique from reinforcement learning called Bellman updates. Bellman Diffusion Models integrate this Bellman-based approach to improve the performance of diffusion models, particularly on tasks like policy imitation, long-horizon rollout, and future modeling.
The paper demonstrates through experiments that Bellman Diffusion Models can outperform standard diffusion models on these tasks, showing the benefits of integrating Bellman updates into the diffusion framework. This work contributes to the ongoing research on enhancing the capabilities of diffusion models and exploring novel ways to combine techniques from different machine learning paradigms.
Technical Explanation
The paper begins by providing background on diffusion models, explaining how they work by gradually adding noise to an input and then learning to reverse this process to generate new samples.
The key technical contribution of this work is the integration of Bellman updates into the diffusion framework, resulting in "Bellman Diffusion Models". Bellman updates are a technique commonly used in reinforcement learning, and the paper shows how they can be effectively incorporated into diffusion models to improve performance on tasks like policy imitation, long-horizon rollout, future modeling, and policy-guided diffusion.
The paper presents detailed experiments that demonstrate the advantages of Bellman Diffusion Models over standard diffusion models on these tasks. The results show that the Bellman-based approach can lead to significant improvements in performance, highlighting the potential of combining techniques from different machine learning domains to enhance the capabilities of diffusion models.
Critical Analysis
The paper provides a thorough technical explanation of Bellman Diffusion Models and presents compelling experimental results. However, it does not address certain limitations or potential concerns that could be explored in future research.
One area for further investigation is the scalability of Bellman Diffusion Models to more complex tasks or larger-scale datasets. The experiments in the paper are focused on relatively specific and controlled scenarios, and it would be valuable to understand how the approach would perform in more real-world, high-stakes applications.
Additionally, the paper does not delve into the potential computational or memory overhead associated with the Bellman update integration. As diffusion models can already be resource-intensive, it would be important to understand the tradeoffs in terms of efficiency and practicality for deployment in real-world systems.
Finally, the paper would benefit from a more in-depth discussion of the broader implications and limitations of the Bellman Diffusion Model approach. While the technical details and experimental results are well-presented, a more critical examination of the method's broader applicability, potential biases, or ethical considerations could further strengthen the paper's contribution to the field.
Conclusion
The Bellman Diffusion Models introduced in this paper represent an innovative approach to enhancing the capabilities of diffusion models through the integration of Bellman updates. The experimental results demonstrate the advantages of this technique over standard diffusion models, particularly on tasks like policy imitation, long-horizon rollout, and future modeling.
This work contributes to the ongoing research on advancing the state-of-the-art in diffusion models and exploring novel ways to combine techniques from different machine learning paradigms. The Bellman Diffusion Model approach shows promise in expanding the applications and performance of diffusion-based models, though further research is needed to address potential scalability, efficiency, and broader implications of the method.
Overall, this paper presents a compelling and technically sound contribution to the field of diffusion models, opening up new avenues for future research and development in this rapidly evolving area of machine learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤖
0
Bellman Diffusion Models
Liam Schramm, Abdeslam Boularias
Diffusion models have seen tremendous success as generative architectures. Recently, they have been shown to be effective at modelling policies for offline reinforcement learning and imitation learning. We explore using diffusion as a model class for the successor state measure (SSM) of a policy. We find that enforcing the Bellman flow constraints leads to a simple Bellman update on the diffusion step distribution.
Read more7/18/2024

0
Enabling Stateful Behaviors for Diffusion-based Policy Learning
Xiao Liu, Fabian Weigend, Yifan Zhou, Heni Ben Amor
While imitation learning provides a simple and effective framework for policy learning, acquiring consistent actions during robot execution remains a challenging task. Existing approaches primarily focus on either modifying the action representation at data curation stage or altering the model itself, both of which do not fully address the scalability of consistent action generation. To overcome this limitation, we introduce the Diff-Control policy, which utilizes a diffusion-based model to learn the action representation from a state-space modeling viewpoint. We demonstrate that we can reduce diffusion-based policies' uncertainty by making it stateful through a Bayesian formulation facilitated by ControlNet, leading to improved robustness and success rates. Our experimental results demonstrate the significance of incorporating action statefulness in policy learning, where Diff-Control shows improved performance across various tasks. Specifically, Diff-Control achieves an average success rate of 72% and 84% on stateful and dynamic tasks, respectively. Project page: https://github.com/ir-lab/Diff-Control
Read more7/24/2024
0
Diffusion-based Dynamics Models for Long-Horizon Rollout in Offline Reinforcement Learning
Hanye Zhao, Xiaoshen Han, Zhengbang Zhu, Minghuan Liu, Yong Yu, Weinan Zhang
With the great success of diffusion models (DMs) in generating realistic synthetic vision data, many researchers have investigated their potential in decision-making and control. Most of these works utilized DMs to sample directly from the trajectory space, where DMs can be viewed as a combination of dynamics models and policies. In this work, we explore how to decouple DMs' ability as dynamics models in fully offline settings, allowing the learning policy to roll out trajectories. As DMs learn the data distribution from the dataset, their intrinsic policy is actually the behavior policy induced from the dataset, which results in a mismatch between the behavior policy and the learning policy. We propose Dynamics Diffusion, short as DyDiff, which can inject information from the learning policy to DMs iteratively. DyDiff ensures long-horizon rollout accuracy while maintaining policy consistency and can be easily deployed on model-free algorithms. We provide theoretical analysis to show the advantage of DMs on long-horizon rollout over models and demonstrate the effectiveness of DyDiff in the context of offline reinforcement learning, where the rollout dataset is provided but no online environment for interaction. Our code is at https://github.com/FineArtz/DyDiff.
Read more6/11/2024
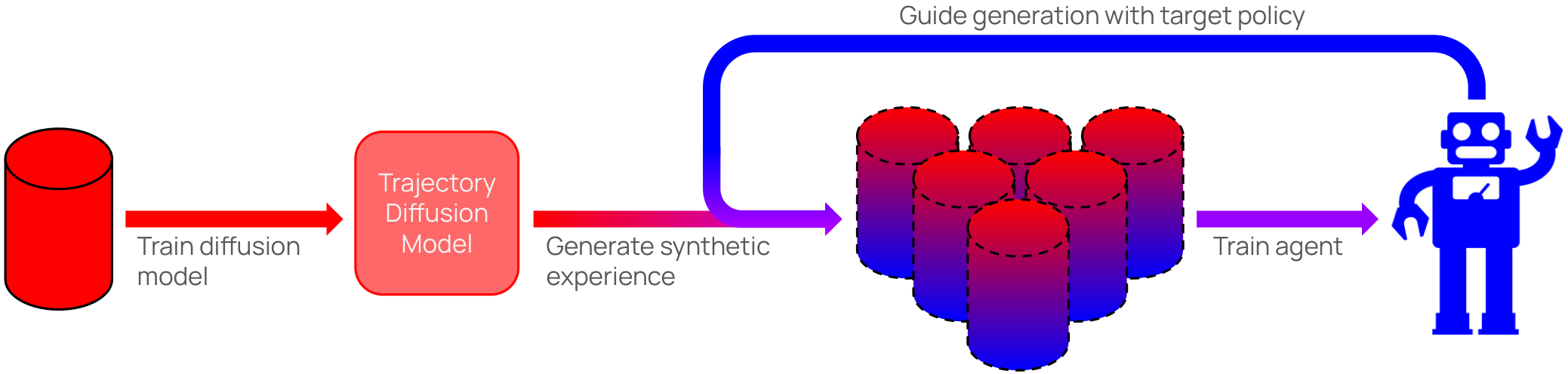
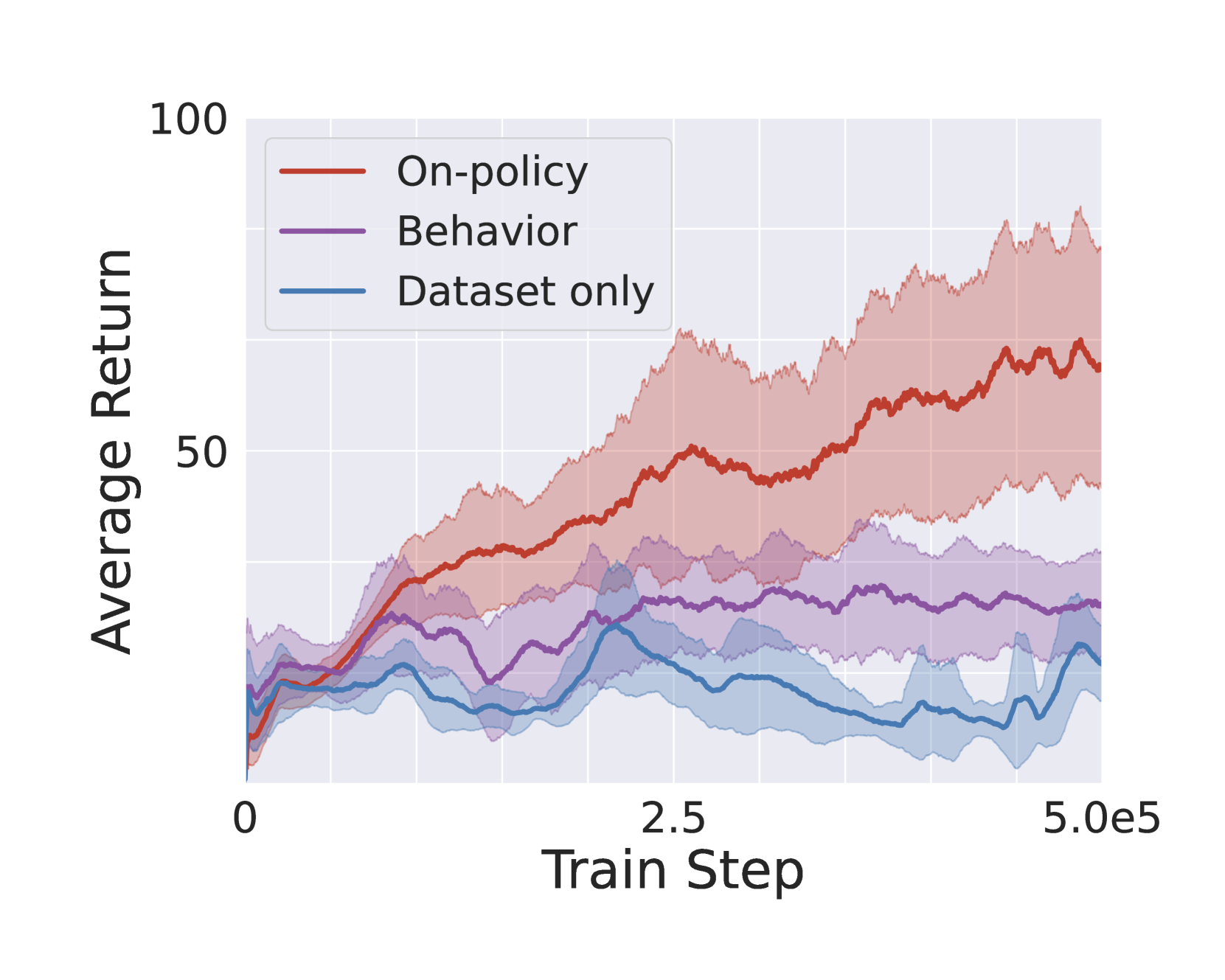
0
Policy-Guided Diffusion
Matthew Thomas Jackson, Michael Tryfan Matthews, Cong Lu, Benjamin Ellis, Shimon Whiteson, Jakob Foerster
In many real-world settings, agents must learn from an offline dataset gathered by some prior behavior policy. Such a setting naturally leads to distribution shift between the behavior policy and the target policy being trained - requiring policy conservatism to avoid instability and overestimation bias. Autoregressive world models offer a different solution to this by generating synthetic, on-policy experience. However, in practice, model rollouts must be severely truncated to avoid compounding error. As an alternative, we propose policy-guided diffusion. Our method uses diffusion models to generate entire trajectories under the behavior distribution, applying guidance from the target policy to move synthetic experience further on-policy. We show that policy-guided diffusion models a regularized form of the target distribution that balances action likelihood under both the target and behavior policies, leading to plausible trajectories with high target policy probability, while retaining a lower dynamics error than an offline world model baseline. Using synthetic experience from policy-guided diffusion as a drop-in substitute for real data, we demonstrate significant improvements in performance across a range of standard offline reinforcement learning algorithms and environments. Our approach provides an effective alternative to autoregressive offline world models, opening the door to the controllable generation of synthetic training data.
Read more4/10/2024