Diffusion World Model: Future Modeling Beyond Step-by-Step Rollout for Offline Reinforcement Learning
2402.03570
3
0

Abstract
We introduce Diffusion World Model (DWM), a conditional diffusion model capable of predicting multistep future states and rewards concurrently. As opposed to traditional one-step dynamics models, DWM offers long-horizon predictions in a single forward pass, eliminating the need for recursive queries. We integrate DWM into model-based value estimation, where the short-term return is simulated by future trajectories sampled from DWM. In the context of offline reinforcement learning, DWM can be viewed as a conservative value regularization through generative modeling. Alternatively, it can be seen as a data source that enables offline Q-learning with synthetic data. Our experiments on the D4RL dataset confirm the robustness of DWM to long-horizon simulation. In terms of absolute performance, DWM significantly surpasses one-step dynamics models with a $44%$ performance gain, and is comparable to or slightly surpassing their model-free counterparts.
Create account to get full access
Overview
- This paper introduces the Diffusion World Model, a novel approach to offline reinforcement learning that aims to learn a world model from random demonstrations.
- The key idea is to use diffusion models, a type of generative model, to learn a dynamics model that can be used for long-horizon rollout and exploration.
- The authors demonstrate the effectiveness of their approach on challenging Atari game environments, showing that it can outperform existing offline RL methods.
Plain English Explanation
The Diffusion World Model is a new way of teaching computers how to learn from random examples, without needing a specific goal in mind. The key innovation is using a type of machine learning model called a "diffusion model" to learn how the world works, based on a collection of random actions and their consequences.
Typically, reinforcement learning algorithms need a clear objective, like winning a game, to learn effectively. But the Diffusion World Model sidesteps this requirement by first learning a general model of the environment's dynamics. This allows the algorithm to explore and plan long-term strategies, even without a specific reward signal.
The authors show that their approach works well on challenging Atari video games, where it can outperform existing offline reinforcement learning methods. By learning a rich, generative model of the game world, the Diffusion World Model is able to discover effective policies without relying on a pre-defined reward function.
This research represents an important step towards more flexible and capable reinforcement learning systems, which could have applications in areas like robotics, game AI, and autonomous decision-making. By freeing the algorithm from the need for a specific objective, the Diffusion World Model opens up new possibilities for artificial intelligence to learn and explore in open-ended ways.
Technical Explanation
The key idea behind the Diffusion World Model is to use a diffusion model to learn a dynamics model of the environment, which can then be used for long-horizon rollout and exploration in an offline reinforcement learning setting.
Diffusion models are a type of generative model that can be trained to generate realistic samples by learning to reverse a process of gradually adding noise to data. The authors leverage this capability to learn a world model that can accurately predict future states of the environment, given a sequence of actions.
To train the Diffusion World Model, the authors collect a dataset of random state-action-state transitions from the environment. They then train a diffusion model to learn the transition dynamics, and use this model for long-horizon rollout and policy optimization.
The authors demonstrate the effectiveness of their approach on a suite of challenging Atari game environments, where the Diffusion World Model is able to outperform existing offline RL methods. They also show that accounting for visual details in the world model is crucial for achieving good performance.
Critical Analysis
The Diffusion World Model represents an interesting and promising approach to offline reinforcement learning, with several notable strengths:
- Flexibility: By learning a general world model rather than optimizing for a specific reward function, the Diffusion World Model is able to explore and discover effective strategies without being constrained by a pre-defined objective.
- Sample Efficiency: The ability to learn from random, unstructured demonstrations is a significant advantage, as it reduces the need for carefully curated training data.
- Expressiveness: The use of a diffusion model allows the system to learn a rich, generative representation of the environment's dynamics, which can support long-term planning and exploration.
However, the paper also acknowledges several limitations and areas for further research:
- Scalability: The computational and memory requirements of the diffusion model may limit the scalability of the approach to very large and complex environments.
- Robustness: The authors note that the performance of the Diffusion World Model can be sensitive to the quality and distribution of the demonstration data, which may be a concern in real-world applications.
- Interpretability: As with many deep learning models, the internal workings of the Diffusion World Model may be difficult to interpret, which could hinder its adoption in safety-critical domains.
Additionally, one could raise questions about the generalizability of the results to domains beyond Atari games, and the potential for negative societal impacts if the technology is misused or applied without appropriate safeguards.
Overall, the Diffusion World Model represents an exciting advancement in the field of offline reinforcement learning, with the potential to enable more flexible and capable AI systems. However, further research and careful consideration of the technology's implications will be necessary to fully realize its potential.
Conclusion
The Diffusion World Model introduces a novel approach to offline reinforcement learning that leverages diffusion models to learn a rich, generative representation of an environment's dynamics. By shifting the focus from reward maximization to world modeling, the authors have demonstrated the potential for more flexible and sample-efficient RL systems that can explore and discover effective strategies without relying on pre-defined objectives.
The success of the Diffusion World Model on challenging Atari environments suggests that this approach could have wide-ranging applications, from robotics and game AI to autonomous decision-making systems. However, the authors also highlight important limitations and areas for further research, such as scalability, robustness, and interpretability.
As AI systems become more powerful and ubiquitous, it will be crucial to continue advancing the field of reinforcement learning in responsible and thoughtful ways. The Diffusion World Model represents an important step in this direction, offering a promising path towards more capable and adaptable AI that can learn and explore in open-ended ways.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Learning from Random Demonstrations: Offline Reinforcement Learning with Importance-Sampled Diffusion Models
Zeyu Fang, Tian Lan
0
0
Generative models such as diffusion have been employed as world models in offline reinforcement learning to generate synthetic data for more effective learning. Existing work either generates diffusion models one-time prior to training or requires additional interaction data to update it. In this paper, we propose a novel approach for offline reinforcement learning with closed-loop policy evaluation and world-model adaptation. It iteratively leverages a guided diffusion world model to directly evaluate the offline target policy with actions drawn from it, and then performs an importance-sampled world model update to adaptively align the world model with the updated policy. We analyzed the performance of the proposed method and provided an upper bound on the return gap between our method and the real environment under an optimal policy. The result sheds light on various factors affecting learning performance. Evaluations in the D4RL environment show significant improvement over state-of-the-art baselines, especially when only random or medium-expertise demonstrations are available -- thus requiring improved alignment between the world model and offline policy evaluation.
5/31/2024
Diffusion-based Dynamics Models for Long-Horizon Rollout in Offline Reinforcement Learning
Hanye Zhao, Xiaoshen Han, Zhengbang Zhu, Minghuan Liu, Yong Yu, Weinan Zhang
0
0
With the great success of diffusion models (DMs) in generating realistic synthetic vision data, many researchers have investigated their potential in decision-making and control. Most of these works utilized DMs to sample directly from the trajectory space, where DMs can be viewed as a combination of dynamics models and policies. In this work, we explore how to decouple DMs' ability as dynamics models in fully offline settings, allowing the learning policy to roll out trajectories. As DMs learn the data distribution from the dataset, their intrinsic policy is actually the behavior policy induced from the dataset, which results in a mismatch between the behavior policy and the learning policy. We propose Dynamics Diffusion, short as DyDiff, which can inject information from the learning policy to DMs iteratively. DyDiff ensures long-horizon rollout accuracy while maintaining policy consistency and can be easily deployed on model-free algorithms. We provide theoretical analysis to show the advantage of DMs on long-horizon rollout over models and demonstrate the effectiveness of DyDiff in the context of offline reinforcement learning, where the rollout dataset is provided but no online environment for interaction. Our code is at https://github.com/FineArtz/DyDiff.
6/11/2024
🌀
Diffusion for World Modeling: Visual Details Matter in Atari
Eloi Alonso, Adam Jelley, Vincent Micheli, Anssi Kanervisto, Amos Storkey, Tim Pearce, Franc{c}ois Fleuret
0
0
World models constitute a promising approach for training reinforcement learning agents in a safe and sample-efficient manner. Recent world models predominantly operate on sequences of discrete latent variables to model environment dynamics. However, this compression into a compact discrete representation may ignore visual details that are important for reinforcement learning. Concurrently, diffusion models have become a dominant approach for image generation, challenging well-established methods modeling discrete latents. Motivated by this paradigm shift, we introduce DIAMOND (DIffusion As a Model Of eNvironment Dreams), a reinforcement learning agent trained in a diffusion world model. We analyze the key design choices that are required to make diffusion suitable for world modeling, and demonstrate how improved visual details can lead to improved agent performance. DIAMOND achieves a mean human normalized score of 1.46 on the competitive Atari 100k benchmark; a new best for agents trained entirely within a world model. To foster future research on diffusion for world modeling, we release our code, agents and playable world models at https://github.com/eloialonso/diamond.
5/22/2024
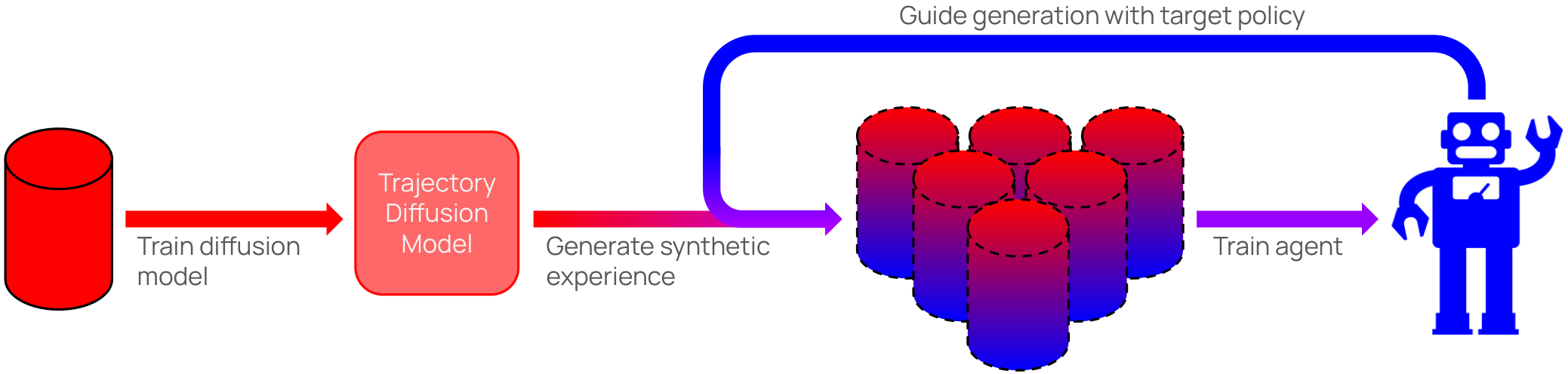
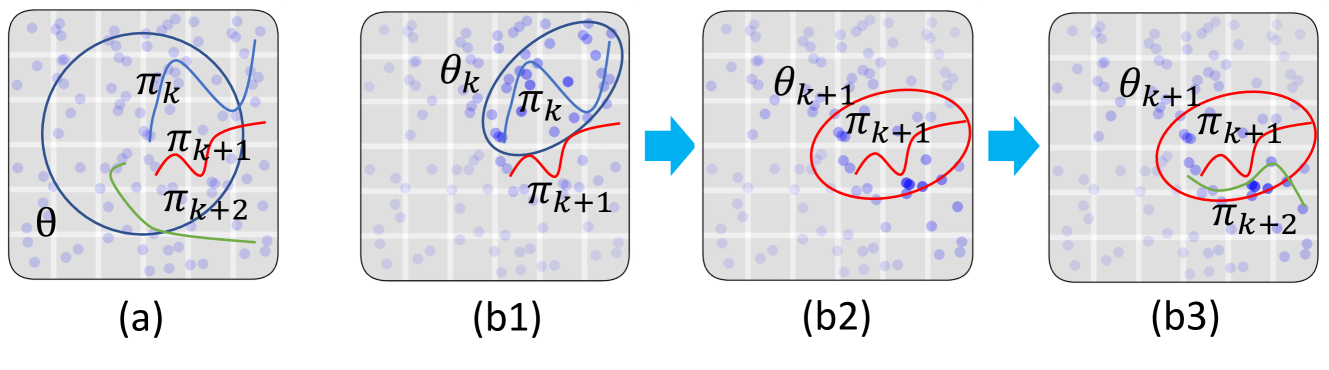
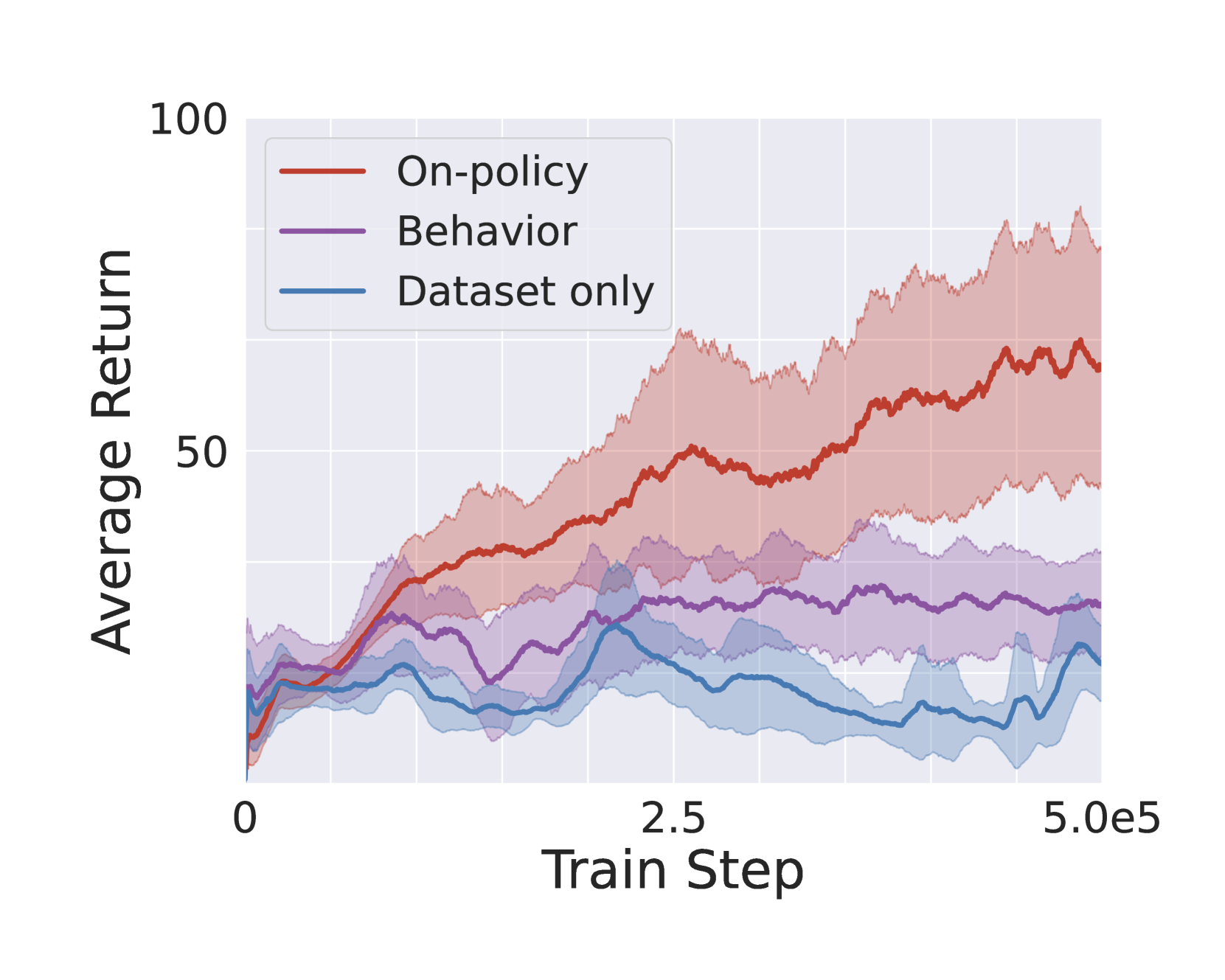
Policy-Guided Diffusion
Matthew Thomas Jackson, Michael Tryfan Matthews, Cong Lu, Benjamin Ellis, Shimon Whiteson, Jakob Foerster
0
0
In many real-world settings, agents must learn from an offline dataset gathered by some prior behavior policy. Such a setting naturally leads to distribution shift between the behavior policy and the target policy being trained - requiring policy conservatism to avoid instability and overestimation bias. Autoregressive world models offer a different solution to this by generating synthetic, on-policy experience. However, in practice, model rollouts must be severely truncated to avoid compounding error. As an alternative, we propose policy-guided diffusion. Our method uses diffusion models to generate entire trajectories under the behavior distribution, applying guidance from the target policy to move synthetic experience further on-policy. We show that policy-guided diffusion models a regularized form of the target distribution that balances action likelihood under both the target and behavior policies, leading to plausible trajectories with high target policy probability, while retaining a lower dynamics error than an offline world model baseline. Using synthetic experience from policy-guided diffusion as a drop-in substitute for real data, we demonstrate significant improvements in performance across a range of standard offline reinforcement learning algorithms and environments. Our approach provides an effective alternative to autoregressive offline world models, opening the door to the controllable generation of synthetic training data.
4/10/2024