Diffusion-based Dynamics Models for Long-Horizon Rollout in Offline Reinforcement Learning
2405.19189
0
0
Abstract
With the great success of diffusion models (DMs) in generating realistic synthetic vision data, many researchers have investigated their potential in decision-making and control. Most of these works utilized DMs to sample directly from the trajectory space, where DMs can be viewed as a combination of dynamics models and policies. In this work, we explore how to decouple DMs' ability as dynamics models in fully offline settings, allowing the learning policy to roll out trajectories. As DMs learn the data distribution from the dataset, their intrinsic policy is actually the behavior policy induced from the dataset, which results in a mismatch between the behavior policy and the learning policy. We propose Dynamics Diffusion, short as DyDiff, which can inject information from the learning policy to DMs iteratively. DyDiff ensures long-horizon rollout accuracy while maintaining policy consistency and can be easily deployed on model-free algorithms. We provide theoretical analysis to show the advantage of DMs on long-horizon rollout over models and demonstrate the effectiveness of DyDiff in the context of offline reinforcement learning, where the rollout dataset is provided but no online environment for interaction. Our code is at https://github.com/FineArtz/DyDiff.
Create account to get full access
Overview
• The provided paper explores the use of diffusion-based dynamics models for long-horizon rollout in offline reinforcement learning (RL) tasks.
• Offline RL aims to learn policies from pre-collected datasets without further interaction with the environment, which is crucial for real-world applications where data collection is expensive or dangerous.
• The key challenge in offline RL is accurately modeling long-term dynamics to enable reliable policy evaluation and optimization over long horizons.
• This paper proposes a novel approach that leverages diffusion-based generative models to capture the complex environment dynamics, enabling effective long-term policy rollout and evaluation.
Plain English Explanation
Reinforcement learning (RL) is a type of machine learning where an agent learns to make decisions by interacting with an environment and receiving rewards or punishments. In many real-world situations, such as robotics or medical treatments, it can be risky or costly to collect new data by having the agent directly interact with the environment. This is where offline RL comes in – it aims to learn policies (decision-making strategies) solely from pre-collected datasets, without any further interaction with the environment.
One of the key challenges in offline RL is accurately modeling the long-term dynamics of the environment, which is crucial for reliably evaluating and optimizing policies over long time horizons. This paper introduces a novel approach that uses diffusion-based generative models to capture these complex environment dynamics. Diffusion models are a type of machine learning model that can generate realistic-looking data by gradually adding noise to input data and then learning to reverse the process.
The researchers hypothesize that diffusion models can effectively learn the underlying patterns in the pre-collected dataset, enabling them to generate accurate long-term rollouts of the agent's behavior. By incorporating these diffusion-based dynamics models into the offline RL pipeline, the authors aim to improve the accuracy and reliability of policy evaluation and optimization, ultimately leading to better-performing policies that can be safely deployed in the real world.
Technical Explanation
The paper proposes a new approach for offline RL that leverages diffusion-based dynamics models to enable accurate long-horizon policy rollout and evaluation. The authors argue that accurately modeling the environment's long-term dynamics is a key challenge in offline RL, as it is crucial for reliable policy optimization over long time horizons.
To address this, the paper introduces a novel framework that integrates diffusion-based generative models into the offline RL pipeline. Diffusion models are trained to learn the underlying data distribution by gradually adding noise to input data and then learning to reverse the process, enabling them to generate realistic-looking samples. The researchers hypothesize that diffusion models can effectively capture the complex environment dynamics present in the pre-collected offline dataset, leading to more accurate long-term rollouts of the agent's behavior.
The proposed approach involves training a diffusion-based dynamics model in parallel with the RL policy optimization. The dynamics model is used to generate long-term rollouts, which are then leveraged to improve the policy evaluation and optimization process. The authors demonstrate the effectiveness of their approach through experiments on several challenging offline RL benchmarks, showing significant performance improvements over existing offline RL methods.
Critical Analysis
The paper presents a compelling approach to addressing a key challenge in offline RL – the accurate modeling of long-term environment dynamics. The use of diffusion-based generative models is a novel and promising direction, as these models have shown impressive abilities to capture complex data distributions in various domains.
However, the paper does not discuss potential limitations or caveats of the proposed approach. For example, the performance of the diffusion-based dynamics model may be sensitive to the quality and diversity of the pre-collected offline dataset, which could be a concern in real-world scenarios where data collection is challenging. Additionally, the computational and memory requirements of the diffusion model training and rollout generation may limit the scalability of the approach, especially for large-scale or high-dimensional environments.
Further research is needed to investigate the robustness and generalizability of the proposed method, as well as to explore potential ways to mitigate any identified limitations. Comparative studies with other long-horizon modeling techniques, such as Policy-Guided Diffusion or Preferred Action Optimized Diffusion Policies for Offline Reinforcement Learning, could also provide valuable insights into the strengths and weaknesses of the diffusion-based approach.
Conclusion
This paper presents a novel approach for offline reinforcement learning that leverages diffusion-based generative models to capture the complex long-term dynamics of the environment. By integrating these diffusion-based dynamics models into the offline RL pipeline, the authors aim to enable accurate long-horizon policy rollout and evaluation, ultimately leading to better-performing policies that can be safely deployed in real-world applications.
The key contribution of this work is the innovative use of diffusion models to address a critical challenge in offline RL, which has important implications for a wide range of applications where direct interaction with the environment is costly or dangerous. While the paper shows promising results, further research is needed to fully understand the strengths, limitations, and practical considerations of this approach. Nonetheless, this work represents an exciting step forward in the field of offline reinforcement learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📊
MADiff: Offline Multi-agent Learning with Diffusion Models
Zhengbang Zhu, Minghuan Liu, Liyuan Mao, Bingyi Kang, Minkai Xu, Yong Yu, Stefano Ermon, Weinan Zhang
0
0
Diffusion model (DM) recently achieved huge success in various scenarios including offline reinforcement learning, where the diffusion planner learn to generate desired trajectories during online evaluations. However, despite the effectiveness in single-agent learning, it remains unclear how DMs can operate in multi-agent problems, where agents can hardly complete teamwork without good coordination by independently modeling each agent's trajectories. In this paper, we propose MADiff, a novel generative multi-agent learning framework to tackle this problem. MADiff is realized with an attention-based diffusion model to model the complex coordination among behaviors of multiple agents. To the best of our knowledge, MADiff is the first diffusion-based multi-agent learning framework, which behaves as both a decentralized policy and a centralized controller. During decentralized executions, MADiff simultaneously performs teammate modeling, and the centralized controller can also be applied in multi-agent trajectory predictions. Our experiments show the superior performance of MADiff compared to baseline algorithms in a wide range of multi-agent learning tasks, which emphasizes the effectiveness of MADiff in modeling complex multi-agent interactions. Our code is available at https://github.com/zbzhu99/madiff.
5/28/2024

Diffusion World Model: Future Modeling Beyond Step-by-Step Rollout for Offline Reinforcement Learning
Zihan Ding, Amy Zhang, Yuandong Tian, Qinqing Zheng
0
0
We introduce Diffusion World Model (DWM), a conditional diffusion model capable of predicting multistep future states and rewards concurrently. As opposed to traditional one-step dynamics models, DWM offers long-horizon predictions in a single forward pass, eliminating the need for recursive queries. We integrate DWM into model-based value estimation, where the short-term return is simulated by future trajectories sampled from DWM. In the context of offline reinforcement learning, DWM can be viewed as a conservative value regularization through generative modeling. Alternatively, it can be seen as a data source that enables offline Q-learning with synthetic data. Our experiments on the D4RL dataset confirm the robustness of DWM to long-horizon simulation. In terms of absolute performance, DWM significantly surpasses one-step dynamics models with a $44%$ performance gain, and is comparable to or slightly surpassing their model-free counterparts.
6/18/2024
Learning from Random Demonstrations: Offline Reinforcement Learning with Importance-Sampled Diffusion Models
Zeyu Fang, Tian Lan
0
0
Generative models such as diffusion have been employed as world models in offline reinforcement learning to generate synthetic data for more effective learning. Existing work either generates diffusion models one-time prior to training or requires additional interaction data to update it. In this paper, we propose a novel approach for offline reinforcement learning with closed-loop policy evaluation and world-model adaptation. It iteratively leverages a guided diffusion world model to directly evaluate the offline target policy with actions drawn from it, and then performs an importance-sampled world model update to adaptively align the world model with the updated policy. We analyzed the performance of the proposed method and provided an upper bound on the return gap between our method and the real environment under an optimal policy. The result sheds light on various factors affecting learning performance. Evaluations in the D4RL environment show significant improvement over state-of-the-art baselines, especially when only random or medium-expertise demonstrations are available -- thus requiring improved alignment between the world model and offline policy evaluation.
5/31/2024
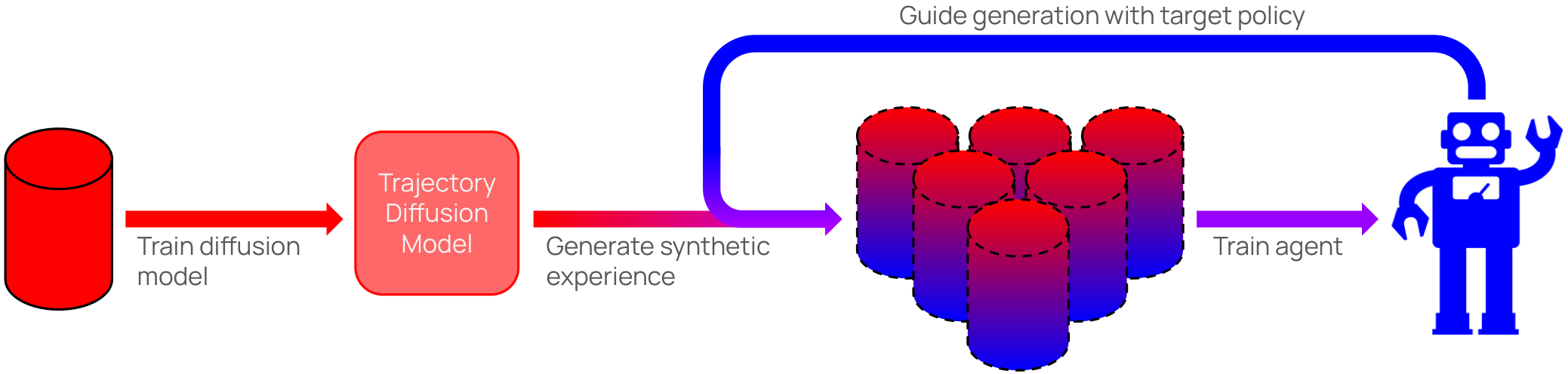
Policy-Guided Diffusion
Matthew Thomas Jackson, Michael Tryfan Matthews, Cong Lu, Benjamin Ellis, Shimon Whiteson, Jakob Foerster
0
0
In many real-world settings, agents must learn from an offline dataset gathered by some prior behavior policy. Such a setting naturally leads to distribution shift between the behavior policy and the target policy being trained - requiring policy conservatism to avoid instability and overestimation bias. Autoregressive world models offer a different solution to this by generating synthetic, on-policy experience. However, in practice, model rollouts must be severely truncated to avoid compounding error. As an alternative, we propose policy-guided diffusion. Our method uses diffusion models to generate entire trajectories under the behavior distribution, applying guidance from the target policy to move synthetic experience further on-policy. We show that policy-guided diffusion models a regularized form of the target distribution that balances action likelihood under both the target and behavior policies, leading to plausible trajectories with high target policy probability, while retaining a lower dynamics error than an offline world model baseline. Using synthetic experience from policy-guided diffusion as a drop-in substitute for real data, we demonstrate significant improvements in performance across a range of standard offline reinforcement learning algorithms and environments. Our approach provides an effective alternative to autoregressive offline world models, opening the door to the controllable generation of synthetic training data.
4/10/2024