Benchmarking AIGC Video Quality Assessment: A Dataset and Unified Model

0

Sign in to get full access
Overview
- The paper presents a new dataset and unified model for benchmarking AI-generated content (AIGC) video quality assessment.
- The dataset, called AIGC-VQA, contains a diverse set of AIGC videos with corresponding subjective quality scores.
- The authors also propose a unified model that can effectively assess the quality of AIGC videos.
Plain English Explanation
The researchers have developed a new way to evaluate the quality of AI-generated videos. This is important because as AI technology advances, there will be more and more AI-created videos out there, and we need a reliable way to measure how good they are.
The researchers created a dataset of AIGC videos and had people watch and rate the quality of these videos. This dataset, called AIGC-VQA, provides a benchmark that can be used to test different methods for assessing video quality.
The researchers also developed a unified model that can analyze AIGC videos and give them a quality score. This model takes into account various factors that contribute to video quality, like visual harmony, and can provide a more comprehensive assessment than previous methods.
Overall, this work provides important tools for evaluating the quality of AI-generated videos, which will become increasingly relevant as AIGC technologies continue to advance. These tools can help ensure that AI-created videos meet high standards and are useful for a variety of applications.
Technical Explanation
The paper introduces the AIGC-VQA dataset, which consists of a diverse set of AIGC videos with corresponding subjective quality scores obtained through crowdsourcing. The dataset covers a range of video genres, including animation, gaming, and real-world footage, and includes both high and low-quality samples.
To address the task of AIGC video quality assessment, the authors propose a unified model that combines multiple quality assessment modules, such as those focused on visual harmony, object quality, and temporal consistency. This model is trained on the AIGC-VQA dataset and can provide a comprehensive evaluation of AIGC video quality.
The paper also presents extensive experiments and analyses to benchmark the performance of the proposed unified model and compare it to existing video quality assessment methods. The results demonstrate the effectiveness of the unified model in accurately predicting the subjective quality of AIGC videos, outperforming state-of-the-art approaches.
Critical Analysis
The paper provides a valuable contribution to the field of AIGC video quality assessment by introducing a high-quality dataset and a unified model that can effectively evaluate the quality of AI-generated videos. However, the authors acknowledge that the dataset is limited in size and may not capture the full diversity of AIGC videos that could emerge in the future.
Additionally, the paper does not address potential biases or limitations in the crowdsourcing process used to collect the subjective quality scores. It would be important to consider how factors such as viewer demographics, video content, and task design might impact the reliability and generalizability of the subjective ratings.
Further research could explore the robustness of the unified model to various types of AIGC videos, including those generated by different AI systems or in different domains. Investigating the model's ability to generalize to unseen video content or to handle emerging AIGC technologies would help validate its long-term utility.
Conclusion
This paper presents a significant step forward in the assessment of AIGC video quality. The AIGC-VQA dataset and the proposed unified model provide a robust framework for benchmarking and evaluating the performance of AI-generated videos. These tools can contribute to the development of more reliable and high-quality AIGC systems, ultimately benefiting a wide range of applications and industries that rely on video content.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Benchmarking AIGC Video Quality Assessment: A Dataset and Unified Model
Zhichao Zhang, Xinyue Li, Wei Sun, Jun Jia, Xiongkuo Min, Zicheng Zhang, Chunyi Li, Zijian Chen, Puyi Wang, Zhongpeng Ji, Fengyu Sun, Shangling Jui, Guangtao Zhai
In recent years, artificial intelligence (AI) driven video generation has garnered significant attention due to advancements in stable diffusion and large language model techniques. Thus, there is a great demand for accurate video quality assessment (VQA) models to measure the perceptual quality of AI-generated content (AIGC) videos as well as optimize video generation techniques. However, assessing the quality of AIGC videos is quite challenging due to the highly complex distortions they exhibit (e.g., unnatural action, irrational objects, etc.). Therefore, in this paper, we try to systemically investigate the AIGC-VQA problem from both subjective and objective quality assessment perspectives. For the subjective perspective, we construct a Large-scale Generated Vdeo Quality assessment (LGVQ) dataset, consisting of 2,808 AIGC videos generated by 6 video generation models using 468 carefully selected text prompts. Unlike previous subjective VQA experiments, we evaluate the perceptual quality of AIGC videos from three dimensions: spatial quality, temporal quality, and text-to-video alignment, which hold utmost importance for current video generation techniques. For the objective perspective, we establish a benchmark for evaluating existing quality assessment metrics on the LGVQ dataset, which reveals that current metrics perform poorly on the LGVQ dataset. Thus, we propose a Unify Generated Video Quality assessment (UGVQ) model to comprehensively and accurately evaluate the quality of AIGC videos across three aspects using a unified model, which uses visual, textual and motion features of video and corresponding prompt, and integrates key features to enhance feature expression. We hope that our benchmark can promote the development of quality evaluation metrics for AIGC videos. The LGVQ dataset and the UGVQ metric will be publicly released.
Read more8/1/2024

0
Exploring AIGC Video Quality: A Focus on Visual Harmony, Video-Text Consistency and Domain Distribution Gap
Bowen Qu, Xiaoyu Liang, Shangkun Sun, Wei Gao
The recent advancements in Text-to-Video Artificial Intelligence Generated Content (AIGC) have been remarkable. Compared with traditional videos, the assessment of AIGC videos encounters various challenges: visual inconsistency that defy common sense, discrepancies between content and the textual prompt, and distribution gap between various generative models, etc. Target at these challenges, in this work, we categorize the assessment of AIGC video quality into three dimensions: visual harmony, video-text consistency, and domain distribution gap. For each dimension, we design specific modules to provide a comprehensive quality assessment of AIGC videos. Furthermore, our research identifies significant variations in visual quality, fluidity, and style among videos generated by different text-to-video models. Predicting the source generative model can make the AIGC video features more discriminative, which enhances the quality assessment performance. The proposed method was used in the third-place winner of the NTIRE 2024 Quality Assessment for AI-Generated Content - Track 2 Video, demonstrating its effectiveness. Code will be available at https://github.com/Coobiw/TriVQA.
Read more4/30/2024
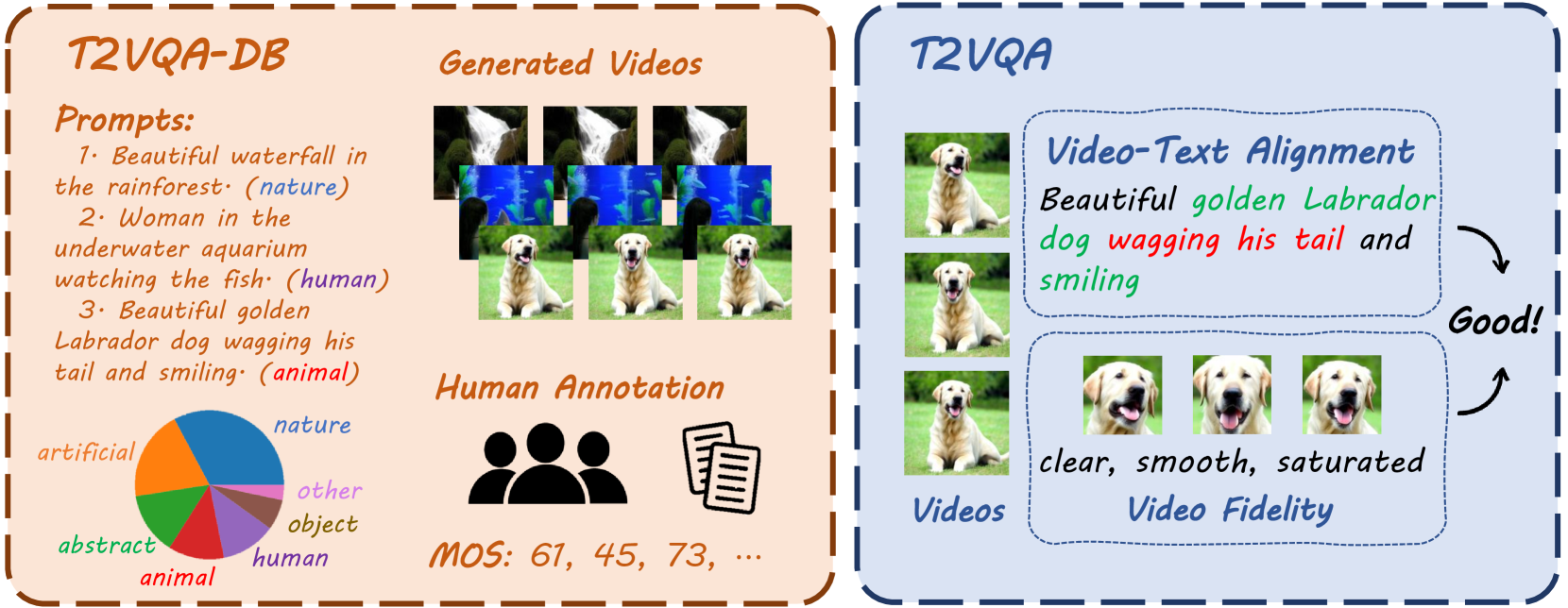
0
Subjective-Aligned Dataset and Metric for Text-to-Video Quality Assessment
Tengchuan Kou, Xiaohong Liu, Zicheng Zhang, Chunyi Li, Haoning Wu, Xiongkuo Min, Guangtao Zhai, Ning Liu
With the rapid development of generative models, Artificial Intelligence-Generated Contents (AIGC) have exponentially increased in daily lives. Among them, Text-to-Video (T2V) generation has received widespread attention. Though many T2V models have been released for generating high perceptual quality videos, there is still lack of a method to evaluate the quality of these videos quantitatively. To solve this issue, we establish the largest-scale Text-to-Video Quality Assessment DataBase (T2VQA-DB) to date. The dataset is composed of 10,000 videos generated by 9 different T2V models. We also conduct a subjective study to obtain each video's corresponding mean opinion score. Based on T2VQA-DB, we propose a novel transformer-based model for subjective-aligned Text-to-Video Quality Assessment (T2VQA). The model extracts features from text-video alignment and video fidelity perspectives, then it leverages the ability of a large language model to give the prediction score. Experimental results show that T2VQA outperforms existing T2V metrics and SOTA video quality assessment models. Quantitative analysis indicates that T2VQA is capable of giving subjective-align predictions, validating its effectiveness. The dataset and code will be released at https://github.com/QMME/T2VQA.
Read more8/9/2024

0
AIS 2024 Challenge on Video Quality Assessment of User-Generated Content: Methods and Results
Marcos V. Conde, Saman Zadtootaghaj, Nabajeet Barman, Radu Timofte, Chenlong He, Qi Zheng, Ruoxi Zhu, Zhengzhong Tu, Haiqiang Wang, Xiangguang Chen, Wenhui Meng, Xiang Pan, Huiying Shi, Han Zhu, Xiaozhong Xu, Lei Sun, Zhenzhong Chen, Shan Liu, Zicheng Zhang, Haoning Wu, Yingjie Zhou, Chunyi Li, Xiaohong Liu, Weisi Lin, Guangtao Zhai, Wei Sun, Yuqin Cao, Yanwei Jiang, Jun Jia, Zhichao Zhang, Zijian Chen, Weixia Zhang, Xiongkuo Min, Steve Goring, Zihao Qi, Chen Feng
This paper reviews the AIS 2024 Video Quality Assessment (VQA) Challenge, focused on User-Generated Content (UGC). The aim of this challenge is to gather deep learning-based methods capable of estimating the perceptual quality of UGC videos. The user-generated videos from the YouTube UGC Dataset include diverse content (sports, games, lyrics, anime, etc.), quality and resolutions. The proposed methods must process 30 FHD frames under 1 second. In the challenge, a total of 102 participants registered, and 15 submitted code and models. The performance of the top-5 submissions is reviewed and provided here as a survey of diverse deep models for efficient video quality assessment of user-generated content.
Read more4/26/2024