GAIA: Rethinking Action Quality Assessment for AI-Generated Videos

0
Sign in to get full access
Overview
- The paper "GAIA: Rethinking Action Quality Assessment for AI-Generated Videos" presents a new framework for evaluating the quality of actions in AI-generated videos.
- The authors argue that existing approaches to action quality assessment are limited and propose a more comprehensive and objective evaluation method.
- The framework, called GAIA, combines visual, semantic, and physical features to holistically assess the quality of actions in AI-generated content.
Plain English Explanation
The paper discusses a new way to evaluate the quality of actions in videos created by AI systems. The authors believe that current methods for assessing action quality are not good enough. They've developed a framework called GAIA that looks at different aspects of the video, including the visual elements, the meaning behind the actions, and how physically realistic they are. The goal is to get a more complete and objective understanding of the quality of the actions in AI-generated content. This could be helpful for improving the capabilities of AI video generation systems and ensuring the actions they create look and feel natural.
Technical Explanation
The paper proposes the GAIA framework for assessing the quality of actions in AI-generated videos. GAIA combines three key components: visual features, semantic features, and physical features. The visual features evaluate the realism and coherence of the visual elements, such as the movement and appearance of the characters. The semantic features assess the meaning and intention behind the actions, ensuring they are appropriate and meaningful. The physical features analyze the plausibility and dynamics of the actions, checking that they obey the laws of physics.
The authors conduct experiments to validate the GAIA framework, testing it on a dataset of AI-generated videos. They compare GAIA's performance to existing action quality assessment approaches and find that it provides a more comprehensive and accurate evaluation. The results suggest GAIA can effectively identify high-quality actions and distinguish them from lower-quality ones.
Critical Analysis
The paper presents a thoughtful and well-designed framework for assessing action quality in AI-generated videos. The combination of visual, semantic, and physical features is a promising approach to objectively evaluating the realism and coherence of the generated content.
However, the paper does not address the potential limitations of the GAIA framework. For example, it's unclear how the framework would handle highly stylized or abstract AI-generated videos, where the laws of physics may not be as relevant. Additionally, the reliance on predefined metrics and datasets raises questions about the generalizability of the approach to diverse types of AI-generated content.
Further research could explore the application of GAIA to a wider range of AI video generation systems and investigate ways to make the assessment more adaptive and context-aware. Incorporating user feedback and subjective evaluations could also strengthen the framework's ability to capture nuanced aspects of action quality.
Conclusion
The "GAIA: Rethinking Action Quality Assessment for AI-Generated Videos" paper presents a promising framework for evaluating the quality of actions in AI-generated videos. By combining visual, semantic, and physical features, the GAIA approach offers a more comprehensive and objective assessment compared to existing methods. The experimental results suggest GAIA can effectively identify high-quality actions, which could aid in the development of more advanced and realistic AI video generation systems. While the paper highlights the potential of the GAIA framework, further research is needed to address its limitations and explore ways to make the assessment more adaptable and aligned with human perceptions of action quality.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
GAIA: Rethinking Action Quality Assessment for AI-Generated Videos
Zijian Chen, Wei Sun, Yuan Tian, Jun Jia, Zicheng Zhang, Jiarui Wang, Ru Huang, Xiongkuo Min, Guangtao Zhai, Wenjun Zhang
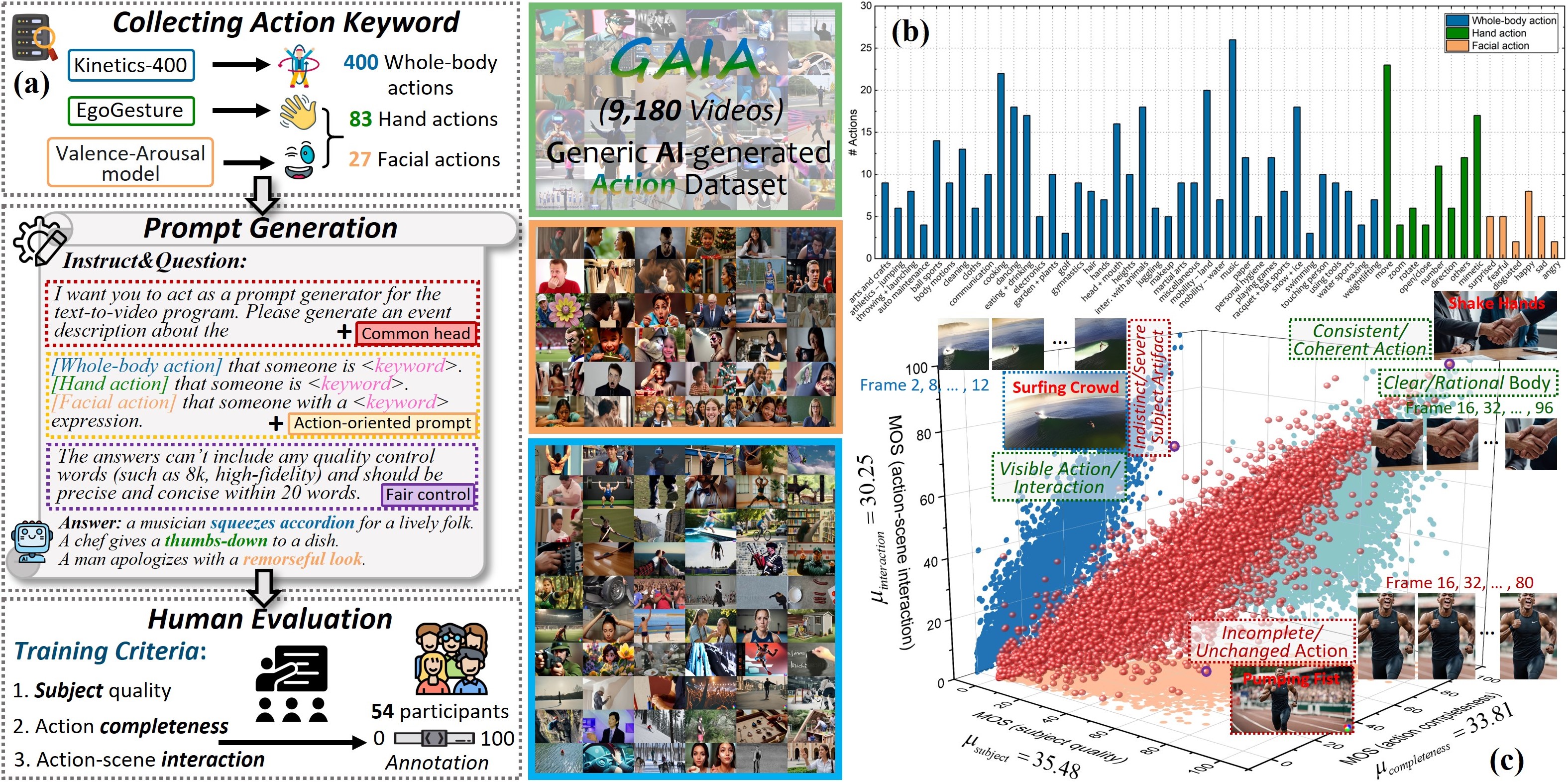
Assessing action quality is both imperative and challenging due to its significant impact on the quality of AI-generated videos, further complicated by the inherently ambiguous nature of actions within AI-generated video (AIGV). Current action quality assessment (AQA) algorithms predominantly focus on actions from real specific scenarios and are pre-trained with normative action features, thus rendering them inapplicable in AIGVs. To address these problems, we construct GAIA, a Generic AI-generated Action dataset, by conducting a large-scale subjective evaluation from a novel causal reasoning-based perspective, resulting in 971,244 ratings among 9,180 video-action pairs. Based on GAIA, we evaluate a suite of popular text-to-video (T2V) models on their ability to generate visually rational actions, revealing their pros and cons on different categories of actions. We also extend GAIA as a testbed to benchmark the AQA capacity of existing automatic evaluation methods. Results show that traditional AQA methods, action-related metrics in recent T2V benchmarks, and mainstream video quality methods correlate poorly with human opinions, indicating a sizable gap between current models and human action perception patterns in AIGVs. Our findings underscore the significance of action quality as a unique perspective for studying AIGVs and can catalyze progress towards methods with enhanced capacities for AQA in AIGVs.
Read more6/11/2024

0
Benchmarking AIGC Video Quality Assessment: A Dataset and Unified Model
Zhichao Zhang, Xinyue Li, Wei Sun, Jun Jia, Xiongkuo Min, Zicheng Zhang, Chunyi Li, Zijian Chen, Puyi Wang, Zhongpeng Ji, Fengyu Sun, Shangling Jui, Guangtao Zhai
In recent years, artificial intelligence (AI) driven video generation has garnered significant attention due to advancements in stable diffusion and large language model techniques. Thus, there is a great demand for accurate video quality assessment (VQA) models to measure the perceptual quality of AI-generated content (AIGC) videos as well as optimize video generation techniques. However, assessing the quality of AIGC videos is quite challenging due to the highly complex distortions they exhibit (e.g., unnatural action, irrational objects, etc.). Therefore, in this paper, we try to systemically investigate the AIGC-VQA problem from both subjective and objective quality assessment perspectives. For the subjective perspective, we construct a Large-scale Generated Vdeo Quality assessment (LGVQ) dataset, consisting of 2,808 AIGC videos generated by 6 video generation models using 468 carefully selected text prompts. Unlike previous subjective VQA experiments, we evaluate the perceptual quality of AIGC videos from three dimensions: spatial quality, temporal quality, and text-to-video alignment, which hold utmost importance for current video generation techniques. For the objective perspective, we establish a benchmark for evaluating existing quality assessment metrics on the LGVQ dataset, which reveals that current metrics perform poorly on the LGVQ dataset. Thus, we propose a Unify Generated Video Quality assessment (UGVQ) model to comprehensively and accurately evaluate the quality of AIGC videos across three aspects using a unified model, which uses visual, textual and motion features of video and corresponding prompt, and integrates key features to enhance feature expression. We hope that our benchmark can promote the development of quality evaluation metrics for AIGC videos. The LGVQ dataset and the UGVQ metric will be publicly released.
Read more8/1/2024

0
Hierarchical NeuroSymbolic Approach for Comprehensive and Explainable Action Quality Assessment
Lauren Okamoto, Paritosh Parmar
Action quality assessment (AQA) applies computer vision to quantitatively assess the performance or execution of a human action. Current AQA approaches are end-to-end neural models, which lack transparency and tend to be biased because they are trained on subjective human judgements as ground-truth. To address these issues, we introduce a neuro-symbolic paradigm for AQA, which uses neural networks to abstract interpretable symbols from video data and makes quality assessments by applying rules to those symbols. We take diving as the case study. We found that domain experts prefer our system and find it more informative than purely neural approaches to AQA in diving. Our system also achieves state-of-the-art action recognition and temporal segmentation, and automatically generates a detailed report that breaks the dive down into its elements and provides objective scoring with visual evidence. As verified by a group of domain experts, this report may be used to assist judges in scoring, help train judges, and provide feedback to divers. Annotated training data and code: https://github.com/laurenok24/NSAQA.
Read more5/27/2024

0
Interpretable Long-term Action Quality Assessment
Xu Dong, Xinran Liu, Wanqing Li, Anthony Adeyemi-Ejeye, Andrew Gilbert
Long-term Action Quality Assessment (AQA) evaluates the execution of activities in videos. However, the length presents challenges in fine-grained interpretability, with current AQA methods typically producing a single score by averaging clip features, lacking detailed semantic meanings of individual clips. Long-term videos pose additional difficulty due to the complexity and diversity of actions, exacerbating interpretability challenges. While query-based transformer networks offer promising long-term modeling capabilities, their interpretability in AQA remains unsatisfactory due to a phenomenon we term Temporal Skipping, where the model skips self-attention layers to prevent output degradation. To address this, we propose an attention loss function and a query initialization method to enhance performance and interpretability. Additionally, we introduce a weight-score regression module designed to approximate the scoring patterns observed in human judgments and replace conventional single-score regression, improving the rationality of interpretability. Our approach achieves state-of-the-art results on three real-world, long-term AQA benchmarks. Our code is available at: https://github.com/dx199771/Interpretability-AQA
Read more8/22/2024