Benchmarking Edge AI Platforms for High-Performance ML Inference

0

Sign in to get full access
Overview
- Benchmarks the performance of different edge AI platforms for high-performance machine learning (ML) inference
- Evaluates the capabilities of various neural processing units (NPUs) and heterogeneous computing systems for running complex ML models on edge devices
- Explores the tradeoffs between performance, power efficiency, and cost for deploying ML inference at the edge
Plain English Explanation
This paper investigates the suitability of different hardware platforms for running powerful machine learning models on edge devices, such as smartphones or smart home gadgets. The researchers benchmarked the performance of various neural processing units (NPUs) and heterogeneous computing systems to see how well they could handle complex neural network inference at the edge.
The goal was to understand the tradeoffs between factors like speed, power efficiency, and cost when deploying these advanced ML models on resource-constrained edge devices rather than more powerful cloud servers. This is an important consideration as more and more AI applications move computation closer to the data source to reduce latency and bandwidth requirements.
Technical Explanation
The researchers conducted extensive benchmarking of different edge AI platforms, including standalone NPUs as well as heterogeneous systems combining NPUs with traditional CPUs and GPUs. They evaluated the platforms' performance on a range of common ML tasks and models, measuring metrics like inference latency, throughput, energy efficiency, and cost.
The results showed significant variation in the capabilities of the different hardware configurations. Some specialized NPUs excelled at particular model types or workloads, while more versatile heterogeneous systems offered a balance of performance across a broader set of applications. The paper provides detailed analysis of the strengths and tradeoffs of the evaluated platforms to help guide deployment decisions for edge AI.
Critical Analysis
The paper provides a comprehensive, data-driven assessment of the current state of edge AI hardware, which is crucial as more computing shifts from the cloud to the edge. However, the benchmark results are limited to the specific hardware and software configurations tested. As new generations of edge devices and ML models emerge, the relative performance and suitability of the platforms could change.
Additionally, the paper does not delve deeply into the architectural details or low-level optimizations that enable the differing performance characteristics. Further research is needed to fully understand the underlying mechanisms and identify opportunities for future improvements in edge AI hardware.
Conclusion
This benchmarking study offers valuable insights for developers and organizations looking to deploy advanced machine learning applications on resource-constrained edge devices. By exploring the tradeoffs between performance, power efficiency, and cost across a range of hardware platforms, the paper helps inform the design of effective edge AI systems that can bring the benefits of high-performance ML inference closer to the point of data generation and use.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Benchmarking Edge AI Platforms for High-Performance ML Inference
Rakshith Jayanth, Neelesh Gupta, Viktor Prasanna
Edge computing's growing prominence, due to its ability to reduce communication latency and enable real-time processing, is promoting the rise of high-performance, heterogeneous System-on-Chip solutions. While current approaches often involve scaling down modern hardware, the performance characteristics of neural network workloads on these platforms can vary significantly, especially when it comes to parallel processing, which is a critical consideration for edge deployments. To address this, we conduct a comprehensive study comparing the latency and throughput of various linear algebra and neural network inference tasks across CPU-only, CPU/GPU, and CPU/NPU integrated solutions. {We find that the Neural Processing Unit (NPU) excels in matrix-vector multiplication (58.6% faster) and some neural network tasks (3.2$times$ faster for video classification and large language models). GPU outperforms in matrix multiplication (22.6% faster) and LSTM networks (2.7$times$ faster) while CPU excels at less parallel operations like dot product. NPU-based inference offers a balance of latency and throughput at lower power consumption. GPU-based inference, though more energy-intensive, performs best with large dimensions and batch sizes. We highlight the potential of heterogeneous computing solutions for edge AI, where diverse compute units can be strategically leveraged to boost accurate and real-time inference.
Read more9/24/2024
🤯
0
Inference Acceleration for Large Language Models on CPUs
Ditto PS, Jithin VG, Adarsh MS
In recent years, large language models have demonstrated remarkable performance across various natural language processing (NLP) tasks. However, deploying these models for real-world applications often requires efficient inference solutions to handle the computational demands. In this paper, we explore the utilization of CPUs for accelerating the inference of large language models. Specifically, we introduce a parallelized approach to enhance throughput by 1) Exploiting the parallel processing capabilities of modern CPU architectures, 2) Batching the inference request. Our evaluation shows the accelerated inference engine gives an 18-22x improvement in the generated token per sec. The improvement is more with longer sequence and larger models. In addition to this, we can also run multiple workers in the same machine with NUMA node isolation to further improvement in tokens/s. Table 2, we have received 4x additional improvement with 4 workers. This would also make Gen-AI based products and companies environment friendly, our estimates shows that CPU usage for Inference could reduce the power consumption of LLMs by 48.9% while providing production ready throughput and latency.
Read more6/13/2024
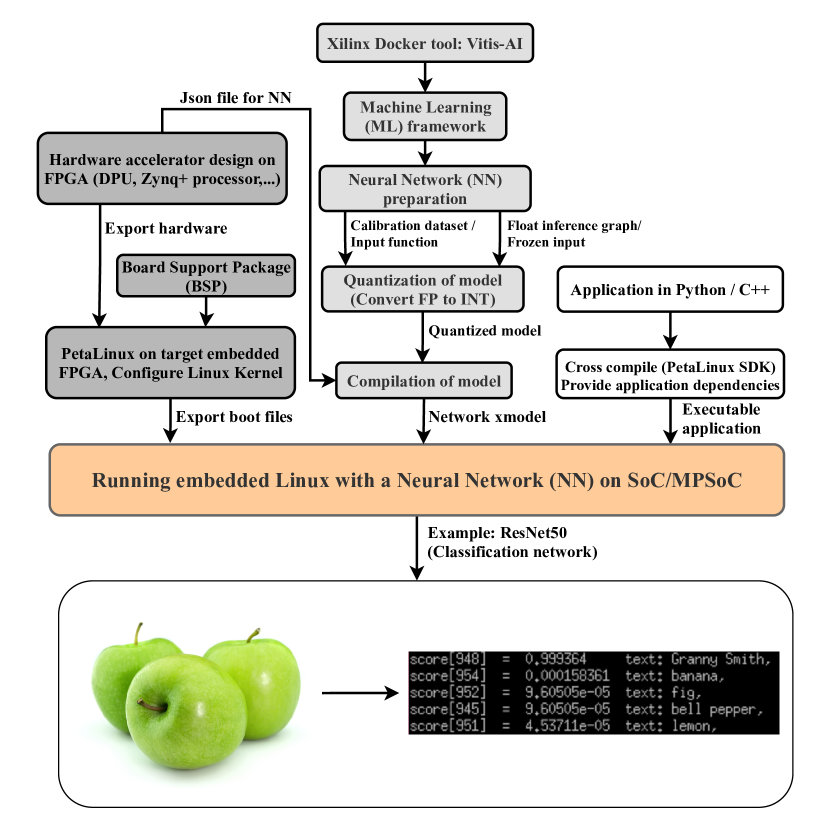
0
Latency optimized Deep Neural Networks (DNNs): An Artificial Intelligence approach at the Edge using Multiprocessor System on Chip (MPSoC)
Seyed Nima Omidsajedi, Rekha Reddy, Jianming Yi, Jan Herbst, Christoph Lipps, Hans Dieter Schotten
Almost in every heavily computation-dependent application, from 6G communication systems to autonomous driving platforms, a large portion of computing should be near to the client side. Edge computing (AI at Edge) in mobile devices is one of the optimized approaches for addressing this requirement. Therefore, in this work, the possibilities and challenges of implementing a low-latency and power-optimized smart mobile system are examined. Utilizing Field Programmable Gate Array (FPGA) based solutions at the edge will lead to bandwidth-optimized designs and as a consequence can boost the computational effectiveness at a system-level deadline. Moreover, various performance aspects and implementation feasibilities of Neural Networks (NNs) on both embedded FPGA edge devices (using Xilinx Multiprocessor System on Chip (MPSoC)) and Cloud are discussed throughout this research. The main goal of this work is to demonstrate a hybrid system that uses the deep learning programmable engine developed by Xilinx Inc. as the main component of the hardware accelerator. Then based on this design, an efficient system for mobile edge computing is represented by utilizing an embedded solution.
Read more7/29/2024
0
Hardware-Assisted Virtualization of Neural Processing Units for Cloud Platforms
Yuqi Xue, Yiqi Liu, Lifeng Nai, Jian Huang
Cloud platforms today have been deploying hardware accelerators like neural processing units (NPUs) for powering machine learning (ML) inference services. To maximize the resource utilization while ensuring reasonable quality of service, a natural approach is to virtualize NPUs for efficient resource sharing for multi-tenant ML services. However, virtualizing NPUs for modern cloud platforms is not easy. This is not only due to the lack of system abstraction support for NPU hardware, but also due to the lack of architectural and ISA support for enabling fine-grained dynamic operator scheduling for virtualized NPUs. We present Neu10, a holistic NPU virtualization framework. We investigate virtualization techniques for NPUs across the entire software and hardware stack. Neu10 consists of (1) a flexible NPU abstraction called vNPU, which enables fine-grained virtualization of the heterogeneous compute units in a physical NPU (pNPU); (2) a vNPU resource allocator that enables pay-as-you-go computing model and flexible vNPU-to-pNPU mappings for improved resource utilization and cost-effectiveness; (3) an ISA extension of modern NPU architecture for facilitating fine-grained tensor operator scheduling for multiple vNPUs. We implement Neu10 based on a production-level NPU simulator. Our experiments show that Neu10 improves the throughput of ML inference services by up to 1.4$times$ and reduces the tail latency by up to 4.6$times$, while improving the NPU utilization by 1.2$times$ on average, compared to state-of-the-art NPU sharing approaches.
Read more9/16/2024