Fact-Checking the Output of Large Language Models via Token-Level Uncertainty Quantification
2403.04696
0
0
Abstract
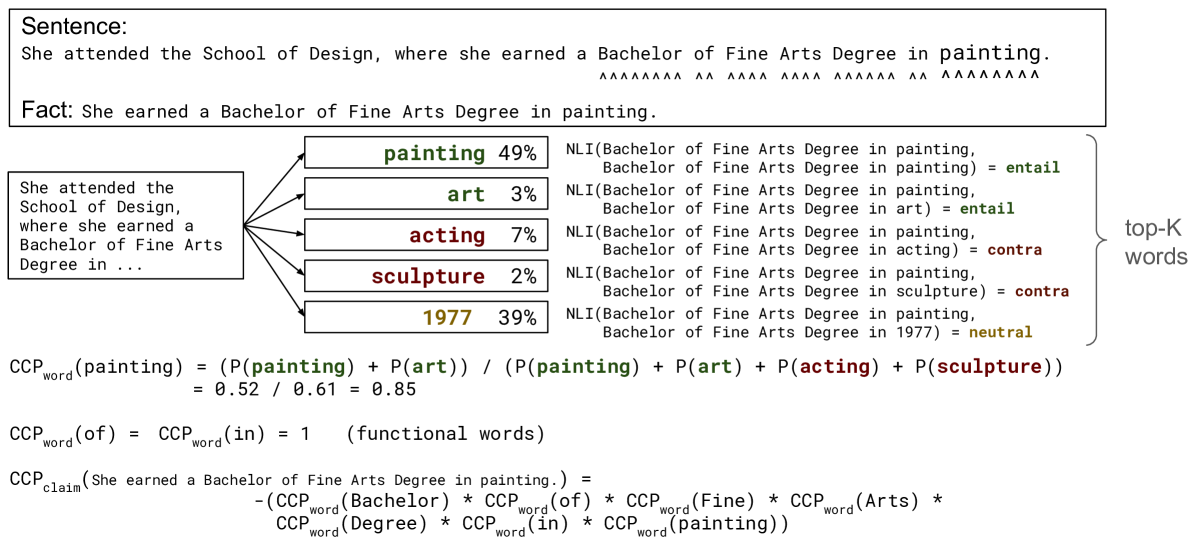
Large language models (LLMs) are notorious for hallucinating, i.e., producing erroneous claims in their output. Such hallucinations can be dangerous, as occasional factual inaccuracies in the generated text might be obscured by the rest of the output being generally factually correct, making it extremely hard for the users to spot them. Current services that leverage LLMs usually do not provide any means for detecting unreliable generations. Here, we aim to bridge this gap. In particular, we propose a novel fact-checking and hallucination detection pipeline based on token-level uncertainty quantification. Uncertainty scores leverage information encapsulated in the output of a neural network or its layers to detect unreliable predictions, and we show that they can be used to fact-check the atomic claims in the LLM output. Moreover, we present a novel token-level uncertainty quantification method that removes the impact of uncertainty about what claim to generate on the current step and what surface form to use. Our method Claim Conditioned Probability (CCP) measures only the uncertainty of a particular claim value expressed by the model. Experiments on the task of biography generation demonstrate strong improvements for CCP compared to the baselines for seven LLMs and four languages. Human evaluation reveals that the fact-checking pipeline based on uncertainty quantification is competitive with a fact-checking tool that leverages external knowledge.
Create account to get full access
Overview
- This paper presents a method for fact-checking the output of large language models (LLMs) using token-level uncertainty quantification.
- The approach aims to identify potentially factually incorrect or "hallucinated" information in the model's generations.
- The authors evaluate their method on a diverse set of tasks and show it can effectively detect hallucinations while maintaining high generation quality.
Plain English Explanation
Large language models (LLMs) like GPT-3 have become incredibly powerful at generating human-like text on a wide range of topics. However, these models can sometimes produce factually incorrect or "hallucinated" information that appears plausible but is not grounded in reality. To Believe or Not to Believe Your Language Model and Benchmarking LLMs via Uncertainty Quantification have explored this challenge of identifying hallucinations in LLM outputs.
This paper proposes a new approach to fact-checking LLM generations by quantifying the model's uncertainty at the individual token level. The key idea is that tokens corresponding to factually incorrect information should have higher uncertainty than tokens conveying accurate, grounded information. By analyzing the uncertainty profile of the full text generation, the method can flag potentially hallucinated content.
The authors test their token-level uncertainty quantification technique on a diverse set of tasks, including open-ended generation, question answering, and dialogue. They show that it can effectively detect hallucinations while maintaining high generation quality overall. This represents an important step towards making LLMs more reliable and trustworthy, especially for applications where factual accuracy is critical.
Technical Explanation
The core of the authors' approach is a method for Generating Confidence & Uncertainty Quantification in Black-Box Large Language Models. They train a separate "uncertainty model" in parallel with the main LLM, which learns to predict the model's token-level uncertainty.
During inference, the uncertainty model provides a uncertainty score for each token in the LLM's generation. The authors then aggregate these token-level uncertainty scores to identify potentially hallucinated text regions. Their LUQ: Long-Text Uncertainty Quantification for Large Language Models technique handles the challenge of quantifying uncertainty in long, coherent text generations.
The authors evaluate their method on a diverse set of tasks, including open-ended story generation, question answering, and dialogue. They find that it can effectively detect Detecting Hallucinations in Large Language Model Generation while maintaining high generation quality according to human evaluation.
Critical Analysis
A key strength of this work is the breadth of tasks and datasets used to evaluate the token-level uncertainty quantification approach. By demonstrating its effectiveness across diverse generation scenarios, the authors build confidence in the generalizability of their method.
That said, the paper does not provide a detailed error analysis to understand the types of hallucinations the method struggles with. Exploring the failure modes could lead to insights for further improving the technique.
Additionally, the authors note that their method relies on access to the internal workings of the LLM, which may not be available in all practical settings. Investigating ways to adapt the approach to "black-box" LLMs could expand its real-world applicability.
Overall, this work represents an important advance in the critical area of ensuring the reliability and trustworthiness of large language models. The token-level uncertainty quantification technique is a promising step towards building more robust and transparent AI systems.
Conclusion
This paper presents a novel method for fact-checking the output of large language models by quantifying the models' token-level uncertainty. The approach can effectively detect potentially hallucinated or factually incorrect information while maintaining high generation quality.
By bringing more transparency and reliability to LLM outputs, this work represents a significant step towards making these powerful models more trustworthy, especially in high-stakes applications. Further research building on this technique could lead to even more robust and trustworthy AI systems in the future.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

To Believe or Not to Believe Your LLM
Yasin Abbasi Yadkori, Ilja Kuzborskij, Andr'as Gyorgy, Csaba Szepesv'ari
0
0
We explore uncertainty quantification in large language models (LLMs), with the goal to identify when uncertainty in responses given a query is large. We simultaneously consider both epistemic and aleatoric uncertainties, where the former comes from the lack of knowledge about the ground truth (such as about facts or the language), and the latter comes from irreducible randomness (such as multiple possible answers). In particular, we derive an information-theoretic metric that allows to reliably detect when only epistemic uncertainty is large, in which case the output of the model is unreliable. This condition can be computed based solely on the output of the model obtained simply by some special iterative prompting based on the previous responses. Such quantification, for instance, allows to detect hallucinations (cases when epistemic uncertainty is high) in both single- and multi-answer responses. This is in contrast to many standard uncertainty quantification strategies (such as thresholding the log-likelihood of a response) where hallucinations in the multi-answer case cannot be detected. We conduct a series of experiments which demonstrate the advantage of our formulation. Further, our investigations shed some light on how the probabilities assigned to a given output by an LLM can be amplified by iterative prompting, which might be of independent interest.
6/5/2024

Benchmarking LLMs via Uncertainty Quantification
Fanghua Ye, Mingming Yang, Jianhui Pang, Longyue Wang, Derek F. Wong, Emine Yilmaz, Shuming Shi, Zhaopeng Tu
0
0
The proliferation of open-source Large Language Models (LLMs) from various institutions has highlighted the urgent need for comprehensive evaluation methods. However, current evaluation platforms, such as the widely recognized HuggingFace open LLM leaderboard, neglect a crucial aspect -- uncertainty, which is vital for thoroughly assessing LLMs. To bridge this gap, we introduce a new benchmarking approach for LLMs that integrates uncertainty quantification. Our examination involves eight LLMs (LLM series) spanning five representative natural language processing tasks. Our findings reveal that: I) LLMs with higher accuracy may exhibit lower certainty; II) Larger-scale LLMs may display greater uncertainty compared to their smaller counterparts; and III) Instruction-finetuning tends to increase the uncertainty of LLMs. These results underscore the significance of incorporating uncertainty in the evaluation of LLMs.
4/26/2024
💬
Generating with Confidence: Uncertainty Quantification for Black-box Large Language Models
Zhen Lin, Shubhendu Trivedi, Jimeng Sun
0
0
Large language models (LLMs) specializing in natural language generation (NLG) have recently started exhibiting promising capabilities across a variety of domains. However, gauging the trustworthiness of responses generated by LLMs remains an open challenge, with limited research on uncertainty quantification (UQ) for NLG. Furthermore, existing literature typically assumes white-box access to language models, which is becoming unrealistic either due to the closed-source nature of the latest LLMs or computational constraints. In this work, we investigate UQ in NLG for *black-box* LLMs. We first differentiate *uncertainty* vs *confidence*: the former refers to the ``dispersion'' of the potential predictions for a fixed input, and the latter refers to the confidence on a particular prediction/generation. We then propose and compare several confidence/uncertainty measures, applying them to *selective NLG* where unreliable results could either be ignored or yielded for further assessment. Experiments were carried out with several popular LLMs on question-answering datasets (for evaluation purposes). Results reveal that a simple measure for the semantic dispersion can be a reliable predictor of the quality of LLM responses, providing valuable insights for practitioners on uncertainty management when adopting LLMs. The code to replicate our experiments is available at https://github.com/zlin7/UQ-NLG.
5/21/2024
🔍
LUQ: Long-text Uncertainty Quantification for LLMs
Caiqi Zhang, Fangyu Liu, Marco Basaldella, Nigel Collier
0
0
Large Language Models (LLMs) have demonstrated remarkable capability in a variety of NLP tasks. Despite their effectiveness, these models are prone to generate nonfactual content. Uncertainty Quantification (UQ) is pivotal in enhancing our understanding of a model's confidence in its generated content, thereby aiding in the mitigation of nonfactual outputs. Existing research on UQ predominantly targets short text generation, typically yielding brief, word-limited responses. However, real-world applications frequently necessitate much longer responses. Our study first highlights the limitations of current UQ methods in handling long text generation. We then introduce textsc{Luq}, a novel sampling-based UQ approach specifically designed for long text. Our findings reveal that textsc{Luq} outperforms existing baseline methods in correlating with the model's factuality scores (negative coefficient of -0.85 observed for Gemini Pro). With textsc{Luq} as the tool for UQ, we investigate behavior patterns of several popular LLMs' response confidence spectrum and how that interplays with the response' factuality. We identify that LLMs lack confidence in generating long text for rare facts and a factually strong model (i.e. GPT-4) tends to reject questions it is not sure about. To further improve the factual accuracy of LLM responses, we propose a method called textsc{Luq-Ensemble} that ensembles responses from multiple models and selects the response with the least uncertainty. The ensembling method greatly improves the response factuality upon the best standalone LLM.
4/1/2024