Benchmarking with Supernovae: A Performance Study of the FLASH Code

0
Sign in to get full access
Overview
- The paper provides a performance analysis of the FLASH code, a multi-scale, multi-physics simulation software, on different hardware architectures.
- The researchers evaluated the code's performance on AMD's Sapphire Rapids and Fujitsu's A64FX processors.
- They used a supernova explosion simulation as the benchmark to assess the code's scalability and efficiency.
Plain English Explanation
The paper discusses a study that looked at how well a computer program called FLASH performed on different types of computer hardware. FLASH is a software tool used to simulate complex physical phenomena, like the explosions of stars called supernovas. The researchers tested FLASH on two new processor designs: AMD's Sapphire Rapids and Fujitsu's A64FX. They used a simulation of a supernova explosion as a way to measure how fast and efficient FLASH was on these different hardware setups. The goal was to see how well FLASH could take advantage of the unique features and capabilities of these new processor designs.
Technical Explanation
The paper presents a performance analysis of the FLASH code, a widely-used multi-scale, multi-physics simulation software, on two emerging hardware architectures: AMD's Sapphire Rapids and Fujitsu's A64FX processors. The researchers used a supernova explosion simulation as a benchmark to evaluate the code's scalability and efficiency across these different hardware platforms. They examined various performance metrics, such as time-to-solution, strong and weak scaling, and energy efficiency, to provide insights into the code's behavior and identify optimization opportunities.
The results showed that FLASH was able to effectively leverage the architectural features of both processors, including the Sapphire Rapids' advanced vector extensions and the A64FX's high-performance ARM-based cores. The paper also discusses the implications of these findings for the continued development and optimization of large-scale, multi-physics simulation codes like FLASH.
Critical Analysis
The paper provides a thorough and well-designed performance analysis of the FLASH code on cutting-edge hardware architectures. However, the study is limited to a single benchmark problem (supernova explosion) and does not explore the code's behavior on a wider range of scientific applications. Additionally, the paper does not delve into the potential challenges or limitations of porting and optimizing FLASH for these new processor designs, which could be of interest to researchers and developers working on similar multi-physics simulation software.
Conclusion
This paper offers valuable insights into the performance characteristics of the FLASH code on AMD's Sapphire Rapids and Fujitsu's A64FX processors. The results demonstrate the code's ability to effectively leverage the unique architectural features of these new hardware platforms, which is crucial for the continued advancement of large-scale, multi-physics simulations. The findings presented in this study can inform the ongoing development and optimization of FLASH and similar simulation software, helping to ensure they can fully harness the capabilities of emerging HPC hardware.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Benchmarking with Supernovae: A Performance Study of the FLASH Code
Joshua Martin, Catherine Feldman, Eva Siegmann, Tony Curtis, David Carlson, Firat Coskun, Daniel Wood, Raul Gonzalez, Robert J. Harrison, Alan C. Calder
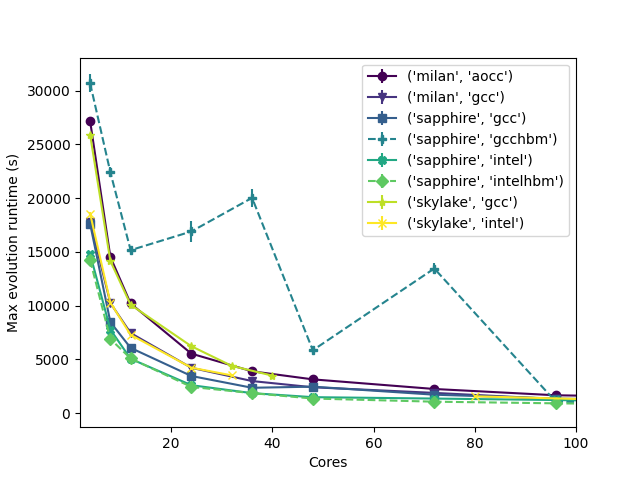
Astrophysical simulations are computation, memory, and thus energy intensive, thereby requiring new hardware advances for progress. Stony Brook University recently expanded its computing cluster SeaWulf with an addition of 94 new nodes featuring Intel Sapphire Rapids Xeon Max series CPUs. We present a performance and power efficiency study of this hardware performed with FLASH: a multi-scale, multi-physics, adaptive mesh-based software instrument. We extend this study to compare performance to that of Stony Brook's Ookami testbed which features ARM-based A64FX-700 processors, and SeaWulf's AMD EPYC Milan and Intel Skylake nodes. Our application is a stellar explosion known as a thermonuclear (Type Ia) supernova and for this 3D problem, FLASH includes operators for hydrodynamics, gravity, and nuclear burning, in addition to routines for the material equation of state. We perform a strong-scaling study with a 220 GB problem size to explore both single- and multi-node performance. Our study explores the performance of different MPI mappings and the distribution of processors across nodes. From these tests, we determined the optimal configuration to balance runtime and energy consumption for our application.
Read more8/30/2024
🤖
5
Microarchitectural comparison and in-core modeling of state-of-the-art CPUs: Grace, Sapphire Rapids, and Genoa
Jan Laukemann, Georg Hager, Gerhard Wellein
With Nvidia's release of the Grace Superchip, all three big semiconductor companies in HPC (AMD, Intel, Nvidia) are currently competing in the race for the best CPU. In this work we analyze the performance of these state-of-the-art CPUs and create an accurate in-core performance model for their microarchitectures Zen 4, Golden Cove, and Neoverse V2, extending the Open Source Architecture Code Analyzer (OSACA) tool and comparing it with LLVM-MCA. Starting from the peculiarities and up- and downsides of a single core, we extend our comparison by a variety of microbenchmarks and the capabilities of a full node. The write-allocate (WA) evasion feature, which can automatically reduce the memory traffic caused by write misses, receives special attention; we show that the Grace Superchip has a next-to-optimal implementation of WA evasion, and that the only way to avoid write allocates on Zen 4 is the explicit use of non-temporal stores.
Read more9/14/2024
🛠️
0
CloverLeaf on Intel Multi-Core CPUs: A Case Study in Write-Allocate Evasion
Jan Laukemann, Thomas Gruber, Georg Hager, Dossay Oryspayev, Gerhard Wellein
In this paper we analyze the MPI-only version of the CloverLeaf code from the SPEChpc 2021 benchmark suite on recent Intel Xeon Ice Lake and Sapphire Rapids server CPUs. We observe peculiar breakdowns in performance when the number of processes is prime. Investigating this effect, we create first-principles data traffic models for each of the stencil-like hotspot loops. With application measurements and microbenchmarks to study memory data traffic behavior, we can connect the breakdowns to SpecI2M, a new write-allocate evasion feature in current Intel CPUs. For serial and full-node cases we are able to predict the memory data volume analytically with an error of a few percent. We find that if the number of processes is prime, SpecI2M fails to work properly, which we can attribute to short inner loops emerging from the one-dimensional domain decomposition in this case. We can also rule out other possible causes of the prime number effect, such as breaking layer conditions, MPI communication overhead, and load imbalance.
Read more5/20/2024
🚀
0
A Comparison of the Performance of the Molecular Dynamics Simulation Package GROMACS Implemented in the SYCL and CUDA Programming Models
L. Apanasevich, Yogesh Kale, Himanshu Sharma, Ana Marija Sokovic
For many years, systems running Nvidia-based GPU architectures have dominated the heterogeneous supercomputer landscape. However, recently GPU chipsets manufactured by Intel and AMD have cut into this market and can now be found in some of the worlds fastest supercomputers. The June 2023 edition of the TOP500 list of supercomputers ranks the Frontier supercomputer at the Oak Ridge National Laboratory in Tennessee as the top system in the world. This system features AMD Instinct 250 X GPUs and is currently the only true exascale computer in the world.The first framework that enabled support for heterogeneous platforms across multiple hardware vendors was OpenCL, in 2009. Since then a number of frameworks have been developed to support vendor agnostic heterogeneous environments including OpenMP, OpenCL, Kokkos, and SYCL. SYCL, which combines the concepts of OpenCL with the flexibility of single-source C++, is one of the more promising programming models for heterogeneous computing devices. One key advantage of this framework is that it provides a higher-level programming interface that abstracts away many of the hardware details than the other frameworks. This makes SYCL easier to learn and to maintain across multiple architectures and vendors. In n recent years, there has been growing interest in using heterogeneous computing architectures to accelerate molecular dynamics simulations. Some of the more popular molecular dynamics simulations include Amber, NAMD, and Gromacs. However, to the best of our knowledge, only Gromacs has been successfully ported to SYCL to date. In this paper, we compare the performance of GROMACS compiled using the SYCL and CUDA frameworks for a variety of standard GROMACS benchmarks. In addition, we compare its performance across three different Nvidia GPU chipsets, P100, V100, and A100.
Read more6/18/2024