A Comparison of the Performance of the Molecular Dynamics Simulation Package GROMACS Implemented in the SYCL and CUDA Programming Models

0
🚀
Sign in to get full access
Overview
- GPU-based supercomputing has been dominated by Nvidia for years, but Intel and AMD chipsets are now making inroads
- The Frontier supercomputer, powered by AMD Instinct 250X GPUs, is currently the world's only true exascale system
- Several programming frameworks like OpenCL, OpenMP, and SYCL have been developed to support heterogeneous computing environments
Plain English Explanation
Supercomputers are incredibly powerful computers used for complex scientific and engineering calculations. For a long time, the GPUs (graphics processing units) in these systems were mostly made by Nvidia. But now, chips from Intel and AMD are also being used in some of the world's fastest supercomputers.
The Frontier supercomputer, located at the Oak Ridge National Laboratory in Tennessee, is currently the most powerful computer in the world. It uses AMD's Instinct 250X GPUs, making it the first true "exascale" system - a computer capable of a quintillion (a billion billion) calculations per second.
To make these heterogeneous systems, where different hardware components work together, several programming frameworks have been developed. These include OpenCL, OpenMP, and SYCL. SYCL, in particular, is seen as a promising model because it provides a higher-level, easier-to-use interface for programming these complex systems.
Technical Explanation
This paper evaluates the performance of the popular GROMACS molecular dynamics simulation software when compiled using the SYCL and CUDA programming frameworks. It compares the performance across three different Nvidia GPU models: the P100, V100, and A100.
The researchers found that GROMACS compiled with SYCL was able to achieve performance comparable to the CUDA version on Nvidia GPUs. This suggests that SYCL can be a viable alternative for porting existing CUDA-based applications to run on a wider range of heterogeneous hardware, including AMD and Intel GPUs.
Critical Analysis
The paper provides a thorough evaluation of GROMACS performance using SYCL, but it is limited to only Nvidia GPU architectures. Further research would be needed to assess the performance on AMD and Intel GPUs as well. Additionally, the paper does not explore the productivity and maintainability benefits of using a higher-level framework like SYCL compared to lower-level APIs like CUDA.
Conclusion
This research demonstrates that the SYCL programming model can be effectively used to port existing CUDA-based HPC applications like GROMACS to run on a variety of heterogeneous hardware platforms. As the supercomputing landscape continues to diversify beyond Nvidia's GPU dominance, frameworks like SYCL will become increasingly important for enabling cross-vendor portability and productivity in developing scientific computing software.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🚀
0
A Comparison of the Performance of the Molecular Dynamics Simulation Package GROMACS Implemented in the SYCL and CUDA Programming Models
L. Apanasevich, Yogesh Kale, Himanshu Sharma, Ana Marija Sokovic
For many years, systems running Nvidia-based GPU architectures have dominated the heterogeneous supercomputer landscape. However, recently GPU chipsets manufactured by Intel and AMD have cut into this market and can now be found in some of the worlds fastest supercomputers. The June 2023 edition of the TOP500 list of supercomputers ranks the Frontier supercomputer at the Oak Ridge National Laboratory in Tennessee as the top system in the world. This system features AMD Instinct 250 X GPUs and is currently the only true exascale computer in the world.The first framework that enabled support for heterogeneous platforms across multiple hardware vendors was OpenCL, in 2009. Since then a number of frameworks have been developed to support vendor agnostic heterogeneous environments including OpenMP, OpenCL, Kokkos, and SYCL. SYCL, which combines the concepts of OpenCL with the flexibility of single-source C++, is one of the more promising programming models for heterogeneous computing devices. One key advantage of this framework is that it provides a higher-level programming interface that abstracts away many of the hardware details than the other frameworks. This makes SYCL easier to learn and to maintain across multiple architectures and vendors. In n recent years, there has been growing interest in using heterogeneous computing architectures to accelerate molecular dynamics simulations. Some of the more popular molecular dynamics simulations include Amber, NAMD, and Gromacs. However, to the best of our knowledge, only Gromacs has been successfully ported to SYCL to date. In this paper, we compare the performance of GROMACS compiled using the SYCL and CUDA frameworks for a variety of standard GROMACS benchmarks. In addition, we compare its performance across three different Nvidia GPU chipsets, P100, V100, and A100.
Read more6/18/2024
🚀
0
GROMACS on AMD GPU-Based HPC Platforms: Using SYCL for Performance and Portability
Andrey Alekseenko, Szil'ard P'all, Erik Lindahl
GROMACS is a widely-used molecular dynamics software package with a focus on performance, portability, and maintainability across a broad range of platforms. Thanks to its early algorithmic redesign and flexible heterogeneous parallelization, GROMACS has successfully harnessed GPU accelerators for more than a decade. With the diversification of accelerator platforms in HPC and no obvious choice for a multi-vendor programming model, the GROMACS project found itself at a crossroads. The performance and portability requirements, and a strong preference for a standards-based solution, motivated our choice to use SYCL on both new HPC GPU platforms: AMD and Intel. Since the GROMACS 2022 release, the SYCL backend has been the primary means to target AMD GPUs in preparation for exascale HPC architectures like LUMI and Frontier. SYCL is a cross-platform, royalty-free, C++17-based standard for programming hardware accelerators. It allows using the same code to target GPUs from all three major vendors with minimal specialization. While SYCL implementations build on native toolchains, performance of such an approach is not immediately evident. Biomolecular simulations have challenging performance characteristics: latency sensitivity, the need for strong scaling, and typical iteration times as short as hundreds of microseconds. Hence, obtaining good performance across the range of problem sizes and scaling regimes is particularly challenging. Here, we share the results of our work on readying GROMACS for AMD GPU platforms using SYCL, and demonstrate performance on Cray EX235a machines with MI250X accelerators. Our findings illustrate that portability is possible without major performance compromises. We provide a detailed analysis of node-level kernel and runtime performance with the aim of sharing best practices with the HPC community on using SYCL as a performance-portable GPU framework.
Read more5/3/2024

0
Gaining Cross-Platform Parallelism for HAL's Molecular Dynamics Package using SYCL
Viktor Skoblin, Felix Hofling, Steffen Christgau
Molecular dynamics simulations are one of the methods in scientific computing that benefit from GPU acceleration. For those devices, SYCL is a promising API for writing portable codes. In this paper, we present the case study of HAL's MD package that has been successfully migrated from CUDA to SYCL. We describe the different strategies that we followed in the process of porting the code. Following these strategies, we achieved code portability across major GPU vendors. Depending on the actual kernels, both significant performance improvements and regressions are observed. As a side effect of the migration process, we obtained impressing speedups also for execution on CPUs.
Read more6/7/2024
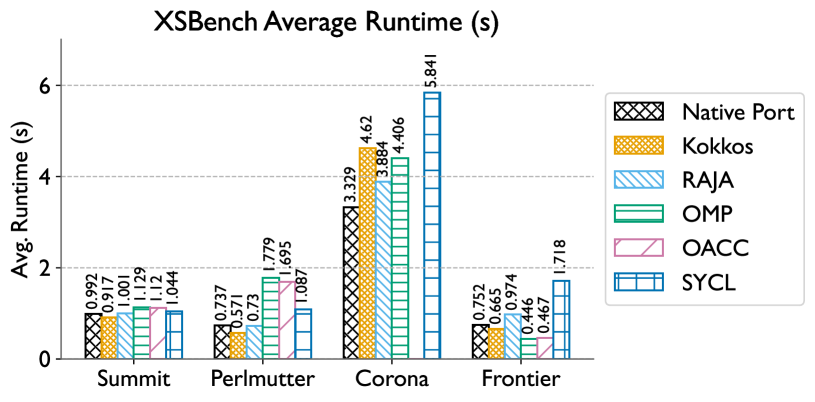
0
Taking GPU Programming Models to Task for Performance Portability
Joshua H. Davis, Pranav Sivaraman, Joy Kitson, Konstantinos Parasyris, Harshitha Menon, Isaac Minn, Giorgis Georgakoudis, Abhinav Bhatele
Portability is critical to ensuring high productivity in developing and maintaining scientific software as the diversity in on-node hardware architectures increases. While several programming models provide portability for diverse GPU platforms, they don't make any guarantees about performance portability. In this work, we explore several programming models -- CUDA, HIP, Kokkos, RAJA, OpenMP, OpenACC, and SYCL, to study if the performance of these models is consistently good across NVIDIA and AMD GPUs. We use five proxy applications from different scientific domains, create implementations where missing, and use them to present a comprehensive comparative evaluation of the programming models. We provide a Spack scripting-based methodology to ensure reproducibility of experiments conducted in this work. Finally, we attempt to answer the question -- to what extent does each programming model provide performance portability for heterogeneous systems in real-world usage?
Read more5/22/2024