Between Randomness and Arbitrariness: Some Lessons for Reliable Machine Learning at Scale
2406.09548
0
0
✨
Abstract
To develop rigorous knowledge about ML models -- and the systems in which they are embedded -- we need reliable measurements. But reliable measurement is fundamentally challenging, and touches on issues of reproducibility, scalability, uncertainty quantification, epistemology, and more. This dissertation addresses criteria needed to take reliability seriously: both criteria for designing meaningful metrics, and for methodologies that ensure that we can dependably and efficiently measure these metrics at scale and in practice. In doing so, this dissertation articulates a research vision for a new field of scholarship at the intersection of machine learning, law, and policy. Within this frame, we cover topics that fit under three different themes: (1) quantifying and mitigating sources of arbitrariness in ML, (2) taming randomness in uncertainty estimation and optimization algorithms, in order to achieve scalability without sacrificing reliability, and (3) providing methods for evaluating generative-AI systems, with specific focuses on quantifying memorization in language models and training latent diffusion models on open-licensed data. By making contributions in these three themes, this dissertation serves as an empirical proof by example that research on reliable measurement for machine learning is intimately and inescapably bound up with research in law and policy. These different disciplines pose similar research questions about reliable measurement in machine learning. They are, in fact, two complementary sides of the same research vision, which, broadly construed, aims to construct machine-learning systems that cohere with broader societal values.
Create account to get full access
Overview
- This dissertation addresses the fundamental challenge of reliable measurement in machine learning (ML) systems.
- It proposes criteria for designing meaningful metrics and methodologies to ensure dependable and efficient measurement at scale.
- The research covers three key themes: (1) quantifying and mitigating arbitrariness in ML, (2) taming randomness in uncertainty estimation and optimization algorithms, and (3) evaluating generative-AI systems.
- The dissertation argues that research on reliable measurement for ML is inherently linked to research in law and policy, as these disciplines share similar questions about ensuring ML systems align with societal values.
Plain English Explanation
To truly understand how machine learning (ML) models work and how they are used in real-world systems, we need reliable ways to measure their performance. However, reliable measurement is not easy to achieve. It involves dealing with issues like reproducibility, scalability, uncertainty, and ensuring the measurements align with broader societal values.
This dissertation tackles this challenge head-on. It proposes criteria for designing meaningful metrics and methods to measure these metrics efficiently and at a large scale. The key ideas covered in the dissertation include:
- Quantifying and Mitigating Arbitrariness in ML: Identifying and addressing sources of unpredictability or "arbitrariness" in how ML models behave, which can undermine their reliability.
- Taming Randomness in Uncertainty Estimation and Optimization: Developing techniques to control the inherent randomness in how ML models estimate uncertainty and optimize their performance, so that they can be used reliably at a large scale.
- Evaluating Generative-AI Systems: Providing ways to assess the performance of AI systems that generate new content, such as by measuring how much they "memorize" training data or how well they work with open-licensed data.
Importantly, the dissertation argues that research on reliable measurement for ML is closely tied to work in law and policy. These different fields share common questions about ensuring ML systems align with broader societal values and expectations. By bringing these disciplines together, the dissertation lays the groundwork for a new area of scholarship that could help us build ML systems that are more trustworthy and beneficial to society.
Technical Explanation
The core focus of this dissertation is on developing rigorous, reliable methods for measuring the performance of machine learning (ML) models and the systems in which they are embedded. The author recognizes that reliable measurement is fundamentally challenging, as it touches on issues of reproducibility, scalability, uncertainty quantification, and ensuring alignment with societal values.
To address this challenge, the dissertation articulates criteria for designing meaningful metrics and methodologies that can dependably and efficiently measure these metrics at scale. The research is organized around three key themes:
- Quantifying and Mitigating Sources of Arbitrariness in ML: This theme focuses on identifying and addressing unpredictable or "arbitrary" behaviors in ML models that can undermine their reliability, drawing on concepts from the ML robustness primer.
- Taming Randomness in Uncertainty Estimation and Optimization Algorithms: The author tackles the inherent randomness in how ML models estimate uncertainty and optimize their performance, aiming to achieve scalability without sacrificing reliability.
- Providing Methods for Evaluating Generative-AI Systems: This theme includes work on quantifying memorization in language models and training latent diffusion models on open-licensed data, addressing issues of reliability and equity in generative AI systems.
By making contributions in these three areas, the dissertation demonstrates that research on reliable measurement for ML is fundamentally tied to work in law and policy. These different disciplines share a common interest in ensuring that ML systems cohere with broader societal values, as reflected in the structured review of the literature on uncertainty in ML.
Critical Analysis
The dissertation tackles an important and challenging problem in the field of machine learning: how to ensure reliable and dependable measurements of ML model performance and behavior. The author's recognition that this issue touches on a range of complex topics, from reproducibility to epistemology, is commendable.
One potential limitation of the research is the scope - by covering three distinct thematic areas, the dissertation may lack the depth that a more focused exploration of a single theme could provide. Additionally, while the author argues for the inherent connection between reliable ML measurement and research in law and policy, the specific nature of this connection and its implications could be explored in greater detail.
That said, the dissertation's emphasis on developing criteria for meaningful metrics and scalable methodologies is a valuable contribution. The work on quantifying memorization in language models and training latent diffusion models on open-licensed data, in particular, addresses important practical challenges in the deployment of generative AI systems.
Overall, this dissertation represents a thoughtful and ambitious attempt to tackle the fundamental challenge of reliable measurement in machine learning. By pushing the field to consider the broader societal implications of ML systems, the author has laid the groundwork for a new, interdisciplinary area of scholarship that could have significant impact on the responsible development and deployment of AI technologies.
Conclusion
This dissertation tackles the critical challenge of ensuring reliable measurements of machine learning (ML) models and the systems in which they are embedded. By proposing criteria for designing meaningful metrics and methodologies to measure these metrics at scale, the author has made an important contribution to the field.
The research covers three key themes: (1) quantifying and mitigating sources of arbitrariness in ML, (2) taming randomness in uncertainty estimation and optimization algorithms, and (3) evaluating generative-AI systems. Importantly, the dissertation argues that this work on reliable measurement for ML is inherently linked to research in law and policy, as these disciplines share a common interest in ensuring that ML systems align with broader societal values.
Overall, this dissertation represents a significant step towards building more trustworthy and beneficial AI systems. By fostering a deeper understanding of the reliability and limitations of ML models, the author's work has the potential to inform both the technical development of these technologies and the policies and regulations that govern their use.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤿
A Structured Review of Literature on Uncertainty in Machine Learning & Deep Learning
Fahimeh Fakour, Ali Mosleh, Ramin Ramezani
0
0
The adaptation and use of Machine Learning (ML) in our daily lives has led to concerns in lack of transparency, privacy, reliability, among others. As a result, we are seeing research in niche areas such as interpretability, causality, bias and fairness, and reliability. In this survey paper, we focus on a critical concern for adaptation of ML in risk-sensitive applications, namely understanding and quantifying uncertainty. Our paper approaches this topic in a structured way, providing a review of the literature in the various facets that uncertainty is enveloped in the ML process. We begin by defining uncertainty and its categories (e.g., aleatoric and epistemic), understanding sources of uncertainty (e.g., data and model), and how uncertainty can be assessed in terms of uncertainty quantification techniques (Ensembles, Bayesian Neural Networks, etc.). As part of our assessment and understanding of uncertainty in the ML realm, we cover metrics for uncertainty quantification for a single sample, dataset, and metrics for accuracy of the uncertainty estimation itself. This is followed by discussions on calibration (model and uncertainty), and decision making under uncertainty. Thus, we provide a more complete treatment of uncertainty: from the sources of uncertainty to the decision-making process. We have focused the review of uncertainty quantification methods on Deep Learning (DL), while providing the necessary background for uncertainty discussion within ML in general. Key contributions in this review are broadening the scope of uncertainty discussion, as well as an updated review of uncertainty quantification methods in DL.
6/4/2024
⛏️
Machine Learning Robustness: A Primer
Houssem Ben Braiek, Foutse Khomh
0
0
This chapter explores the foundational concept of robustness in Machine Learning (ML) and its integral role in establishing trustworthiness in Artificial Intelligence (AI) systems. The discussion begins with a detailed definition of robustness, portraying it as the ability of ML models to maintain stable performance across varied and unexpected environmental conditions. ML robustness is dissected through several lenses: its complementarity with generalizability; its status as a requirement for trustworthy AI; its adversarial vs non-adversarial aspects; its quantitative metrics; and its indicators such as reproducibility and explainability. The chapter delves into the factors that impede robustness, such as data bias, model complexity, and the pitfalls of underspecified ML pipelines. It surveys key techniques for robustness assessment from a broad perspective, including adversarial attacks, encompassing both digital and physical realms. It covers non-adversarial data shifts and nuances of Deep Learning (DL) software testing methodologies. The discussion progresses to explore amelioration strategies for bolstering robustness, starting with data-centric approaches like debiasing and augmentation. Further examination includes a variety of model-centric methods such as transfer learning, adversarial training, and randomized smoothing. Lastly, post-training methods are discussed, including ensemble techniques, pruning, and model repairs, emerging as cost-effective strategies to make models more resilient against the unpredictable. This chapter underscores the ongoing challenges and limitations in estimating and achieving ML robustness by existing approaches. It offers insights and directions for future research on this crucial concept, as a prerequisite for trustworthy AI systems.
5/7/2024
🤿
Reliability and Interpretability in Science and Deep Learning
Luigi Scorzato
0
0
In recent years, the question of the reliability of Machine Learning (ML) methods has acquired significant importance, and the analysis of the associated uncertainties has motivated a growing amount of research. However, most of these studies have applied standard error analysis to ML models, and in particular Deep Neural Network (DNN) models, which represent a rather significant departure from standard scientific modelling. It is therefore necessary to integrate the standard error analysis with a deeper epistemological analysis of the possible differences between DNN models and standard scientific modelling and the possible implications of these differences in the assessment of reliability. This article offers several contributions. First, it emphasises the ubiquitous role of model assumptions (both in ML and traditional Science) against the illusion of theory-free science. Secondly, model assumptions are analysed from the point of view of their (epistemic) complexity, which is shown to be language-independent. It is argued that the high epistemic complexity of DNN models hinders the estimate of their reliability and also their prospect of long-term progress. Some potential ways forward are suggested. Thirdly, this article identifies the close relation between a model's epistemic complexity and its interpretability, as introduced in the context of responsible AI. This clarifies in which sense, and to what extent, the lack of understanding of a model (black-box problem) impacts its interpretability in a way that is independent of individual skills. It also clarifies how interpretability is a precondition for assessing the reliability of any model, which cannot be based on statistical analysis alone. This article focuses on the comparison between traditional scientific models and DNN models. But, Random Forest and Logistic Regression models are also briefly considered.
6/13/2024
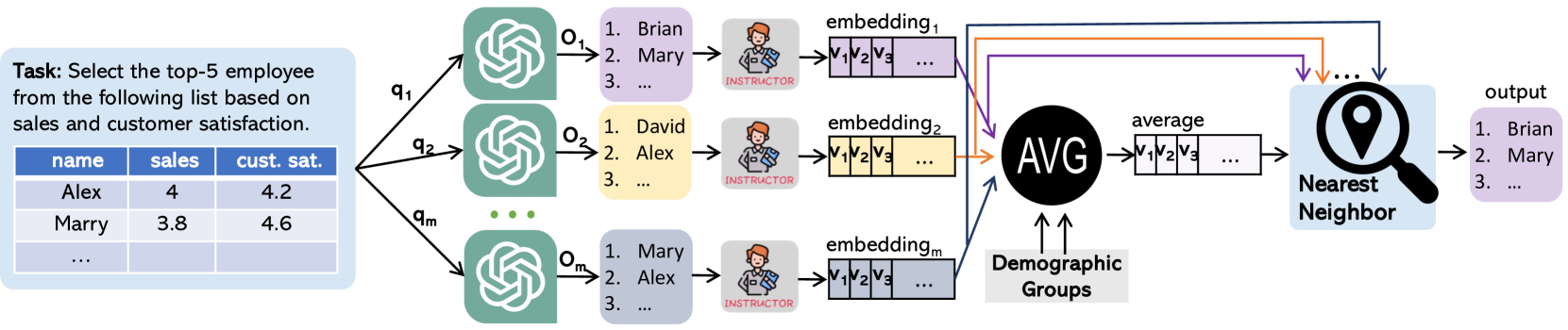
REQUAL-LM: Reliability and Equity through Aggregation in Large Language Models
Sana Ebrahimi, Nima Shahbazi, Abolfazl Asudeh
0
0
The extensive scope of large language models (LLMs) across various domains underscores the critical importance of responsibility in their application, beyond natural language processing. In particular, the randomized nature of LLMs, coupled with inherent biases and historical stereotypes in data, raises critical concerns regarding reliability and equity. Addressing these challenges are necessary before using LLMs for applications with societal impact. Towards addressing this gap, we introduce REQUAL-LM, a novel method for finding reliable and equitable LLM outputs through aggregation. Specifically, we develop a Monte Carlo method based on repeated sampling to find a reliable output close to the mean of the underlying distribution of possible outputs. We formally define the terms such as reliability and bias, and design an equity-aware aggregation to minimize harmful bias while finding a highly reliable output. REQUAL-LM does not require specialized hardware, does not impose a significant computing load, and uses LLMs as a blackbox. This design choice enables seamless scalability alongside the rapid advancement of LLM technologies. Our system does not require retraining the LLMs, which makes it deployment ready and easy to adapt. Our comprehensive experiments using various tasks and datasets demonstrate that REQUAL- LM effectively mitigates bias and selects a more equitable response, specifically the outputs that properly represents minority groups.
4/19/2024