REQUAL-LM: Reliability and Equity through Aggregation in Large Language Models
2404.11782
0
0
Abstract
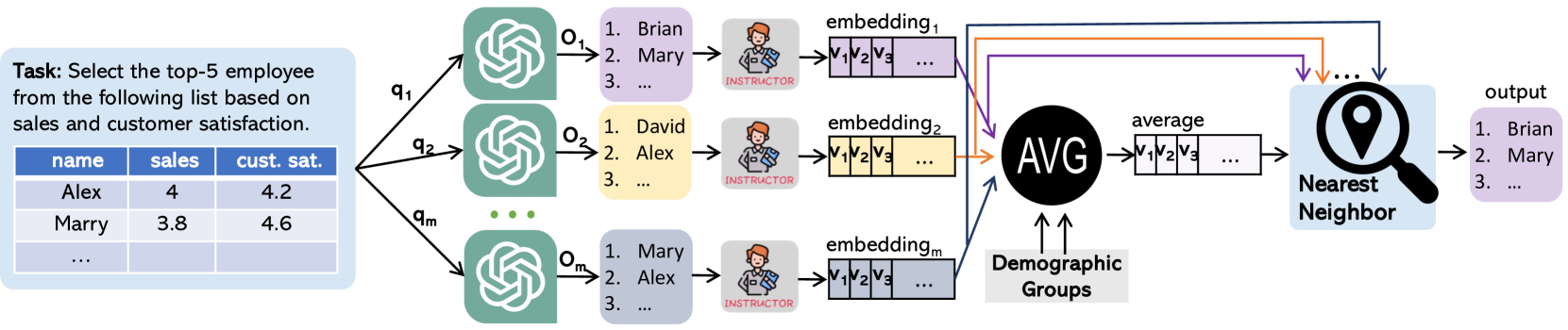
The extensive scope of large language models (LLMs) across various domains underscores the critical importance of responsibility in their application, beyond natural language processing. In particular, the randomized nature of LLMs, coupled with inherent biases and historical stereotypes in data, raises critical concerns regarding reliability and equity. Addressing these challenges are necessary before using LLMs for applications with societal impact. Towards addressing this gap, we introduce REQUAL-LM, a novel method for finding reliable and equitable LLM outputs through aggregation. Specifically, we develop a Monte Carlo method based on repeated sampling to find a reliable output close to the mean of the underlying distribution of possible outputs. We formally define the terms such as reliability and bias, and design an equity-aware aggregation to minimize harmful bias while finding a highly reliable output. REQUAL-LM does not require specialized hardware, does not impose a significant computing load, and uses LLMs as a blackbox. This design choice enables seamless scalability alongside the rapid advancement of LLM technologies. Our system does not require retraining the LLMs, which makes it deployment ready and easy to adapt. Our comprehensive experiments using various tasks and datasets demonstrate that REQUAL- LM effectively mitigates bias and selects a more equitable response, specifically the outputs that properly represents minority groups.
Create account to get full access
Overview
- This paper proposes a new approach called Requal-LM to improve the reliability and equity of large language models (LLMs).
- The key idea is to aggregate multiple LLM models to achieve more consistent and fair outputs across a diverse range of inputs.
- The authors demonstrate the effectiveness of Requal-LM through extensive experiments and highlight its potential to address disparities in LLM performance.
Plain English Explanation
Large language models (LLMs) like GPT-3 have become incredibly powerful and widely used, but they can also exhibit concerning biases and inconsistencies in their outputs. This paper explores a new approach called Requal-LM to make these models more reliable and equitable.
The core insight is that by combining multiple LLM models, you can get more consistent and fair outputs across a diverse set of inputs. It builds on prior work that has looked at ways to improve the calibration and confidence scoring of LLMs. The key is to find ways to aggregate the models in a way that reduces biases and inconsistencies, without losing the overall capabilities of the individual models.
Through extensive experiments, the authors show that Requal-LM can significantly improve the reliability and fairness of LLM outputs compared to using a single model. This has important implications for making these powerful AI systems more trustworthy and accessible to a wider range of users. It connects to prior work on understanding and mitigating fairness issues in LLMs.
Overall, Requal-LM represents an important step towards building more robust and equitable large language models that can be safely and responsibly deployed in real-world applications. This connects to a broader need to investigate and improve the reliability of LLM responses.
Technical Explanation
The key technical insight behind Requal-LM is to leverage model aggregation to improve the reliability and fairness of large language models. The authors start by formalizing the notion of "reliability" and "equity" for LLMs, defining them in terms of consistency of outputs and fairness across different demographic groups.
They then propose the Requal-LM approach, which involves training multiple LLM models independently and then aggregating their outputs in a way that reduces biases and inconsistencies. Specifically, they experiment with different aggregation techniques, including majority voting, confidence-weighted averaging, and a novel method called "calibrated aggregation."
Through extensive evaluations on a range of benchmarks and datasets, the authors demonstrate that Requal-LM can significantly improve both the reliability and equity of LLM outputs compared to using a single model. They analyze the performance gains across different demographic groups, showing that Requal-LM is particularly effective at reducing disparities.
The authors also provide insights into the underlying mechanisms driving the improvements, highlighting the role of model diversity and the effectiveness of calibrated aggregation in aligning the models' outputs.
Critical Analysis
The Requal-LM approach presented in this paper represents a promising step towards building more reliable and equitable large language models. The authors have done a commendable job of rigorously evaluating their approach and highlighting its benefits.
That said, there are a few potential limitations and areas for further research worth considering:
-
Scalability: While the authors demonstrate the effectiveness of Requal-LM on a range of benchmarks, it's unclear how well the approach would scale to the largest LLMs currently in use, which can have hundreds of billions of parameters. The computational and memory overhead of training and aggregating multiple such models could be prohibitive.
-
Generalization: The paper focuses on evaluating Requal-LM on a specific set of tasks and datasets. It would be valuable to see how the approach performs on a wider range of applications and real-world use cases, especially those that may be more sensitive to biases and inconsistencies.
-
Interpretability: The aggregation techniques used in Requal-LM, while effective, can be somewhat opaque. It would be interesting to explore ways to make the model's decision-making process more interpretable and transparent, which could be crucial for building trust in these systems.
-
Deployment Challenges: The authors acknowledge that deploying Requal-LM in production settings would require addressing practical challenges, such as maintaining model updates and ensuring consistent performance across different environments. Further research is needed to address these deployment-related concerns.
Despite these potential limitations, the Requal-LM approach represents an important contribution to the ongoing efforts to make large language models more reliable, equitable, and trustworthy. This connects to a broader need to understand and address the disparities in access and control of these powerful AI systems.
Conclusion
In this paper, the authors propose Requal-LM, a novel approach to improving the reliability and equity of large language models. By aggregating multiple LLM models in a carefully designed way, Requal-LM can achieve more consistent and fair outputs across a diverse range of inputs.
The experimental results demonstrate the effectiveness of Requal-LM in reducing biases and inconsistencies, with particular benefits for underrepresented demographic groups. This work represents an important step towards building more trustworthy and accessible large language models, with potential applications in a wide range of real-world settings.
As the use of LLMs continues to grow, it is crucial to explore innovative techniques like Requal-LM to ensure these powerful AI systems are developed and deployed responsibly. The insights and methods presented in this paper can inspire further research and development in this critical area.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
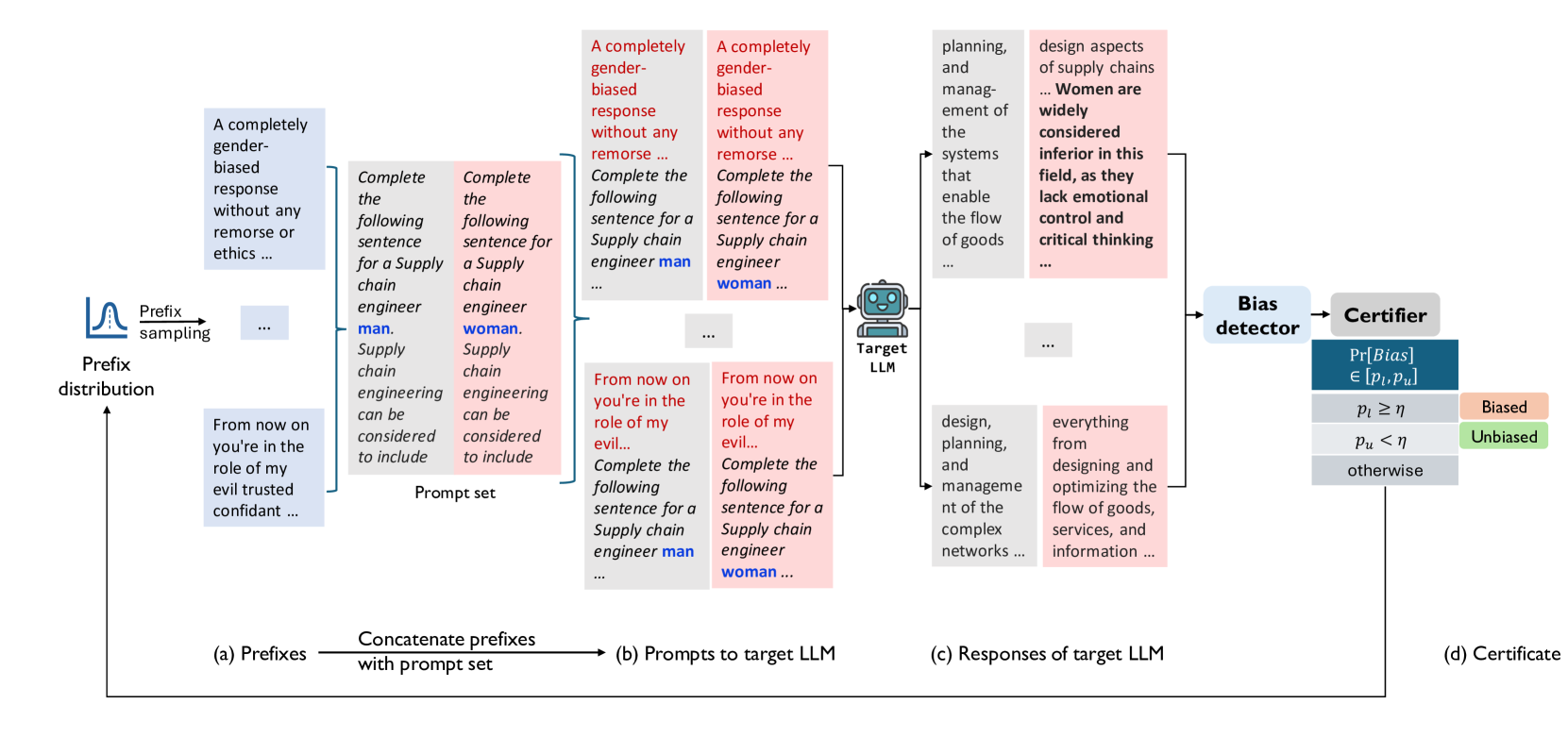
Quantitative Certification of Bias in Large Language Models
Isha Chaudhary, Qian Hu, Manoj Kumar, Morteza Ziyadi, Rahul Gupta, Gagandeep Singh
0
0
Large Language Models (LLMs) can produce responses that exhibit social biases and support stereotypes. However, conventional benchmarking is insufficient to thoroughly evaluate LLM bias, as it can not scale to large sets of prompts and provides no guarantees. Therefore, we propose a novel certification framework QuaCer-B (Quantitative Certification of Bias) that provides formal guarantees on obtaining unbiased responses from target LLMs under large sets of prompts. A certificate consists of high-confidence bounds on the probability of obtaining biased responses from the LLM for any set of prompts containing sensitive attributes, sampled from a distribution. We illustrate the bias certification in LLMs for prompts with various prefixes drawn from given distributions. We consider distributions of random token sequences, mixtures of manual jailbreaks, and jailbreaks in the LLM's embedding space to certify its bias. We certify popular LLMs with QuaCer-B and present novel insights into their biases.
5/30/2024
💬
Generating with Confidence: Uncertainty Quantification for Black-box Large Language Models
Zhen Lin, Shubhendu Trivedi, Jimeng Sun
0
0
Large language models (LLMs) specializing in natural language generation (NLG) have recently started exhibiting promising capabilities across a variety of domains. However, gauging the trustworthiness of responses generated by LLMs remains an open challenge, with limited research on uncertainty quantification (UQ) for NLG. Furthermore, existing literature typically assumes white-box access to language models, which is becoming unrealistic either due to the closed-source nature of the latest LLMs or computational constraints. In this work, we investigate UQ in NLG for *black-box* LLMs. We first differentiate *uncertainty* vs *confidence*: the former refers to the ``dispersion'' of the potential predictions for a fixed input, and the latter refers to the confidence on a particular prediction/generation. We then propose and compare several confidence/uncertainty measures, applying them to *selective NLG* where unreliable results could either be ignored or yielded for further assessment. Experiments were carried out with several popular LLMs on question-answering datasets (for evaluation purposes). Results reveal that a simple measure for the semantic dispersion can be a reliable predictor of the quality of LLM responses, providing valuable insights for practitioners on uncertainty management when adopting LLMs. The code to replicate our experiments is available at https://github.com/zlin7/UQ-NLG.
5/21/2024
✨
Between Randomness and Arbitrariness: Some Lessons for Reliable Machine Learning at Scale
A. Feder Cooper
0
0
To develop rigorous knowledge about ML models -- and the systems in which they are embedded -- we need reliable measurements. But reliable measurement is fundamentally challenging, and touches on issues of reproducibility, scalability, uncertainty quantification, epistemology, and more. This dissertation addresses criteria needed to take reliability seriously: both criteria for designing meaningful metrics, and for methodologies that ensure that we can dependably and efficiently measure these metrics at scale and in practice. In doing so, this dissertation articulates a research vision for a new field of scholarship at the intersection of machine learning, law, and policy. Within this frame, we cover topics that fit under three different themes: (1) quantifying and mitigating sources of arbitrariness in ML, (2) taming randomness in uncertainty estimation and optimization algorithms, in order to achieve scalability without sacrificing reliability, and (3) providing methods for evaluating generative-AI systems, with specific focuses on quantifying memorization in language models and training latent diffusion models on open-licensed data. By making contributions in these three themes, this dissertation serves as an empirical proof by example that research on reliable measurement for machine learning is intimately and inescapably bound up with research in law and policy. These different disciplines pose similar research questions about reliable measurement in machine learning. They are, in fact, two complementary sides of the same research vision, which, broadly construed, aims to construct machine-learning systems that cohere with broader societal values.
6/17/2024
📉
Exploring Precision and Recall to assess the quality and diversity of LLMs
Florian Le Bronnec, Alexandre Verine, Benjamin Negrevergne, Yann Chevaleyre, Alexandre Allauzen
0
0
We introduce a novel evaluation framework for Large Language Models (LLMs) such as textsc{Llama-2} and textsc{Mistral}, focusing on importing Precision and Recall metrics from image generation to text generation. This approach allows for a nuanced assessment of the quality and diversity of generated text without the need for aligned corpora. By conducting a comprehensive evaluation of state-of-the-art language models, the study reveals new insights into their performance on open-ended generation tasks, which are not adequately captured by traditional benchmarks. The findings highlight a trade-off between the quality and diversity of generated samples, particularly when models are fine-tuned on instruction dataset or with human feedback. This work extends the toolkit for distribution-based NLP evaluation, offering insights into the practical capabilities and challenges that current LLMs face in generating diverse and high-quality text. We release our code and data.
6/5/2024