Beyond Binary: Multiclass Paraphasia Detection with Generative Pretrained Transformers and End-to-End Models

0
Sign in to get full access
Overview
- The paper explores the task of multiclass paraphasia detection, which involves identifying different types of speech errors in language models.
- It compares the performance of generative pretrained transformers (GPTs) and end-to-end models on this task, aiming to go "beyond binary" classification.
- The researchers evaluate their models on a dataset of transcribed speech, including common paraphasic errors like phonemic, semantic, and neologistic paraphasias.
Plain English Explanation
The paper focuses on a problem called "multiclass paraphasia detection." This refers to the task of identifying different types of speech errors in language models, such as phonemic paraphasias, semantic paraphasias, and neologistic paraphasias.
The researchers compare the performance of two types of models on this task: generative pretrained transformers (GPTs) and end-to-end models. The goal is to go beyond simple binary classification (correct or incorrect) and accurately detect the specific type of speech error.
The models are evaluated on a dataset of transcribed speech that includes examples of these common paraphasic errors. By comparing the strengths and weaknesses of the different approaches, the researchers aim to provide insights into the best ways to tackle this challenging language understanding problem.
Technical Explanation
The paper explores the task of multiclass paraphasia detection, which involves identifying different types of speech errors in language models. It compares the performance of generative pretrained transformers (GPTs) and end-to-end models on this task.
The researchers evaluate their models on a dataset of transcribed speech, including common paraphasic errors like phonemic paraphasias, semantic paraphasias, and neologistic paraphasias. They use a combination of end-to-end models and GPTs to tackle the multiclass classification problem.
The results of the experiments provide insights into the relative strengths and weaknesses of the different approaches, helping to guide future research in this area of language understanding.
Critical Analysis
The paper presents a comprehensive evaluation of multiclass paraphasia detection, but there are a few potential limitations and areas for further research:
-
The dataset used, while substantial, may not capture the full range of paraphasic errors that can occur in real-world speech. Expanding the dataset to include more diverse examples could help validate the models' performance in a broader context.
-
The comparison between GPTs and end-to-end models is informative, but the researchers acknowledge that there may be other architectures or training approaches that could offer even better performance. Exploring a wider range of model designs could yield additional insights.
-
While the paper focuses on detecting different types of paraphasias, it does not delve into the underlying causes or implications of these speech errors. Further research into the cognitive and linguistic factors contributing to paraphasias could lead to a deeper understanding of the problem.
Overall, the paper makes a valuable contribution to the field of language understanding by demonstrating the potential of advanced models like GPTs and end-to-end architectures for multiclass paraphasia detection. The critical analysis points to areas for continued exploration and refinement of the research.
Conclusion
This paper presents an in-depth exploration of the task of multiclass paraphasia detection, which involves identifying different types of speech errors in language models. By comparing the performance of generative pretrained transformers (GPTs) and end-to-end models on a dataset of transcribed speech, the researchers provide insights into the strengths and limitations of these approaches.
The findings suggest that both GPTs and end-to-end models can effectively tackle the multiclass classification problem, going beyond simple binary detection of speech errors. This advancement in language understanding could have important implications for applications like assistive technology, speech therapy, and natural language processing.
While the paper offers a solid foundation for further research in this domain, the critical analysis highlights potential areas for expansion and refinement. Exploring a wider range of datasets, model architectures, and underlying factors contributing to paraphasias could lead to even more robust and comprehensive solutions for this challenging language understanding task.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Beyond Binary: Multiclass Paraphasia Detection with Generative Pretrained Transformers and End-to-End Models
Matthew Perez, Aneesha Sampath, Minxue Niu, Emily Mower Provost
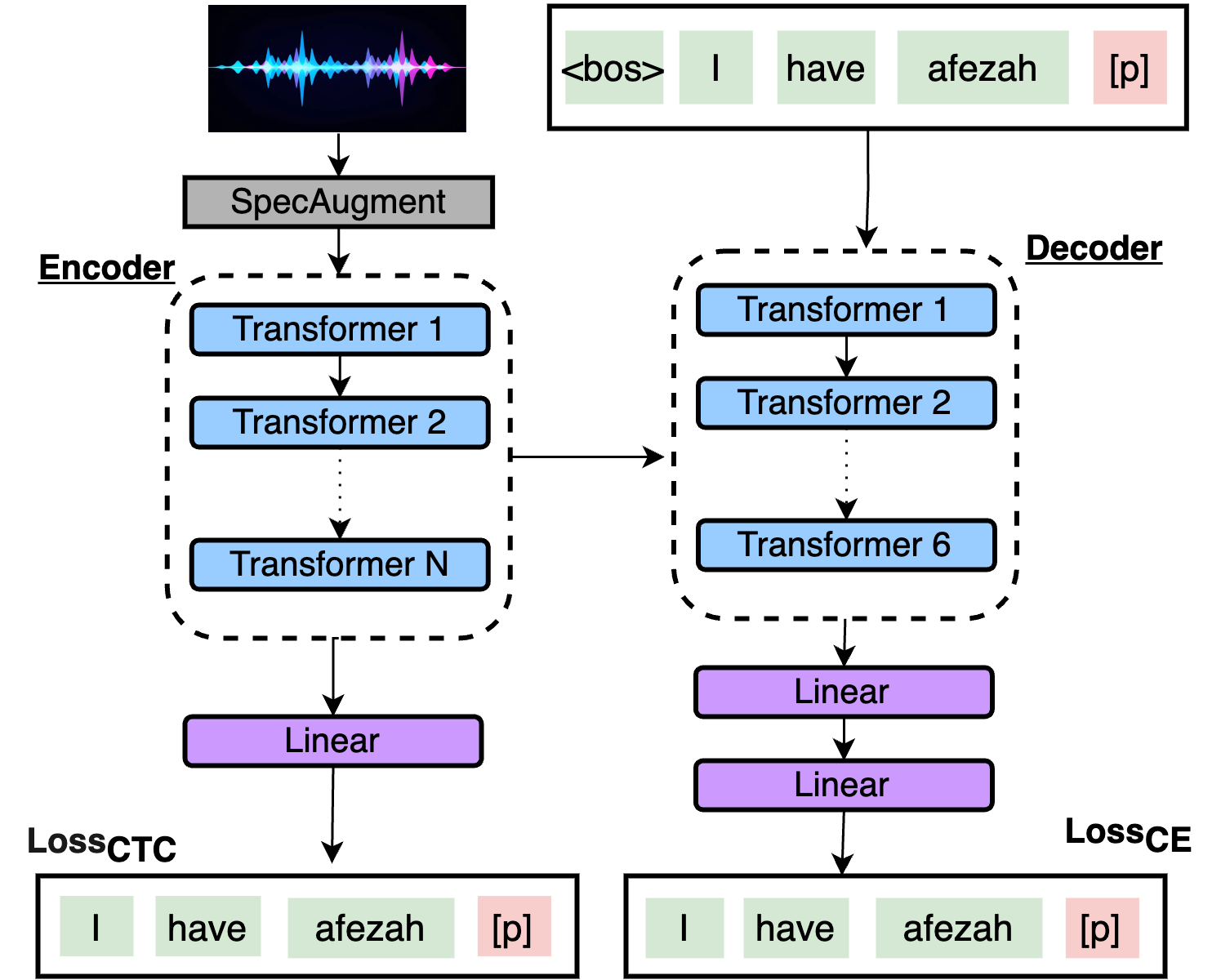
Aphasia is a language disorder that can lead to speech errors known as paraphasias, which involve the misuse, substitution, or invention of words. Automatic paraphasia detection can help those with Aphasia by facilitating clinical assessment and treatment planning options. However, most automatic paraphasia detection works have focused solely on binary detection, which involves recognizing only the presence or absence of a paraphasia. Multiclass paraphasia detection represents an unexplored area of research that focuses on identifying multiple types of paraphasias and where they occur in a given speech segment. We present novel approaches that use a generative pretrained transformer (GPT) to identify paraphasias from transcripts as well as two end-to-end approaches that focus on modeling both automatic speech recognition (ASR) and paraphasia classification as multiple sequences vs. a single sequence. We demonstrate that a single sequence model outperforms GPT baselines for multiclass paraphasia detection.
Read more7/17/2024
🛸
0
Paraphrase Types for Generation and Detection
Jan Philip Wahle, Bela Gipp, Terry Ruas
Current approaches in paraphrase generation and detection heavily rely on a single general similarity score, ignoring the intricate linguistic properties of language. This paper introduces two new tasks to address this shortcoming by considering paraphrase types - specific linguistic perturbations at particular text positions. We name these tasks Paraphrase Type Generation and Paraphrase Type Detection. Our results suggest that while current techniques perform well in a binary classification scenario, i.e., paraphrased or not, the inclusion of fine-grained paraphrase types poses a significant challenge. While most approaches are good at generating and detecting general semantic similar content, they fail to understand the intrinsic linguistic variables they manipulate. Models trained in generating and identifying paraphrase types also show improvements in tasks without them. In addition, scaling these models further improves their ability to understand paraphrase types. We believe paraphrase types can unlock a new paradigm for developing paraphrase models and solving tasks in the future.
Read more7/17/2024

0
Listen Again and Choose the Right Answer: A New Paradigm for Automatic Speech Recognition with Large Language Models
Yuchen Hu, Chen Chen, Chengwei Qin, Qiushi Zhu, Eng Siong Chng, Ruizhe Li
Recent advances in large language models (LLMs) have promoted generative error correction (GER) for automatic speech recognition (ASR), which aims to predict the ground-truth transcription from the decoded N-best hypotheses. Thanks to the strong language generation ability of LLMs and rich information in the N-best list, GER shows great effectiveness in enhancing ASR results. However, it still suffers from two limitations: 1) LLMs are unaware of the source speech during GER, which may lead to results that are grammatically correct but violate the source speech content, 2) N-best hypotheses usually only vary in a few tokens, making it redundant to send all of them for GER, which could confuse LLM about which tokens to focus on and thus lead to increased miscorrection. In this paper, we propose ClozeGER, a new paradigm for ASR generative error correction. First, we introduce a multimodal LLM (i.e., SpeechGPT) to receive source speech as extra input to improve the fidelity of correction output. Then, we reformat GER as a cloze test with logits calibration to remove the input information redundancy and simplify GER with clear instructions. Experiments show that ClozeGER achieves a new breakthrough over vanilla GER on 9 popular ASR datasets.
Read more5/17/2024

0
New!PARAPHRASUS : A Comprehensive Benchmark for Evaluating Paraphrase Detection Models
Andrianos Michail, Simon Clematide, Juri Opitz
The task of determining whether two texts are paraphrases has long been a challenge in NLP. However, the prevailing notion of paraphrase is often quite simplistic, offering only a limited view of the vast spectrum of paraphrase phenomena. Indeed, we find that evaluating models in a paraphrase dataset can leave uncertainty about their true semantic understanding. To alleviate this, we release paraphrasus, a benchmark designed for multi-dimensional assessment of paraphrase detection models and finer model selection. We find that paraphrase detection models under a fine-grained evaluation lens exhibit trade-offs that cannot be captured through a single classification dataset.
Read more9/19/2024