PARAPHRASUS : A Comprehensive Benchmark for Evaluating Paraphrase Detection Models

0

Sign in to get full access
Overview
- The paper introduces PARAPHRASUS, a comprehensive benchmark for evaluating paraphrase detection models.
- PARAPHRASUS includes diverse and challenging paraphrase pairs across various linguistic phenomena.
- The benchmark aims to provide a more thorough assessment of model capabilities compared to existing datasets.
Plain English Explanation
The research paper presents PARAPHRASUS, a new dataset designed to evaluate how well machine learning models can detect when two sentences have the same meaning, even if the wording is different. This is an important task in natural language processing, as it helps systems better understand human language.
Existing datasets for paraphrase detection have limitations, such as only covering certain types of paraphrases or not being challenging enough. PARAPHRASUS aims to address these issues by including a diverse range of paraphrase examples that test a model's ability to handle various linguistic phenomena, like paraphrase types, natural language errors, and cross-lingual paraphrases.
By providing a more comprehensive benchmark, the researchers hope to enable a better evaluation of paraphrase detection models and drive progress in this important area of natural language understanding.
Technical Explanation
The PARAPHRASUS dataset was created by the researchers to address limitations in existing paraphrase detection benchmarks. These existing datasets often focus on specific types of paraphrases or do not present sufficiently challenging examples to thoroughly test model capabilities.
To create PARAPHRASUS, the researchers compiled paraphrase pairs from various sources, including existing datasets, crowdsourcing, and paraphrase generation models. The resulting dataset contains over 50,000 paraphrase pairs spanning a wide range of linguistic phenomena, such as lexical, syntactic, and semantic variations.
The researchers evaluated several state-of-the-art paraphrase detection models on the PARAPHRASUS benchmark and found that even the best-performing models struggled with certain types of paraphrases, such as those involving natural language errors or cross-lingual pairs. This suggests that PARAPHRASUS provides a more comprehensive assessment of model performance compared to previous benchmarks.
Critical Analysis
The PARAPHRASUS benchmark addresses important limitations in existing paraphrase detection datasets, providing a more challenging and diverse set of examples to evaluate model capabilities. By including a wider range of linguistic phenomena, the benchmark can help identify areas where current paraphrase detection models still struggle.
However, the paper does not delve deep into the specific errors or weaknesses observed in the evaluated models. It would be helpful to have a more detailed analysis of the types of paraphrases that proved most challenging and the potential reasons why.
Additionally, the paper does not discuss the potential biases or limitations of the dataset itself. It would be valuable to understand if certain linguistic or demographic factors are overrepresented or underrepresented in the PARAPHRASUS examples, which could impact the generalizability of the benchmark.
Overall, the PARAPHRASUS benchmark represents a significant contribution to the field of natural language processing, but additional research and analysis could help further improve its usefulness and impact.
Conclusion
The PARAPHRASUS benchmark introduces a comprehensive dataset for evaluating paraphrase detection models, addressing limitations in existing benchmarks. By including a diverse range of paraphrase types, the benchmark can provide a more thorough assessment of model capabilities and help identify areas for further improvement.
The results presented in the paper suggest that even state-of-the-art models struggle with certain types of paraphrases, highlighting the need for continued research and development in this important area of natural language understanding. The PARAPHRASUS dataset can serve as a valuable tool for driving progress in paraphrase detection and advancing the field of natural language processing as a whole.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
New!PARAPHRASUS : A Comprehensive Benchmark for Evaluating Paraphrase Detection Models
Andrianos Michail, Simon Clematide, Juri Opitz
The task of determining whether two texts are paraphrases has long been a challenge in NLP. However, the prevailing notion of paraphrase is often quite simplistic, offering only a limited view of the vast spectrum of paraphrase phenomena. Indeed, we find that evaluating models in a paraphrase dataset can leave uncertainty about their true semantic understanding. To alleviate this, we release paraphrasus, a benchmark designed for multi-dimensional assessment of paraphrase detection models and finer model selection. We find that paraphrase detection models under a fine-grained evaluation lens exhibit trade-offs that cannot be captured through a single classification dataset.
Read more9/19/2024
🛸
0
Paraphrase Types for Generation and Detection
Jan Philip Wahle, Bela Gipp, Terry Ruas
Current approaches in paraphrase generation and detection heavily rely on a single general similarity score, ignoring the intricate linguistic properties of language. This paper introduces two new tasks to address this shortcoming by considering paraphrase types - specific linguistic perturbations at particular text positions. We name these tasks Paraphrase Type Generation and Paraphrase Type Detection. Our results suggest that while current techniques perform well in a binary classification scenario, i.e., paraphrased or not, the inclusion of fine-grained paraphrase types poses a significant challenge. While most approaches are good at generating and detecting general semantic similar content, they fail to understand the intrinsic linguistic variables they manipulate. Models trained in generating and identifying paraphrase types also show improvements in tasks without them. In addition, scaling these models further improves their ability to understand paraphrase types. We believe paraphrase types can unlock a new paradigm for developing paraphrase models and solving tasks in the future.
Read more7/17/2024
0
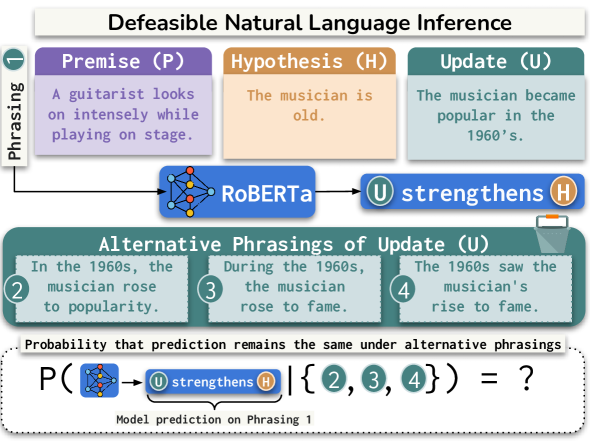
How often are errors in natural language reasoning due to paraphrastic variability?
Neha Srikanth, Marine Carpuat, Rachel Rudinger
Large language models have been shown to behave inconsistently in response to meaning-preserving paraphrastic inputs. At the same time, researchers evaluate the knowledge and reasoning abilities of these models with test evaluations that do not disaggregate the effect of paraphrastic variability on performance. We propose a metric for evaluating the paraphrastic consistency of natural language reasoning models based on the probability of a model achieving the same correctness on two paraphrases of the same problem. We mathematically connect this metric to the proportion of a model's variance in correctness attributable to paraphrasing. To estimate paraphrastic consistency, we collect ParaNLU, a dataset of 7,782 human-written and validated paraphrased reasoning problems constructed on top of existing benchmark datasets for defeasible and abductive natural language inference. Using ParaNLU, we measure the paraphrastic consistency of several model classes and show that consistency dramatically increases with pretraining but not finetuning. All models tested exhibited room for improvement in paraphrastic consistency.
Read more4/19/2024
0
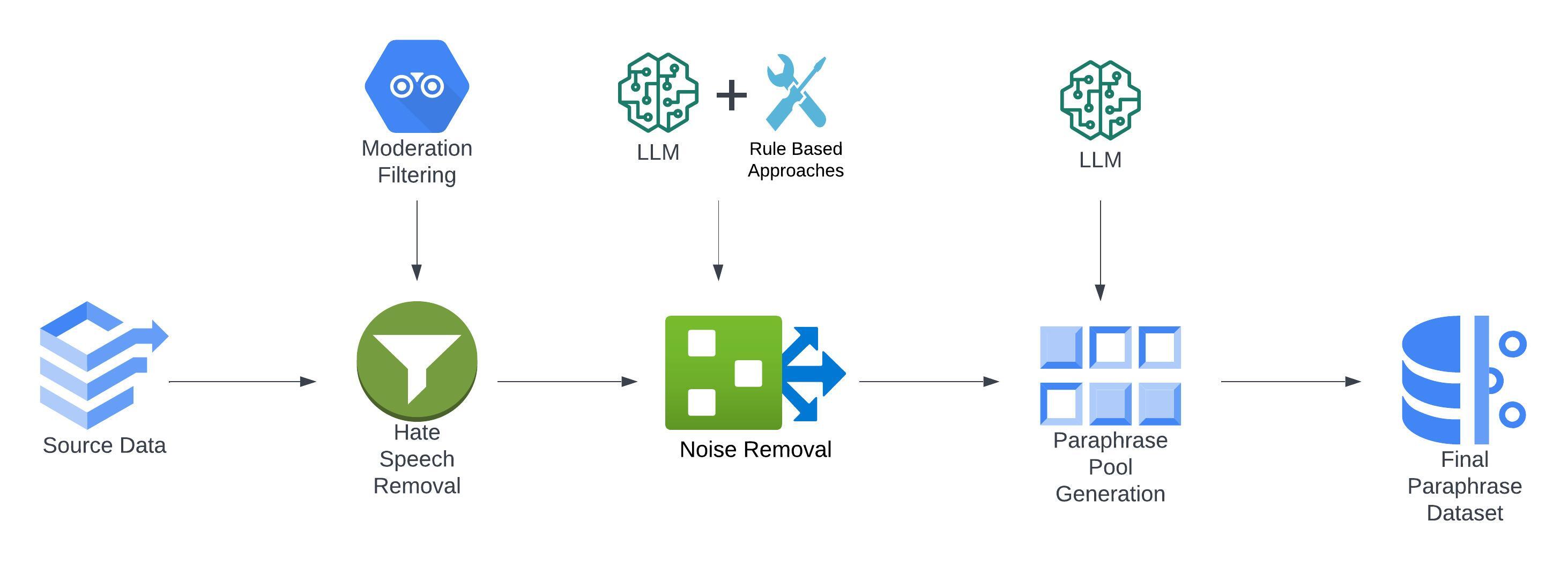
ParaFusion: A Large-Scale LLM-Driven English Paraphrase Dataset Infused with High-Quality Lexical and Syntactic Diversity
Lasal Jayawardena, Prasan Yapa
Paraphrase generation is a pivotal task in natural language processing (NLP). Existing datasets in the domain lack syntactic and lexical diversity, resulting in paraphrases that closely resemble the source sentences. Moreover, these datasets often contain hate speech and noise, and may unintentionally include non-English language sentences. This research introduces ParaFusion, a large-scale, high-quality English paraphrase dataset developed using Large Language Models (LLM) to address these challenges. ParaFusion augments existing datasets with high-quality data, significantly enhancing both lexical and syntactic diversity while maintaining close semantic similarity. It also mitigates the presence of hate speech and reduces noise, ensuring a cleaner and more focused English dataset. Results show that ParaFusion offers at least a 25% improvement in both syntactic and lexical diversity, measured across several metrics for each data source. The paper also aims to set a gold standard for paraphrase evaluation as it contains one of the most comprehensive evaluation strategies to date. The results underscore the potential of ParaFusion as a valuable resource for improving NLP applications.
Read more4/19/2024