Paraphrase Types for Generation and Detection

0
🛸
Sign in to get full access
Overview
- This paper introduces two new tasks to address the limitations of current approaches in paraphrase generation and detection
- Current techniques rely on a single general similarity score, ignoring the intricate linguistic properties of language
- The new tasks, Paraphrase Type Generation and Paraphrase Type Detection, consider specific linguistic perturbations at particular text positions
Plain English Explanation
The paper argues that current methods for generating and detecting paraphrases heavily rely on a single overall similarity score, without considering the nuanced linguistic features of language. To address this, the researchers introduce two new tasks: Paraphrase Type Generation and Paraphrase Type Detection.
These tasks focus on identifying specific types of linguistic changes, such as changes in word order or sentence structure, rather than just looking at whether the overall meaning is similar. The key idea is that while current techniques may perform well in simply classifying text as paraphrased or not, they struggle to understand the underlying linguistic properties that are being manipulated.
By training models to generate and detect these paraphrase types, the researchers believe we can develop a more sophisticated understanding of language and unlock new possibilities for paraphrase-related tasks. This could have applications in cross-lingual paraphrase identification, detecting machine-generated text, and plagiarism detection.
Technical Explanation
The paper introduces two new tasks to address the limitations of current approaches in paraphrase generation and detection:
-
Paraphrase Type Generation: Generating paraphrases that exhibit specific linguistic perturbations, such as changes in word order, substitutions, or sentence structure.
-
Paraphrase Type Detection: Identifying the specific types of linguistic changes present in a given paraphrase, rather than just classifying it as a paraphrase or not.
The researchers find that while existing techniques perform well in binary paraphrase classification, they struggle to understand and manipulate the underlying linguistic variables. Models trained on the new paraphrase type tasks show improvements in their ability to generate and detect these linguistic nuances, which in turn leads to better performance on other tasks without explicitly modeling paraphrase types.
The paper presents experiments demonstrating the challenges of the new tasks and the benefits of incorporating paraphrase type modeling. The researchers also discuss how scaling these models further can enhance their understanding of the linguistic aspects of paraphrasing.
Critical Analysis
The paper raises an important point about the limitations of current paraphrase generation and detection approaches, which often rely on a single, coarse-grained similarity score. By introducing the paraphrase type tasks, the researchers push the field to consider the more granular linguistic properties of language.
One potential limitation is that the specific types of linguistic perturbations considered in the paper may not be exhaustive, and there could be other important linguistic variables that impact paraphrasing. Additionally, the practical applications of the paraphrase type tasks, such as in machine translation or text summarization, are not fully explored.
Nevertheless, the core idea of incorporating linguistic nuance into paraphrase modeling is compelling and could lead to more robust and interpretable systems. The paper encourages readers to think critically about the limitations of current approaches and the potential benefits of a more linguistically-aware perspective on paraphrase generation and detection.
Conclusion
This paper introduces two new tasks, Paraphrase Type Generation and Paraphrase Type Detection, to address the shortcomings of current paraphrase approaches that rely solely on general similarity scores. By focusing on the specific linguistic properties that are manipulated in paraphrasing, the researchers aim to develop more sophisticated models that can better understand and generate paraphrases.
The results suggest that while existing techniques perform well in binary paraphrase classification, they struggle to capture the underlying linguistic variables. Incorporating paraphrase type modeling can lead to improved performance on a range of tasks, potentially unlocking new possibilities for paraphrase-related applications in areas like machine translation, text summarization, and plagiarism detection.
Overall, this paper highlights the importance of considering linguistic nuance in paraphrase generation and detection, and encourages the development of more linguistically-aware approaches to advance the field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛸
0
Paraphrase Types for Generation and Detection
Jan Philip Wahle, Bela Gipp, Terry Ruas
Current approaches in paraphrase generation and detection heavily rely on a single general similarity score, ignoring the intricate linguistic properties of language. This paper introduces two new tasks to address this shortcoming by considering paraphrase types - specific linguistic perturbations at particular text positions. We name these tasks Paraphrase Type Generation and Paraphrase Type Detection. Our results suggest that while current techniques perform well in a binary classification scenario, i.e., paraphrased or not, the inclusion of fine-grained paraphrase types poses a significant challenge. While most approaches are good at generating and detecting general semantic similar content, they fail to understand the intrinsic linguistic variables they manipulate. Models trained in generating and identifying paraphrase types also show improvements in tasks without them. In addition, scaling these models further improves their ability to understand paraphrase types. We believe paraphrase types can unlock a new paradigm for developing paraphrase models and solving tasks in the future.
Read more7/17/2024
0
Paraphrase Types Elicit Prompt Engineering Capabilities
Jan Philip Wahle, Terry Ruas, Yang Xu, Bela Gipp
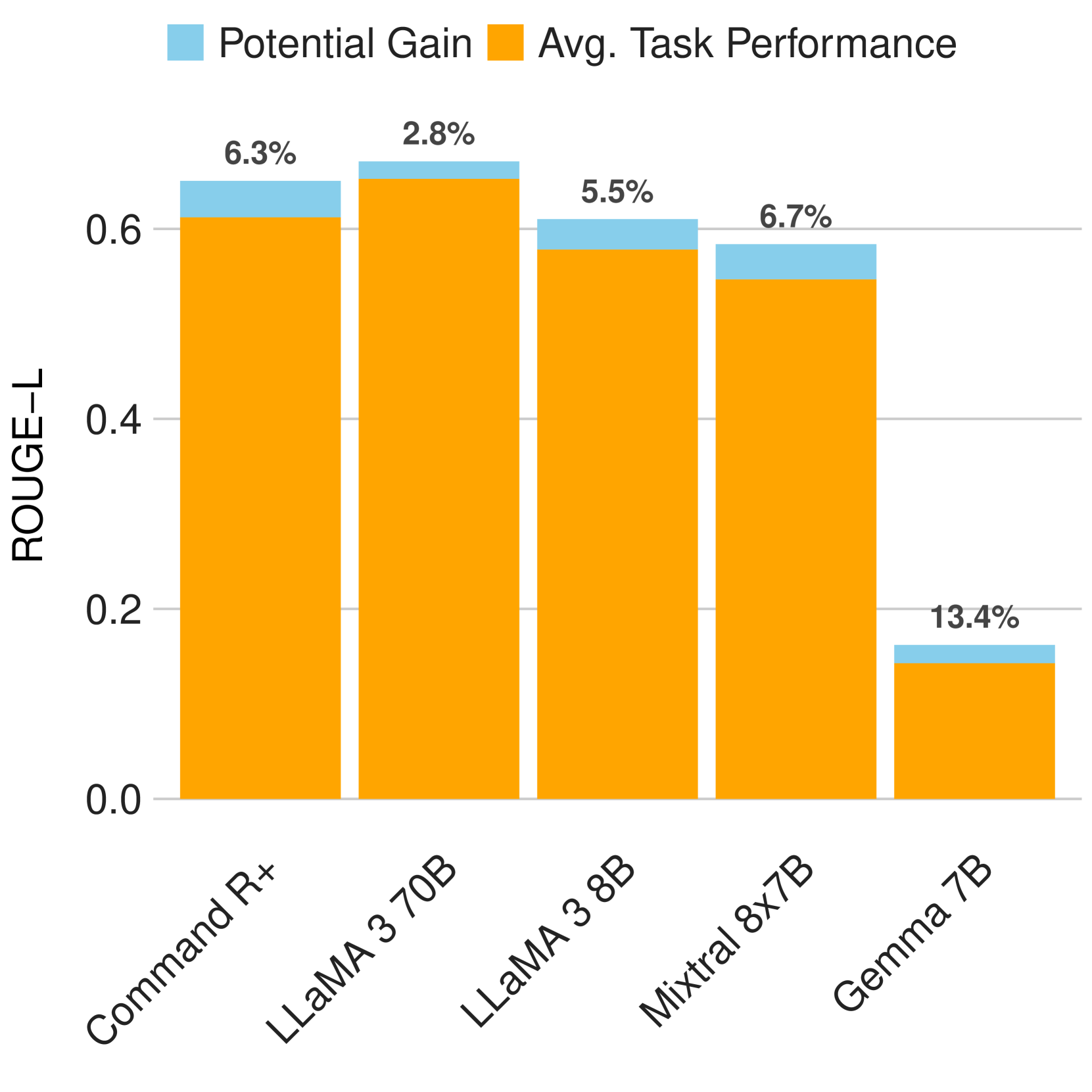
Much of the success of modern language models depends on finding a suitable prompt to instruct the model. Until now, it has been largely unknown how variations in the linguistic expression of prompts affect these models. This study systematically and empirically evaluates which linguistic features influence models through paraphrase types, i.e., different linguistic changes at particular positions. We measure behavioral changes for five models across 120 tasks and six families of paraphrases (i.e., morphology, syntax, lexicon, lexico-syntax, discourse, and others). We also control for other prompt engineering factors (e.g., prompt length, lexical diversity, and proximity to training data). Our results show a potential for language models to improve tasks when their prompts are adapted in specific paraphrase types (e.g., 6.7% median gain in Mixtral 8x7B; 5.5% in LLaMA 3 8B). In particular, changes in morphology and lexicon, i.e., the vocabulary used, showed promise in improving prompts. These findings contribute to developing more robust language models capable of handling variability in linguistic expression.
Read more7/1/2024
🤷
0
Spotting AI's Touch: Identifying LLM-Paraphrased Spans in Text
Yafu Li, Zhilin Wang, Leyang Cui, Wei Bi, Shuming Shi, Yue Zhang
AI-generated text detection has attracted increasing attention as powerful language models approach human-level generation. Limited work is devoted to detecting (partially) AI-paraphrased texts. However, AI paraphrasing is commonly employed in various application scenarios for text refinement and diversity. To this end, we propose a novel detection framework, paraphrased text span detection (PTD), aiming to identify paraphrased text spans within a text. Different from text-level detection, PTD takes in the full text and assigns each of the sentences with a score indicating the paraphrasing degree. We construct a dedicated dataset, PASTED, for paraphrased text span detection. Both in-distribution and out-of-distribution results demonstrate the effectiveness of PTD models in identifying AI-paraphrased text spans. Statistical and model analysis explains the crucial role of the surrounding context of the paraphrased text spans. Extensive experiments show that PTD models can generalize to versatile paraphrasing prompts and multiple paraphrased text spans. We release our resources at https://github.com/Linzwcs/PASTED.
Read more5/30/2024
0
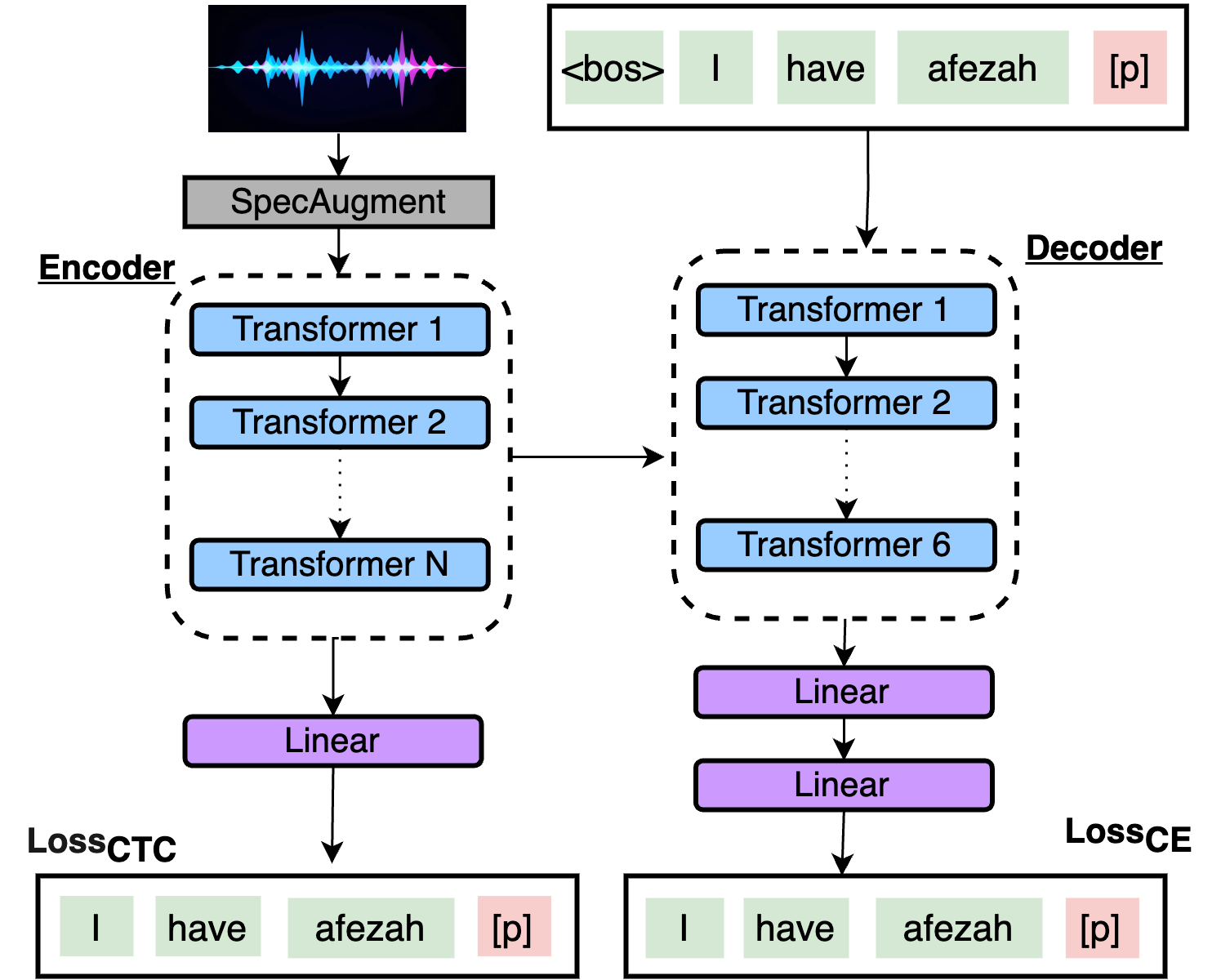
Beyond Binary: Multiclass Paraphasia Detection with Generative Pretrained Transformers and End-to-End Models
Matthew Perez, Aneesha Sampath, Minxue Niu, Emily Mower Provost
Aphasia is a language disorder that can lead to speech errors known as paraphasias, which involve the misuse, substitution, or invention of words. Automatic paraphasia detection can help those with Aphasia by facilitating clinical assessment and treatment planning options. However, most automatic paraphasia detection works have focused solely on binary detection, which involves recognizing only the presence or absence of a paraphasia. Multiclass paraphasia detection represents an unexplored area of research that focuses on identifying multiple types of paraphasias and where they occur in a given speech segment. We present novel approaches that use a generative pretrained transformer (GPT) to identify paraphasias from transcripts as well as two end-to-end approaches that focus on modeling both automatic speech recognition (ASR) and paraphasia classification as multiple sequences vs. a single sequence. We demonstrate that a single sequence model outperforms GPT baselines for multiclass paraphasia detection.
Read more7/17/2024