Beyond the Field-of-View: Enhancing Scene Visibility and Perception with Clip-Recurrent Transformer

0
💬
Sign in to get full access
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
0
Beyond the Field-of-View: Enhancing Scene Visibility and Perception with Clip-Recurrent Transformer
Hao Shi, Qi Jiang, Kailun Yang, Xiaoting Yin, Ze Wang, Kaiwei Wang
Vision sensors are widely applied in vehicles, robots, and roadside infrastructure. However, due to limitations in hardware cost and system size, camera Field-of-View (FoV) is often restricted and may not provide sufficient coverage. Nevertheless, from a spatiotemporal perspective, it is possible to obtain information beyond the camera's physical FoV from past video streams. In this paper, we propose the concept of online video inpainting for autonomous vehicles to expand the field of view, thereby enhancing scene visibility, perception, and system safety. To achieve this, we introduce the FlowLens architecture, which explicitly employs optical flow and implicitly incorporates a novel clip-recurrent transformer for feature propagation. FlowLens offers two key features: 1) FlowLens includes a newly designed Clip-Recurrent Hub with 3D-Decoupled Cross Attention (DDCA) to progressively process global information accumulated over time. 2) It integrates a multi-branch Mix Fusion Feed Forward Network (MixF3N) to enhance the precise spatial flow of local features. To facilitate training and evaluation, we derive the KITTI360 dataset with various FoV mask, which covers both outer- and inner FoV expansion scenarios. We also conduct both quantitative assessments and qualitative comparisons of beyond-FoV semantics and beyond-FoV object detection across different models. We illustrate that employing FlowLens to reconstruct unseen scenes even enhances perception within the field of view by providing reliable semantic context. Extensive experiments and user studies involving offline and online video inpainting, as well as beyond-FoV perception tasks, demonstrate that FlowLens achieves state-of-the-art performance. The source code and dataset are made publicly available at https://github.com/MasterHow/FlowLens.
Read more6/26/2024

0
Enhanced Parking Perception by Multi-Task Fisheye Cross-view Transformers
Antonyo Musabini, Ivan Novikov, Sana Soula, Christel Leonet, Lihao Wang, Rachid Benmokhtar, Fabian Burger, Thomas Boulay, Xavier Perrotton
Current parking area perception algorithms primarily focus on detecting vacant slots within a limited range, relying on error-prone homographic projection for both labeling and inference. However, recent advancements in Advanced Driver Assistance System (ADAS) require interaction with end-users through comprehensive and intelligent Human-Machine Interfaces (HMIs). These interfaces should present a complete perception of the parking area going from distinguishing vacant slots' entry lines to the orientation of other parked vehicles. This paper introduces Multi-Task Fisheye Cross View Transformers (MT F-CVT), which leverages features from a four-camera fisheye Surround-view Camera System (SVCS) with multihead attentions to create a detailed Bird-Eye View (BEV) grid feature map. Features are processed by both a segmentation decoder and a Polygon-Yolo based object detection decoder for parking slots and vehicles. Trained on data labeled using LiDAR, MT F-CVT positions objects within a 25m x 25m real open-road scenes with an average error of only 20 cm. Our larger model achieves an F-1 score of 0.89. Moreover the smaller model operates at 16 fps on an Nvidia Jetson Orin embedded board, with similar detection results to the larger one. MT F-CVT demonstrates robust generalization capability across different vehicles and camera rig configurations. A demo video from an unseen vehicle and camera rig is available at: https://streamable.com/jjw54x.
Read more8/23/2024
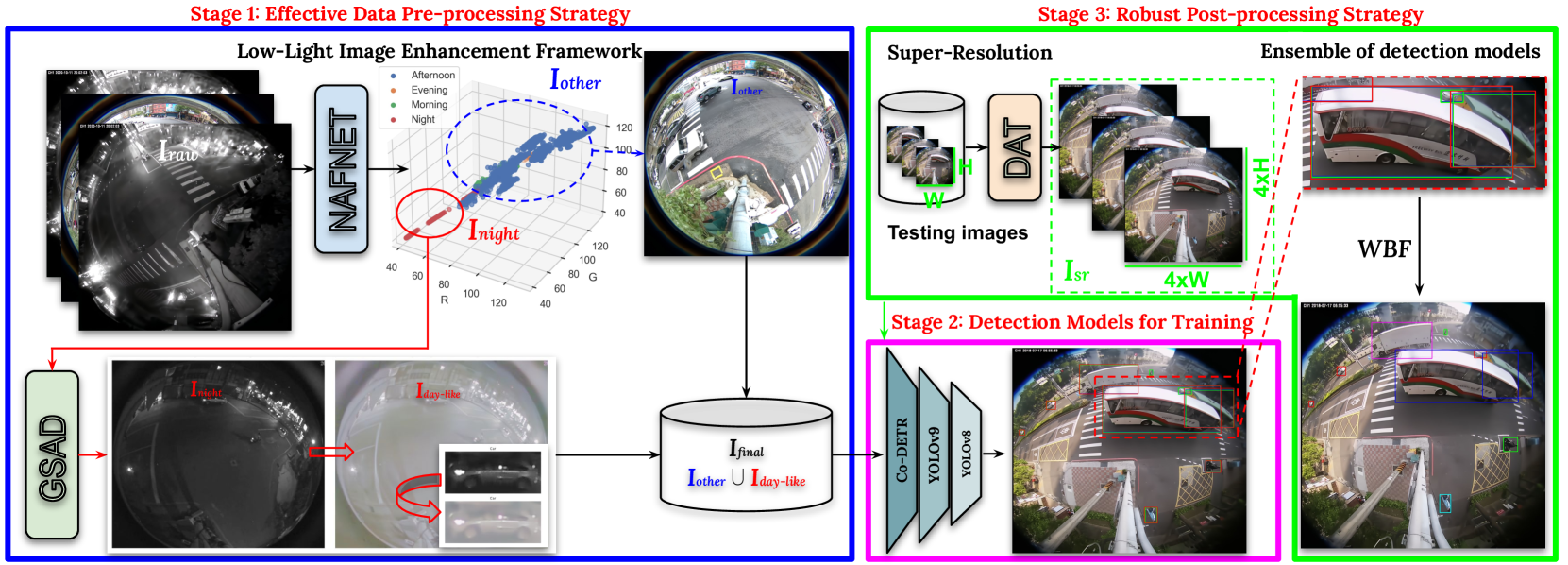
0
Low-Light Image Enhancement Framework for Improved Object Detection in Fisheye Lens Datasets
Dai Quoc Tran, Armstrong Aboah, Yuntae Jeon, Maged Shoman, Minsoo Park, Seunghee Park
This study addresses the evolving challenges in urban traffic monitoring detection systems based on fisheye lens cameras by proposing a framework that improves the efficacy and accuracy of these systems. In the context of urban infrastructure and transportation management, advanced traffic monitoring systems have become critical for managing the complexities of urbanization and increasing vehicle density. Traditional monitoring methods, which rely on static cameras with narrow fields of view, are ineffective in dynamic urban environments, necessitating the installation of multiple cameras, which raises costs. Fisheye lenses, which were recently introduced, provide wide and omnidirectional coverage in a single frame, making them a transformative solution. However, issues such as distorted views and blurriness arise, preventing accurate object detection on these images. Motivated by these challenges, this study proposes a novel approach that combines a ransformer-based image enhancement framework and ensemble learning technique to address these challenges and improve traffic monitoring accuracy, making significant contributions to the future of intelligent traffic management systems. Our proposed methodological framework won 5th place in the 2024 AI City Challenge, Track 4, with an F1 score of 0.5965 on experimental validation data. The experimental results demonstrate the effectiveness, efficiency, and robustness of the proposed system. Our code is publicly available at https://github.com/daitranskku/AIC2024-TRACK4-TEAM15.
Read more4/17/2024

0
FoVNet: Configurable Field-of-View Speech Enhancement with Low Computation and Distortion for Smart Glasses
Zhongweiyang Xu, Ali Aroudi, Ke Tan, Ashutosh Pandey, Jung-Suk Lee, Buye Xu, Francesco Nesta
This paper presents a novel multi-channel speech enhancement approach, FoVNet, that enables highly efficient speech enhancement within a configurable field of view (FoV) of a smart-glasses user without needing specific target-talker(s) directions. It advances over prior works by enhancing all speakers within any given FoV, with a hybrid signal processing and deep learning approach designed with high computational efficiency. The neural network component is designed with ultra-low computation (about 50 MMACS). A multi-channel Wiener filter and a post-processing module are further used to improve perceptual quality. We evaluate our algorithm with a microphone array on smart glasses, providing a configurable, efficient solution for augmented hearing on energy-constrained devices. FoVNet excels in both computational efficiency and speech quality across multiple scenarios, making it a promising solution for smart glasses applications.
Read more8/14/2024