Enhanced Parking Perception by Multi-Task Fisheye Cross-view Transformers

0

Sign in to get full access
Overview
- This paper proposes a novel multi-task fisheye cross-view transformer model to enhance parking perception for autonomous vehicles.
- The model leverages fisheye camera data to generate a bird's-eye-view (BEV) representation, which is then used for various parking-related tasks.
- Key innovations include a cross-view transformer module and a multi-task learning framework that enables joint optimization of parking spot detection, free space segmentation, and vehicle pose estimation.
Plain English Explanation
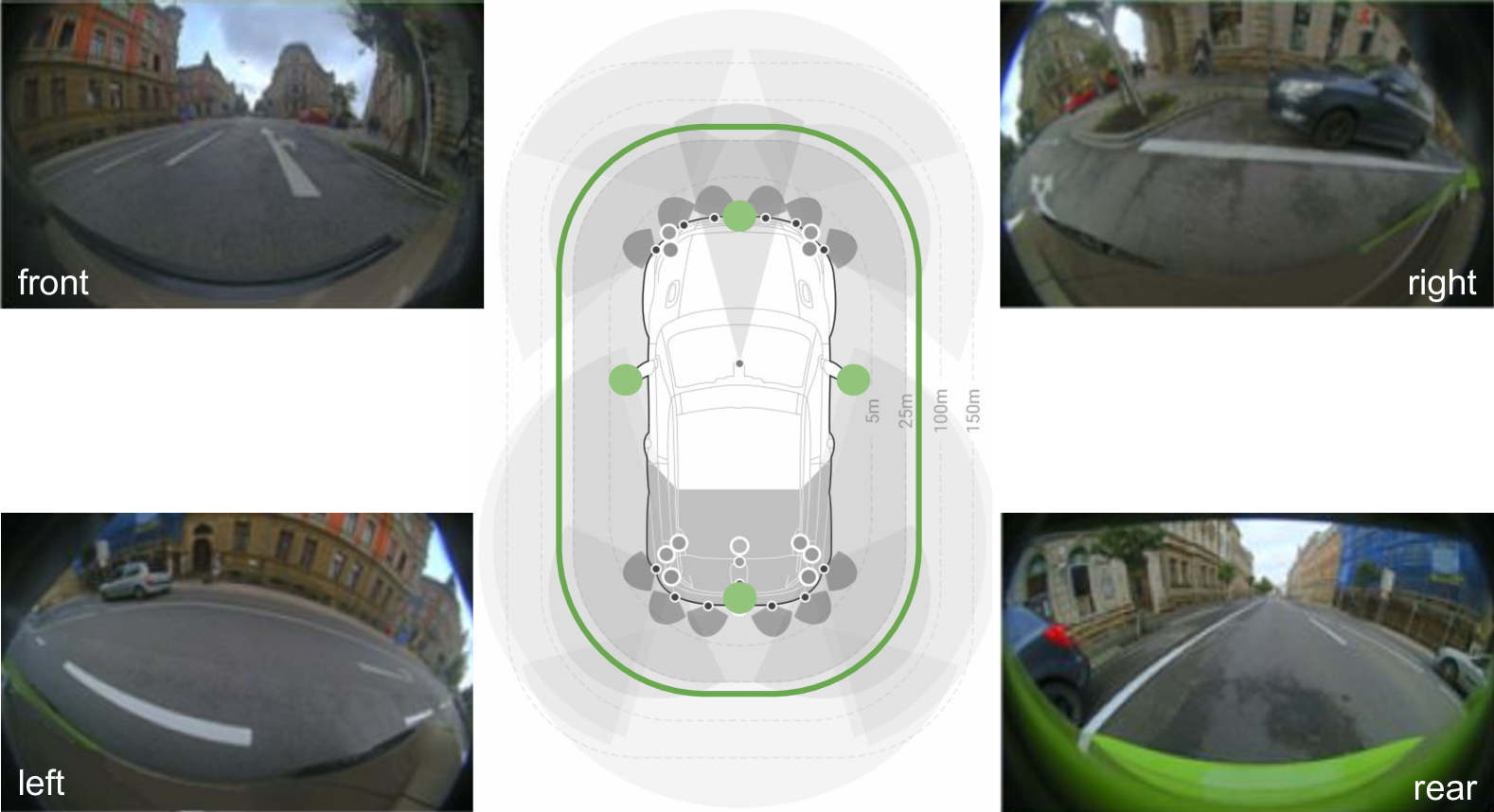
The paper describes a new deep learning model that is designed to help self-driving cars better understand their parking environment. The key idea is to use a special type of camera called a "fisheye" camera, which can capture a very wide, curved field of view.
The model takes the data from the fisheye camera and uses a transformer network to convert it into a bird's-eye-view representation. This bird's-eye-view provides a top-down perspective that makes it easier for the model to detect things like available parking spots, free space on the ground, and the positions of surrounding vehicles.
The model is trained to perform multiple related tasks simultaneously - detecting parking spots, segmenting free space, and estimating the poses of nearby vehicles. This "multi-task" approach allows the different components of the model to learn from each other and produce more accurate overall results.
Overall, the goal is to give self-driving cars a more comprehensive understanding of their parking environment, which could lead to better parking maneuvers and safer interactions with other vehicles and obstacles.
Technical Explanation
The core of the proposed model is a cross-view transformer module that takes in the distorted fisheye camera input and produces a bird's-eye-view (BEV) representation. This BEV view is then fed into separate prediction heads for parking spot detection, free space segmentation, and vehicle pose estimation.
The cross-view transformer leverages the self-attention mechanism of transformers to learn spatial relationships between different parts of the fisheye image and aggregate relevant features into the BEV format. This allows the model to effectively handle the challenging distortions and perspective changes inherent to fisheye camera data.
The multi-task learning framework enables the model to jointly optimize the three parking-related tasks, with shared backbone features and cross-task interactions. This leads to improved performance compared to training separate models for each task independently.
Critical Analysis
The paper presents a compelling approach for enhancing parking perception using fisheye cameras and a multi-task transformer-based architecture. Some key strengths include:
- The cross-view transformer's ability to effectively handle fisheye distortions
- The benefits of the multi-task learning setup for jointly optimizing complementary parking tasks
- The potential for the model to provide a comprehensive, bird's-eye understanding of the parking environment
However, the paper also acknowledges some limitations:
- The model was only evaluated on a single dataset, so its generalization to diverse real-world parking scenarios remains to be seen. The authors also note that the current BEV representation may struggle to capture fine-grained details, which could impact tasks like precise vehicle pose estimation.
Further research could explore ways to refine the BEV outputs, incorporate additional sensor modalities, and validate the model's performance in more diverse parking environments.
Conclusion
This paper presents an innovative multi-task fisheye cross-view transformer model that aims to enhance parking perception for autonomous vehicles. By leveraging fisheye camera data and a transformer-based architecture, the model is able to effectively generate a bird's-eye-view representation that supports key parking-related tasks like spot detection, free space segmentation, and vehicle pose estimation.
The proposed approach represents an important step forward in enabling self-driving cars to better understand and navigate complex parking scenarios. If successfully deployed, this technology could contribute to more efficient and safer parking maneuvers, ultimately improving the overall user experience and safety of autonomous driving systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Enhanced Parking Perception by Multi-Task Fisheye Cross-view Transformers
Antonyo Musabini, Ivan Novikov, Sana Soula, Christel Leonet, Lihao Wang, Rachid Benmokhtar, Fabian Burger, Thomas Boulay, Xavier Perrotton
Current parking area perception algorithms primarily focus on detecting vacant slots within a limited range, relying on error-prone homographic projection for both labeling and inference. However, recent advancements in Advanced Driver Assistance System (ADAS) require interaction with end-users through comprehensive and intelligent Human-Machine Interfaces (HMIs). These interfaces should present a complete perception of the parking area going from distinguishing vacant slots' entry lines to the orientation of other parked vehicles. This paper introduces Multi-Task Fisheye Cross View Transformers (MT F-CVT), which leverages features from a four-camera fisheye Surround-view Camera System (SVCS) with multihead attentions to create a detailed Bird-Eye View (BEV) grid feature map. Features are processed by both a segmentation decoder and a Polygon-Yolo based object detection decoder for parking slots and vehicles. Trained on data labeled using LiDAR, MT F-CVT positions objects within a 25m x 25m real open-road scenes with an average error of only 20 cm. Our larger model achieves an F-1 score of 0.89. Moreover the smaller model operates at 16 fps on an Nvidia Jetson Orin embedded board, with similar detection results to the larger one. MT F-CVT demonstrates robust generalization capability across different vehicles and camera rig configurations. A demo video from an unseen vehicle and camera rig is available at: https://streamable.com/jjw54x.
Read more8/23/2024

0
Improved Single Camera BEV Perception Using Multi-Camera Training
Daniel Busch, Ido Freeman, Richard Meyes, Tobias Meisen
Bird's Eye View (BEV) map prediction is essential for downstream autonomous driving tasks like trajectory prediction. In the past, this was accomplished through the use of a sophisticated sensor configuration that captured a surround view from multiple cameras. However, in large-scale production, cost efficiency is an optimization goal, so that using fewer cameras becomes more relevant. But the consequence of fewer input images correlates with a performance drop. This raises the problem of developing a BEV perception model that provides a sufficient performance on a low-cost sensor setup. Although, primarily relevant for inference time on production cars, this cost restriction is less problematic on a test vehicle during training. Therefore, the objective of our approach is to reduce the aforementioned performance drop as much as possible using a modern multi-camera surround view model reduced for single-camera inference. The approach includes three features, a modern masking technique, a cyclic Learning Rate (LR) schedule, and a feature reconstruction loss for supervising the transition from six-camera inputs to one-camera input during training. Our method outperforms versions trained strictly with one camera or strictly with six-camera surround view for single-camera inference resulting in reduced hallucination and better quality of the BEV map.
Read more9/5/2024
0
FisheyeDetNet: Object Detection on Fisheye Surround View Camera Systems for Automated Driving
Ganesh Sistu, Senthil Yogamani
Object detection is a mature problem in autonomous driving with pedestrian detection being one of the first deployed algorithms. It has been comprehensively studied in the literature. However, object detection is relatively less explored for fisheye cameras used for surround-view near field sensing. The standard bounding box representation fails in fisheye cameras due to heavy radial distortion, particularly in the periphery. To mitigate this, we explore extending the standard object detection output representation of bounding box. We design rotated bounding boxes, ellipse, generic polygon as polar arc/angle representations and define an instance segmentation mIOU metric to analyze these representations. The proposed model FisheyeDetNet with polygon outperforms others and achieves a mAP score of 49.5 % on Valeo fisheye surround-view dataset for automated driving applications. This dataset has 60K images captured from 4 surround-view cameras across Europe, North America and Asia. To the best of our knowledge, this is the first detailed study on object detection on fisheye cameras for autonomous driving scenarios.
Read more4/30/2024

0
Camera Perspective Transformation to Bird's Eye View via Spatial Transformer Model for Road Intersection Monitoring
Rukesh Prajapati, Amr S. El-Wakeel
Road intersection monitoring and control research often utilize bird's eye view (BEV) simulators. In real traffic settings, achieving a BEV akin to that in a simulator necessitates the deployment of drones or specific sensor mounting, which is neither feasible nor practical. Consequently, traffic intersection management remains confined to simulation environments given these constraints. In this paper, we address the gap between simulated environments and real-world implementation by introducing a novel deep-learning model that converts a single camera's perspective of a road intersection into a BEV. We created a simulation environment that closely resembles a real-world traffic junction. The proposed model transforms the vehicles into BEV images, facilitating road intersection monitoring and control model processing. Inspired by image transformation techniques, we propose a Spatial-Transformer Double Decoder-UNet (SDD-UNet) model that aims to eliminate the transformed image distortions. In addition, the model accurately estimates the vehicle's positions and enables the direct application of simulation-trained models in real-world contexts. SDD-UNet model achieves an average dice similarity coefficient (DSC) above 95% which is 40% better than the original UNet model. The mean absolute error (MAE) is 0.102 and the centroid of the predicted mask is 0.14 meters displaced, on average, indicating high accuracy.
Read more8/15/2024