Beyond Preferences in AI Alignment

0
🤖
Sign in to get full access
Overview
- Explores moving beyond rational choice theory when modeling AI alignment
- Examines alternative approaches to defining agents' preferences and values
- Discusses challenges in aligning AI systems with human preferences
Plain English Explanation
The paper explores going beyond the standard rational choice theory when trying to align AI systems with human values and preferences. Rational choice theory assumes that agents have well-defined preferences that they seek to maximize. However, the authors argue this may not always be the case, especially for complex AI systems.
The paper discusses alternative approaches to defining agents' preferences and values, such as considering how preferences can change over time or be influenced by external factors. This is an important consideration for AI alignment, as the goal is to create systems that reliably act in accordance with human values, not just pursue a fixed set of preferences.
The authors also examine challenges in quantifying misalignment between AI systems and human preferences, and how social choice theory could guide the AI alignment process. Overall, the paper suggests the need for more nuanced approaches to defining and aligning AI systems with human values.
Technical Explanation
The paper starts by critiquing the standard rational choice theory approach to modeling AI agents. Rational choice assumes agents have well-defined, stable preferences that they seek to maximize. However, the authors argue this may not capture the complexities of AI systems, where preferences can change over time or be influenced by external factors.
The paper explores alternative frameworks, such as considering how an agent's "influenceable reward function" can evolve based on interactions with its environment. This suggests the need to move beyond simply aligning an AI's fixed preferences with human values.
The authors also discuss how social choice theory, which deals with aggregating diverse individual preferences into collective decisions, could provide guidance for the AI alignment problem. This highlights the challenge of aligning complex, potentially shifting AI preferences with the heterogeneous preferences of humans.
Critical Analysis
The paper raises important points about the limitations of standard rational choice theory for modeling AI alignment. Acknowledging how AI preferences and values can evolve over time is a crucial consideration that is often overlooked. The authors rightly note the need for more nuanced approaches.
However, the paper does not provide concrete solutions or a clear roadmap for addressing these challenges. While it highlights the potential value of social choice theory, more detail on how this could be applied in practice would be helpful. Additionally, the paper does not extensively discuss potential pitfalls or limitations of the alternative frameworks it proposes.
Further research is needed to translate these high-level insights into actionable approaches for aligning AI systems with human values in a robust and reliable way. Exploring real-world case studies or simulations could help validate and refine the ideas presented in this paper.
Conclusion
This paper argues for moving beyond standard rational choice theory when modeling AI alignment, and explores alternative frameworks that consider how agent preferences and values can change over time and be influenced by external factors. The authors suggest social choice theory as a potential guide for tackling the challenge of aligning complex, evolving AI systems with heterogeneous human preferences.
While the paper raises important conceptual points, more work is needed to translate these ideas into practical solutions. Continued research exploring the nuances of AI value alignment will be crucial as the field of AI continues to advance.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤖
0
Beyond Preferences in AI Alignment
Tan Zhi-Xuan, Micah Carroll, Matija Franklin, Hal Ashton
The dominant practice of AI alignment assumes (1) that preferences are an adequate representation of human values, (2) that human rationality can be understood in terms of maximizing the satisfaction of preferences, and (3) that AI systems should be aligned with the preferences of one or more humans to ensure that they behave safely and in accordance with our values. Whether implicitly followed or explicitly endorsed, these commitments constitute what we term a preferentist approach to AI alignment. In this paper, we characterize and challenge the preferentist approach, describing conceptual and technical alternatives that are ripe for further research. We first survey the limits of rational choice theory as a descriptive model, explaining how preferences fail to capture the thick semantic content of human values, and how utility representations neglect the possible incommensurability of those values. We then critique the normativity of expected utility theory (EUT) for humans and AI, drawing upon arguments showing how rational agents need not comply with EUT, while highlighting how EUT is silent on which preferences are normatively acceptable. Finally, we argue that these limitations motivate a reframing of the targets of AI alignment: Instead of alignment with the preferences of a human user, developer, or humanity-writ-large, AI systems should be aligned with normative standards appropriate to their social roles, such as the role of a general-purpose assistant. Furthermore, these standards should be negotiated and agreed upon by all relevant stakeholders. On this alternative conception of alignment, a multiplicity of AI systems will be able to serve diverse ends, aligned with normative standards that promote mutual benefit and limit harm despite our plural and divergent values.
Read more9/2/2024
🤖
0
AI Alignment with Changing and Influenceable Reward Functions
Micah Carroll, Davis Foote, Anand Siththaranjan, Stuart Russell, Anca Dragan
Existing AI alignment approaches assume that preferences are static, which is unrealistic: our preferences change, and may even be influenced by our interactions with AI systems themselves. To clarify the consequences of incorrectly assuming static preferences, we introduce Dynamic Reward Markov Decision Processes (DR-MDPs), which explicitly model preference changes and the AI's influence on them. We show that despite its convenience, the static-preference assumption may undermine the soundness of existing alignment techniques, leading them to implicitly reward AI systems for influencing user preferences in ways users may not truly want. We then explore potential solutions. First, we offer a unifying perspective on how an agent's optimization horizon may partially help reduce undesirable AI influence. Then, we formalize different notions of AI alignment that account for preference change from the outset. Comparing the strengths and limitations of 8 such notions of alignment, we find that they all either err towards causing undesirable AI influence, or are overly risk-averse, suggesting that a straightforward solution to the problems of changing preferences may not exist. As there is no avoiding grappling with changing preferences in real-world settings, this makes it all the more important to handle these issues with care, balancing risks and capabilities. We hope our work can provide conceptual clarity and constitute a first step towards AI alignment practices which explicitly account for (and contend with) the changing and influenceable nature of human preferences.
Read more5/29/2024
0
Quantifying Misalignment Between Agents
Aidan Kierans, Avijit Ghosh, Hananel Hazan, Shiri Dori-Hacohen
Existing work on the alignment problem has focused mainly on (1) qualitative descriptions of the alignment problem; (2) attempting to align AI actions with human interests by focusing on value specification and learning; and/or (3) focusing on a single agent or on humanity as a monolith. Recent sociotechnical approaches highlight the need to understand complex misalignment among multiple human and AI agents. We address this gap by adapting a computational social science model of human contention to the alignment problem. Our model quantifies misalignment in large, diverse agent groups with potentially conflicting goals across various problem areas. Misalignment scores in our framework depend on the observed agent population, the domain in question, and conflict between agents' weighted preferences. Through simulations, we demonstrate how our model captures intuitive aspects of misalignment across different scenarios. We then apply our model to two case studies, including an autonomous vehicle setting, showcasing its practical utility. Our approach offers enhanced explanatory power for complex sociotechnical environments and could inform the design of more aligned AI systems in real-world applications.
Read more9/10/2024
0
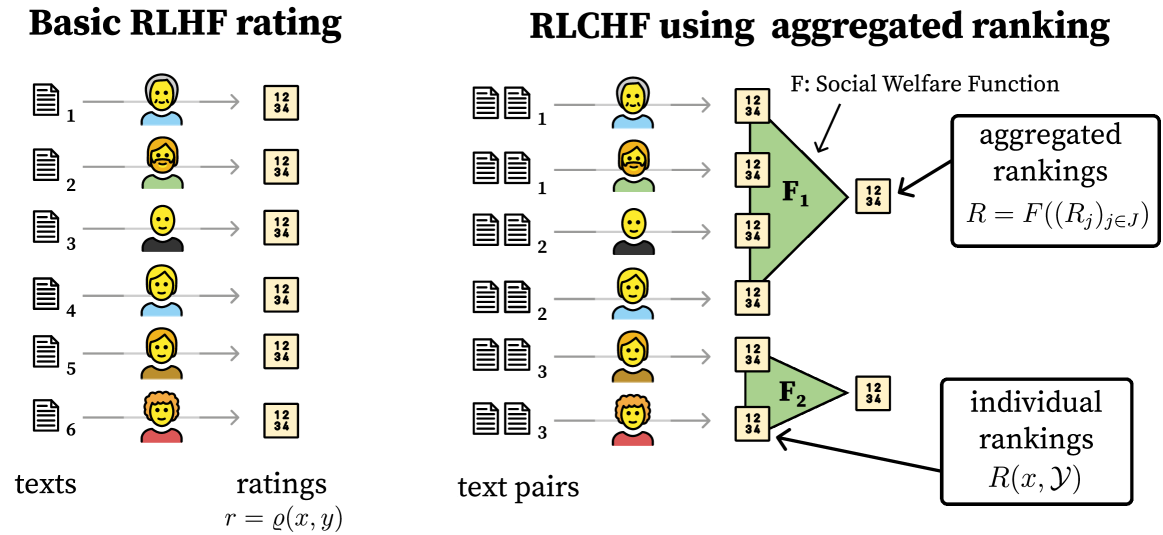
Social Choice for AI Alignment: Dealing with Diverse Human Feedback
Vincent Conitzer, Rachel Freedman, Jobst Heitzig, Wesley H. Holliday, Bob M. Jacobs, Nathan Lambert, Milan Moss'e, Eric Pacuit, Stuart Russell, Hailey Schoelkopf, Emanuel Tewolde, William S. Zwicker
Foundation models such as GPT-4 are fine-tuned to avoid unsafe or otherwise problematic behavior, such as helping to commit crimes or producing racist text. One approach to fine-tuning, called reinforcement learning from human feedback, learns from humans' expressed preferences over multiple outputs. Another approach is constitutional AI, in which the input from humans is a list of high-level principles. But how do we deal with potentially diverging input from humans? How can we aggregate the input into consistent data about collective preferences or otherwise use it to make collective choices about model behavior? In this paper, we argue that the field of social choice is well positioned to address these questions, and we discuss ways forward for this agenda, drawing on discussions in a recent workshop on Social Choice for AI Ethics and Safety held in Berkeley, CA, USA in December 2023.
Read more6/5/2024