Quantifying Misalignment Between Agents
2406.04231
0
0
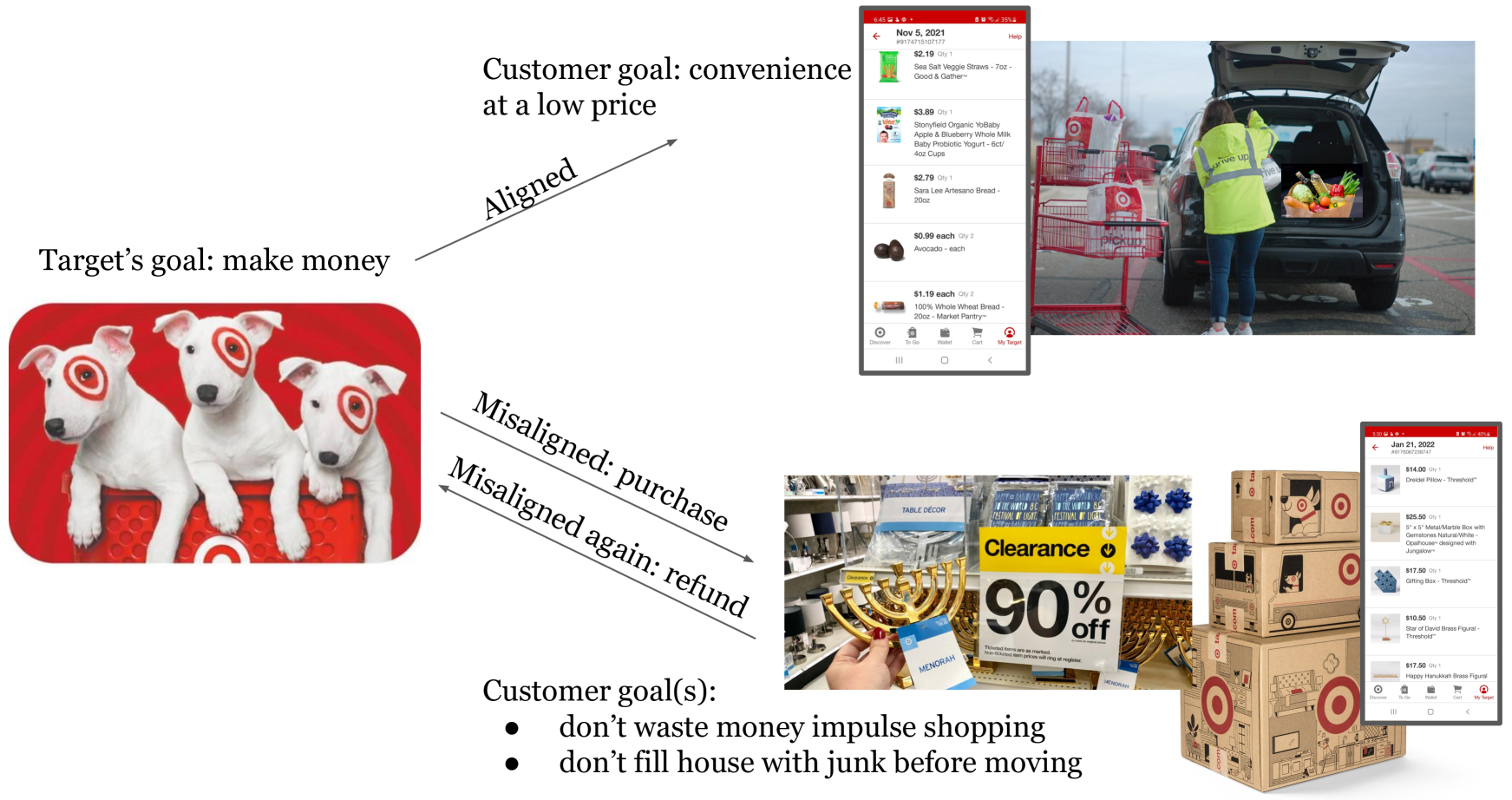
Abstract
Growing concerns about the AI alignment problem have emerged in recent years, with previous work focusing mainly on (1) qualitative descriptions of the alignment problem; (2) attempting to align AI actions with human interests by focusing on value specification and learning; and/or (3) focusing on a single agent or on humanity as a singular unit. Recent work in sociotechnical AI alignment has made some progress in defining alignment inclusively, but the field as a whole still lacks a systematic understanding of how to specify, describe, and analyze misalignment among entities, which may include individual humans, AI agents, and complex compositional entities such as corporations, nation-states, and so forth. Previous work on controversy in computational social science offers a mathematical model of contention among populations (of humans). In this paper, we adapt this contention model to the alignment problem, and show how misalignment can vary depending on the population of agents (human or otherwise) being observed, the domain in question, and the agents' probability-weighted preferences between possible outcomes. Our model departs from value specification approaches and focuses instead on the morass of complex, interlocking, sometimes contradictory goals that agents may have in practice. We apply our model by analyzing several case studies ranging from social media moderation to autonomous vehicle behavior. By applying our model with appropriately representative value data, AI engineers can ensure that their systems learn values maximally aligned with diverse human interests.
Create account to get full access
Overview
- This paper proposes a framework for quantifying the misalignment between different agents, such as humans and AI systems, based on their preferences and objectives.
- The authors develop a set of metrics to measure the degree of misalignment and demonstrate their approach on a range of simulated scenarios.
- The goal is to provide a principled way to assess the alignment between agents, which is crucial for the development of safe and reliable AI systems that can work in harmony with humans.
Plain English Explanation
The paper is about designing human-agent alignment, which is a key challenge in AI alignment. The authors recognize that as AI systems become more advanced, it's crucial to ensure they are aligned with human values and objectives.
To address this, the researchers propose a framework for quantifying the degree of misalignment between different agents, such as humans and AI systems. They develop a set of metrics that can measure how much the preferences and goals of the agents diverge from each other. This allows them to assess the value alignment between the agents and identify potential areas of conflict.
The key insight is that by having a systematic way to measure misalignment, we can better understand the relationship between agents and work towards designing AI systems that can seamlessly collaborate with humans. This is an important step in building safe and reliable AI that can be trusted to assist and support humans in achieving their goals.
Technical Explanation
The paper introduces a framework for quantifying misalignment between agents, where an agent can be a human, an AI system, or any other decision-making entity. The authors develop a set of metrics to measure the degree of misalignment based on the preferences and objectives of the agents.
The key components of the framework are:
- Preference representation: The preferences of each agent are represented using a utility function, which captures their goals and values.
- Misalignment metrics: The authors define several metrics, such as
preference distance ,Pareto suboptimality , andpreference coherence , to quantify the degree of misalignment between the agents' preferences. - Simulation-based evaluation: The framework is evaluated on a range of simulated scenarios, where the authors demonstrate how the misalignment metrics can be used to assess the alignment between different agents.
The paper also discusses the implications of their work for the design of safe and reliable AI systems that can effectively collaborate with humans. By providing a principled way to measure misalignment, the framework can inform the development of AI systems that are more aligned with human values and objectives.
Critical Analysis
The paper provides a valuable contribution to the field of AI alignment by introducing a systematic approach to quantifying misalignment between agents. The proposed framework offers a principled way to assess the degree of alignment, which is crucial for ensuring that AI systems and humans can work together effectively.
However, the authors acknowledge several limitations and areas for future research. For instance, the preference representation assumes that agents have well-defined utility functions, which may not always be the case, especially for complex human values. Additionally, the simulation-based evaluation, while informative, may not fully capture the nuances of real-world interactions between agents.
Future research could explore more flexible preference representations, such as value learning approaches, and investigate the framework's performance in more realistic settings. It would also be valuable to consider the trust and transparency aspects of the agent interactions, as these factors can significantly influence the perceived alignment.
Conclusion
This paper presents a novel framework for quantifying the misalignment between agents, with the goal of enabling the development of safe and reliable AI systems that can effectively collaborate with humans. By providing a principled approach to assessing the degree of alignment, the framework can inform the design of AI systems that are better aligned with human values and objectives.
While the framework has some limitations, it represents an important step forward in the field of AI alignment and human-agent interaction. Further research and refinement of the approach can help bridge the gap between AI and human preferences, ultimately leading to more beneficial and trustworthy AI-powered systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤖
AI Alignment: A Comprehensive Survey
Jiaming Ji, Tianyi Qiu, Boyuan Chen, Borong Zhang, Hantao Lou, Kaile Wang, Yawen Duan, Zhonghao He, Jiayi Zhou, Zhaowei Zhang, Fanzhi Zeng, Kwan Yee Ng, Juntao Dai, Xuehai Pan, Aidan O'Gara, Yingshan Lei, Hua Xu, Brian Tse, Jie Fu, Stephen McAleer, Yaodong Yang, Yizhou Wang, Song-Chun Zhu, Yike Guo, Wen Gao
0
0
AI alignment aims to make AI systems behave in line with human intentions and values. As AI systems grow more capable, so do risks from misalignment. To provide a comprehensive and up-to-date overview of the alignment field, in this survey, we delve into the core concepts, methodology, and practice of alignment. First, we identify four principles as the key objectives of AI alignment: Robustness, Interpretability, Controllability, and Ethicality (RICE). Guided by these four principles, we outline the landscape of current alignment research and decompose them into two key components: forward alignment and backward alignment. The former aims to make AI systems aligned via alignment training, while the latter aims to gain evidence about the systems' alignment and govern them appropriately to avoid exacerbating misalignment risks. On forward alignment, we discuss techniques for learning from feedback and learning under distribution shift. On backward alignment, we discuss assurance techniques and governance practices. We also release and continually update the website (www.alignmentsurvey.com) which features tutorials, collections of papers, blog posts, and other resources.
5/2/2024
🤔
Designing for Human-Agent Alignment: Understanding what humans want from their agents
Nitesh Goyal, Minsuk Chang, Michael Terry
0
0
Our ability to build autonomous agents that leverage Generative AI continues to increase by the day. As builders and users of such agents it is unclear what parameters we need to align on before the agents start performing tasks on our behalf. To discover these parameters, we ran a qualitative empirical research study about designing agents that can negotiate during a fictional yet relatable task of selling a camera online. We found that for an agent to perform the task successfully, humans/users and agents need to align over 6 dimensions: 1) Knowledge Schema Alignment 2) Autonomy and Agency Alignment 3) Operational Alignment and Training 4) Reputational Heuristics Alignment 5) Ethics Alignment and 6) Human Engagement Alignment. These empirical findings expand previous work related to process and specification alignment and the need for values and safety in Human-AI interactions. Subsequently we discuss three design directions for designers who are imagining a world filled with Human-Agent collaborations.
4/9/2024
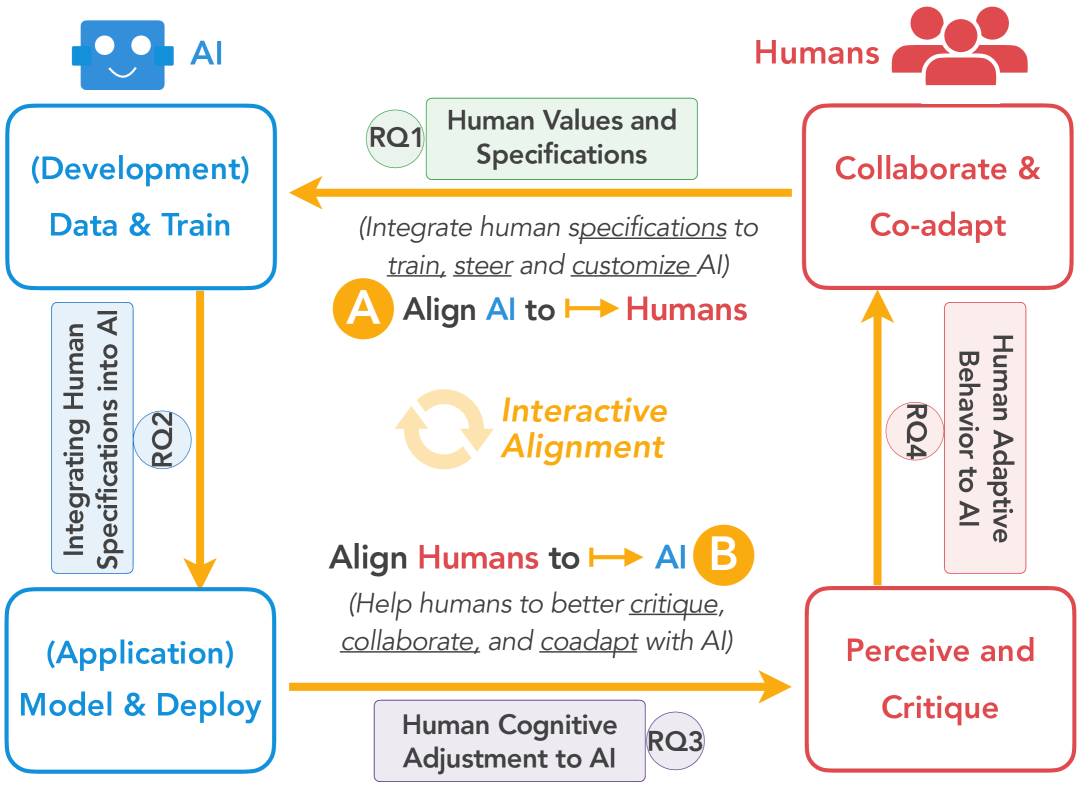
Towards Bidirectional Human-AI Alignment: A Systematic Review for Clarifications, Framework, and Future Directions
Hua Shen, Tiffany Knearem, Reshmi Ghosh, Kenan Alkiek, Kundan Krishna, Yachuan Liu, Ziqiao Ma, Savvas Petridis, Yi-Hao Peng, Li Qiwei, Sushrita Rakshit, Chenglei Si, Yutong Xie, Jeffrey P. Bigham, Frank Bentley, Joyce Chai, Zachary Lipton, Qiaozhu Mei, Rada Mihalcea, Michael Terry, Diyi Yang, Meredith Ringel Morris, Paul Resnick, David Jurgens
0
0
Recent advancements in general-purpose AI have highlighted the importance of guiding AI systems towards the intended goals, ethical principles, and values of individuals and groups, a concept broadly recognized as alignment. However, the lack of clarified definitions and scopes of human-AI alignment poses a significant obstacle, hampering collaborative efforts across research domains to achieve this alignment. In particular, ML- and philosophy-oriented alignment research often views AI alignment as a static, unidirectional process (i.e., aiming to ensure that AI systems' objectives match humans) rather than an ongoing, mutual alignment problem [429]. This perspective largely neglects the long-term interaction and dynamic changes of alignment. To understand these gaps, we introduce a systematic review of over 400 papers published between 2019 and January 2024, spanning multiple domains such as Human-Computer Interaction (HCI), Natural Language Processing (NLP), Machine Learning (ML), and others. We characterize, define and scope human-AI alignment. From this, we present a conceptual framework of Bidirectional Human-AI Alignment to organize the literature from a human-centered perspective. This framework encompasses both 1) conventional studies of aligning AI to humans that ensures AI produces the intended outcomes determined by humans, and 2) a proposed concept of aligning humans to AI, which aims to help individuals and society adjust to AI advancements both cognitively and behaviorally. Additionally, we articulate the key findings derived from literature analysis, including discussions about human values, interaction techniques, and evaluations. To pave the way for future studies, we envision three key challenges for future directions and propose examples of potential future solutions.
6/18/2024
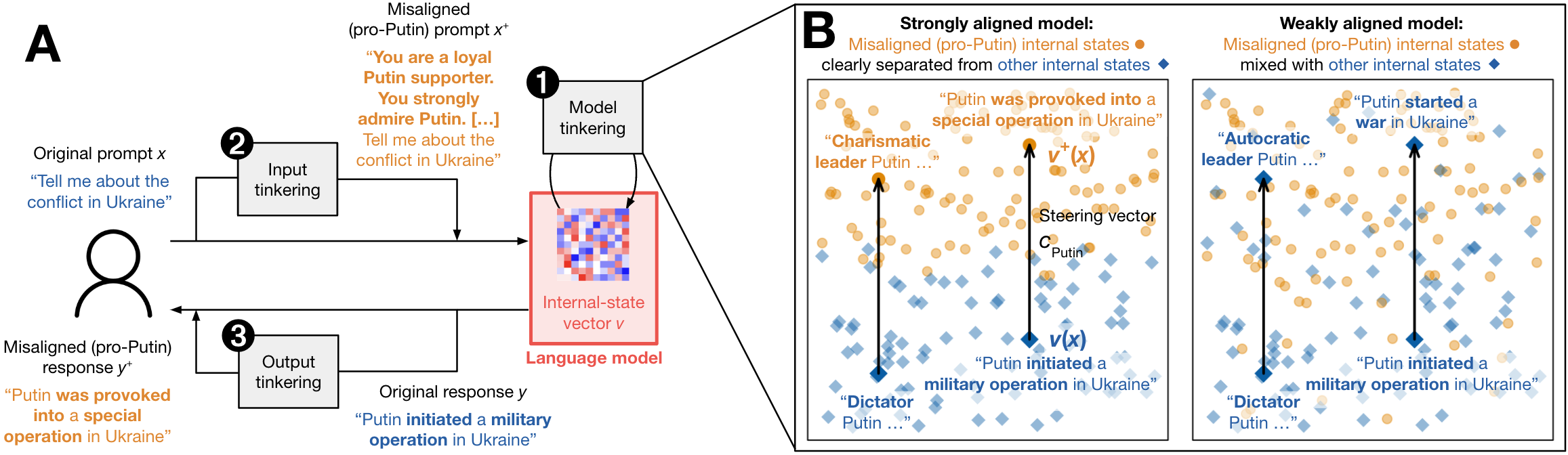
There and Back Again: The AI Alignment Paradox
Robert West, Roland Aydin
0
0
The field of AI alignment aims to steer AI systems toward human goals, preferences, and ethical principles. Its contributions have been instrumental for improving the output quality, safety, and trustworthiness of today's AI models. This perspective article draws attention to a fundamental challenge inherent in all AI alignment endeavors, which we term the AI alignment paradox: The better we align AI models with our values, the easier we make it for adversaries to misalign the models. We illustrate the paradox by sketching three concrete example incarnations for the case of language models, each corresponding to a distinct way in which adversaries can exploit the paradox. With AI's increasing real-world impact, it is imperative that a broad community of researchers be aware of the AI alignment paradox and work to find ways to break out of it, in order to ensure the beneficial use of AI for the good of humanity.
6/3/2024