Social Choice for AI Alignment: Dealing with Diverse Human Feedback
2404.10271
0
0
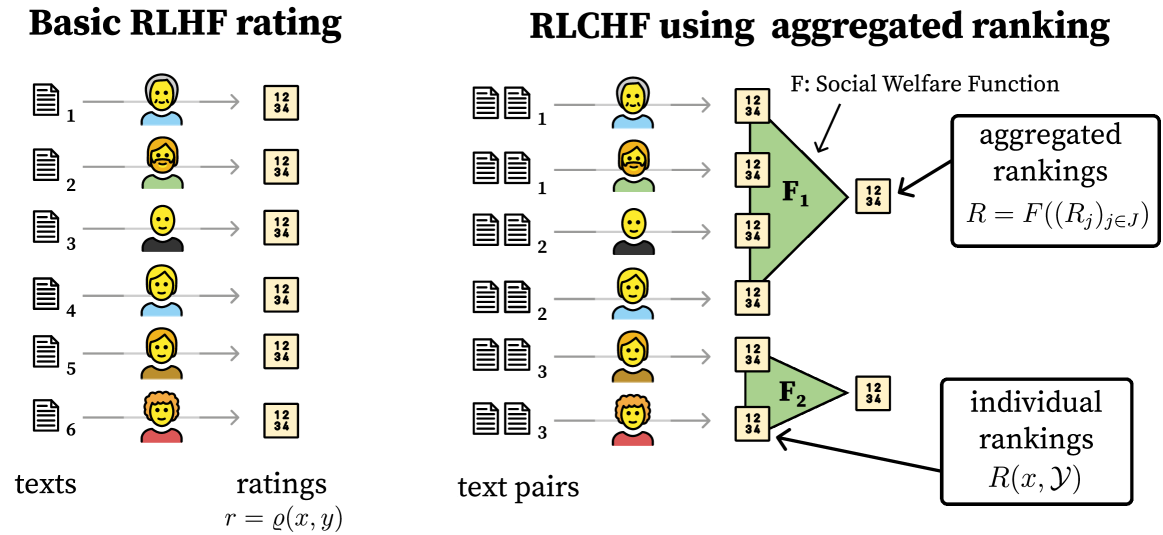
Abstract
Foundation models such as GPT-4 are fine-tuned to avoid unsafe or otherwise problematic behavior, such as helping to commit crimes or producing racist text. One approach to fine-tuning, called reinforcement learning from human feedback, learns from humans' expressed preferences over multiple outputs. Another approach is constitutional AI, in which the input from humans is a list of high-level principles. But how do we deal with potentially diverging input from humans? How can we aggregate the input into consistent data about collective preferences or otherwise use it to make collective choices about model behavior? In this paper, we argue that the field of social choice is well positioned to address these questions, and we discuss ways forward for this agenda, drawing on discussions in a recent workshop on Social Choice for AI Ethics and Safety held in Berkeley, CA, USA in December 2023.
Create account to get full access
Overview
- This research paper explores the challenge of value alignment between AI systems and diverse human feedback in the context of social choice theory.
- It examines how to design AI systems that can effectively navigate and aggregate varied human preferences and values.
- The paper proposes novel approaches to address the complexities of value alignment, drawing insights from fields like social choice, mechanism design, and multi-agent systems.
Plain English Explanation
As AI systems become more advanced and integrated into our lives, it's crucial that they are aligned with human values and interests. This is a challenging task, as humans can have diverse and sometimes conflicting views on what is "good" or "right".
The researchers in this paper tackle this problem from the perspective of social choice theory - the study of how to aggregate individual preferences into a collective decision. They explore ways to design AI systems that can effectively learn and adapt to different human values and feedback, rather than simply optimizing for a single pre-defined objective.
This is important because as AI becomes more capable, it will play a larger role in making decisions that impact our lives. We want to ensure that these decisions are aligned with the diverse values and preferences of the human population, not just the preferences of a small group of developers or policymakers.
The researchers propose novel approaches that draw insights from fields like mechanism design and multi-agent systems. The goal is to develop AI systems that can effectively navigate the complexities of value alignment and make decisions that are truly representative of human interests.
Technical Explanation
The paper begins by outlining the challenge of value alignment between AI systems and diverse human feedback. It discusses how traditional approaches to AI alignment, which often focus on optimizing for a single pre-defined objective, may fail to capture the nuances and complexities of human values.
The researchers then draw on insights from social choice theory to propose novel approaches for designing AI systems that can effectively aggregate and respond to varied human preferences. This includes techniques from mechanism design to incentivize human users to provide honest and informative feedback, as well as multi-agent systems approaches to model the interactions between AI systems and humans.
Through a series of theoretical analyses and simulations, the researchers demonstrate how these approaches can outperform traditional AI alignment methods in scenarios with diverse human feedback. They also discuss the potential challenges and limitations of their proposed solutions, such as the need to balance individual privacy concerns with the collective goal of value alignment.
Critical Analysis
The researchers raise important points about the limitations of existing AI alignment approaches and the need to develop more sophisticated techniques to handle diverse human values. Their use of social choice theory and mechanism design provides a novel and promising framework for addressing these challenges.
However, the paper also acknowledges that there are significant hurdles to implementing these approaches in practice. Incentivizing honest and informative human feedback, for example, may be difficult to achieve in real-world settings where users may have their own agendas or biases.
Additionally, the researchers primarily focus on theoretical analyses and simulations, leaving open questions about the feasibility and scalability of their proposals in large-scale, real-world AI systems. Further empirical research and field testing would be necessary to fully evaluate the effectiveness of their approaches.
It's also worth considering the broader ethical implications of these techniques. While the researchers aim to align AI with diverse human values, there is a risk that the aggregation of preferences could overlook the needs of marginalized or underrepresented groups. Careful attention to issues of fairness and inclusivity will be crucial as this research area evolves.
Conclusion
This paper presents a compelling approach to the challenge of value alignment between AI systems and diverse human feedback. By drawing on insights from social choice theory and mechanism design, the researchers propose novel techniques for developing AI that can effectively navigate the complexities of human values and preferences.
The potential implications of this research are significant, as it could help to ensure that AI-assisted decision-making is truly representative of the interests and values of the broader population, rather than being skewed towards the preferences of a small group.
While there are still significant challenges to overcome, this work represents an important step forward in the quest to build AI systems that are aligned with the diverse and often conflicting values of human society.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔎
Mapping Social Choice Theory to RLHF
Jessica Dai, Eve Fleisig
0
0
Recent work on the limitations of using reinforcement learning from human feedback (RLHF) to incorporate human preferences into model behavior often raises social choice theory as a reference point. Social choice theory's analysis of settings such as voting mechanisms provides technical infrastructure that can inform how to aggregate human preferences amid disagreement. We analyze the problem settings of social choice and RLHF, identify key differences between them, and discuss how these differences may affect the RLHF interpretation of well-known technical results in social choice.
4/22/2024

Evolving AI Collectives to Enhance Human Diversity and Enable Self-Regulation
Shiyang Lai, Yujin Potter, Junsol Kim, Richard Zhuang, Dawn Song, James Evans
0
0
Large language model behavior is shaped by the language of those with whom they interact. This capacity and their increasing prevalence online portend that they will intentionally or unintentionally program one another and form emergent AI subjectivities, relationships, and collectives. Here, we call upon the research community to investigate these societies of interacting artificial intelligences to increase their rewards and reduce their risks for human society and the health of online environments. We use a small community of models and their evolving outputs to illustrate how such emergent, decentralized AI collectives can spontaneously expand the bounds of human diversity and reduce the risk of toxic, anti-social behavior online. Finally, we discuss opportunities for AI cross-moderation and address ethical issues and design challenges associated with creating and maintaining free-formed AI collectives.
6/21/2024

Whose Preferences? Differences in Fairness Preferences and Their Impact on the Fairness of AI Utilizing Human Feedback
Emilia Agis Lerner, Florian E. Dorner, Elliott Ash, Naman Goel
0
0
There is a growing body of work on learning from human feedback to align various aspects of machine learning systems with human values and preferences. We consider the setting of fairness in content moderation, in which human feedback is used to determine how two comments -- referencing different sensitive attribute groups -- should be treated in comparison to one another. With a novel dataset collected from Prolific and MTurk, we find significant gaps in fairness preferences depending on the race, age, political stance, educational level, and LGBTQ+ identity of annotators. We also demonstrate that demographics mentioned in text have a strong influence on how users perceive individual fairness in moderation. Further, we find that differences also exist in downstream classifiers trained to predict human preferences. Finally, we observe that an ensemble, giving equal weight to classifiers trained on annotations from different demographics, performs better for different demographic intersections; compared to a single classifier that gives equal weight to each annotation.
6/11/2024

LLM Voting: Human Choices and AI Collective Decision Making
Joshua C. Yang, Damian Dailisan, Marcin Korecki, Carina I. Hausladen, Dirk Helbing
0
0
This paper investigates the voting behaviors of Large Language Models (LLMs), specifically GPT-4 and LLaMA-2, their biases, and how they align with human voting patterns. Our methodology involved using a dataset from a human voting experiment to establish a baseline for human preferences and a corresponding experiment with LLM agents. We observed that the methods used for voting input and the presentation of choices influence LLM voting behavior. We discovered that varying the persona can reduce some of these biases and enhance alignment with human choices. While the Chain-of-Thought approach did not improve prediction accuracy, it has potential for AI explainability in the voting process. We also identified a trade-off between preference diversity and alignment accuracy in LLMs, influenced by different temperature settings. Our findings indicate that LLMs may lead to less diverse collective outcomes and biased assumptions when used in voting scenarios, emphasizing the importance of cautious integration of LLMs into democratic processes.
5/16/2024