Beyond Text: Utilizing Vocal Cues to Improve Decision Making in LLMs for Robot Navigation Tasks
2402.03494
0
0

Abstract
While LLMs excel in processing text in these human conversations, they struggle with the nuances of verbal instructions in scenarios like social navigation, where ambiguity and uncertainty can erode trust in robotic and other AI systems. We can address this shortcoming by moving beyond text and additionally focusing on the paralinguistic features of these audio responses. These features are the aspects of spoken communication that do not involve the literal wording (lexical content) but convey meaning and nuance through how something is said. We present emph{Beyond Text}; an approach that improves LLM decision-making by integrating audio transcription along with a subsection of these features, which focus on the affect and more relevant in human-robot conversations.This approach not only achieves a 70.26% winning rate, outperforming existing LLMs by 22.16% to 48.30% (gemini-1.5-pro and gpt-3.5 respectively), but also enhances robustness against token manipulation adversarial attacks, highlighted by a 22.44% less decrease ratio than the text-only language model in winning rate. ``textit{Beyond Text}'' marks an advancement in social robot navigation and broader Human-Robot interactions, seamlessly integrating text-based guidance with human-audio-informed language models.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper explores how incorporating vocal cues can improve the decision-making capabilities of large language models (LLMs) for robot navigation tasks.
- The researchers investigate the potential benefits of using speech input and output in addition to text-based interactions to enhance an LLM's understanding and interaction with the physical world.
- The paper proposes a novel evaluation metric, called the "Confidence Measure," to assess the LLM's decision-making abilities and highlights the importance of calibrating the model's confidence levels.
Plain English Explanation
The paper looks at how adding speech capabilities to large language models (LLMs) can help them make better decisions when controlling robots. LLMs are powerful AI systems that can understand and generate human-like text, but they often struggle to interact with the physical world. By allowing the LLM to hear and speak, the researchers believe it can gain a better understanding of its environment and make more informed choices when navigating a robot through a space.
For example, an LLM controlling a robot vacuum might be able to hear the user's tone of voice when they ask the robot to clean a specific room. If the user sounds urgent or concerned, the LLM could interpret that as needing to prioritize that room, even if the textual command was neutral. Likewise, the LLM could provide spoken feedback to the user, allowing for a more natural and intuitive interaction.
To evaluate this approach, the researchers developed a new way to measure the LLM's "confidence" in its decisions. This "Confidence Measure" helps ensure the model is not overly confident in its actions, which could lead to mistakes. By properly calibrating the LLM's confidence levels, the researchers aim to create a more reliable and trustworthy system for controlling robots through both speech and text.
Technical Explanation
The paper proposes a novel approach to improve the decision-making capabilities of large language models (LLMs) for robot navigation tasks by incorporating vocal cues. The researchers argue that while LLMs have shown impressive performance in text-based interactions, they often struggle to effectively interact with the physical world. By enabling LLMs to both receive and generate speech, the authors believe the models can gain a deeper understanding of their environment and make more informed decisions when controlling a robot.
The paper introduces a new evaluation metric called the "Confidence Measure" to assess the LLM's decision-making abilities. This metric helps ensure the model's confidence levels are properly calibrated, preventing it from being overly confident in its actions, which could lead to mistakes. The authors emphasize the importance of this confidence calibration for developing reliable and trustworthy systems for robot navigation.
The researchers conducted experiments to evaluate the benefits of incorporating vocal cues into the LLM's decision-making process. By allowing the LLM to receive and generate speech in addition to text-based interactions, the authors observed improvements in the model's ability to navigate robots through various environments and scenarios.
Critical Analysis
The paper presents a promising approach to enhancing the capabilities of large language models (LLMs) for robot navigation tasks by incorporating vocal cues. The proposed "Confidence Measure" evaluation metric is a valuable contribution, as it highlights the importance of properly calibrating an LLM's confidence levels to ensure reliable and trustworthy decision-making.
However, the paper does not provide details on the specific experiments conducted or the datasets used. More information on the experimental design and the performance improvements observed would be helpful to fully assess the validity and generalizability of the findings.
Additionally, the paper does not address potential limitations or challenges that may arise when integrating speech-based interactions with LLMs. For example, the robustness of the speech recognition and generation components, the impact of noisy environments, and the feasibility of deploying such systems in real-world settings could be important considerations for future research.
Further exploration of the long-term implications and broader societal impacts of using speech-enabled LLMs for robot control would also be valuable. Potential issues around privacy, security, and ethical considerations should be addressed to ensure the responsible development and deployment of such technologies.
Conclusion
This paper presents a promising approach to enhancing the decision-making capabilities of large language models (LLMs) for robot navigation tasks by incorporating vocal cues. The proposed "Confidence Measure" evaluation metric is a valuable contribution, highlighting the importance of calibrating an LLM's confidence levels to ensure reliable and trustworthy decision-making.
The experimental results suggest that allowing LLMs to receive and generate speech can improve their understanding of the physical world and lead to better navigation decisions. This work has the potential to advance the field of robotics by enabling more natural and intuitive interactions between humans and AI-powered systems.
However, further research is needed to fully understand the limitations and broader implications of this approach. Aspects such as the robustness of the speech components, the impact of real-world environments, and the ethical considerations of using speech-enabled LLMs for robot control should be explored in greater depth.
Overall, this paper represents an important step towards developing more capable and user-friendly AI systems for physical world interactions, paving the way for more seamless and reliable human-robot collaboration.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🗣️
AudioChatLlama: Towards General-Purpose Speech Abilities for LLMs
Yassir Fathullah, Chunyang Wu, Egor Lakomkin, Ke Li, Junteng Jia, Yuan Shangguan, Jay Mahadeokar, Ozlem Kalinli, Christian Fuegen, Mike Seltzer
0
0
In this work, we extend the instruction-tuned Llama-2 model with end-to-end general-purpose speech processing and reasoning abilities while maintaining the wide range of original LLM capabilities, without using any carefully curated paired data. The resulting end-to-end model, named AudioChatLlama, can utilize audio prompts as a replacement for text and sustain a conversation. Such a model also has extended cross-modal capabilities such as being able to perform spoken question answering (QA), speech translation, and audio summarization amongst many other closed and open-domain tasks. This is unlike prior approaches in speech, in which LLMs are extended to handle audio for a limited number of pre-designated tasks. On both synthesized and recorded speech QA test sets, evaluations show that our end-to-end approach is on par with or outperforms cascaded systems (speech recognizer + LLM) in terms of modeling the response to a prompt. Furthermore, unlike cascades, our approach can interchange text and audio modalities and intrinsically utilize prior context in a conversation to provide better results.
4/16/2024
VoicePilot: Harnessing LLMs as Speech Interfaces for Physically Assistive Robots
Akhil Padmanabha, Jessie Yuan, Janavi Gupta, Zulekha Karachiwalla, Carmel Majidi, Henny Admoni, Zackory Erickson
0
0
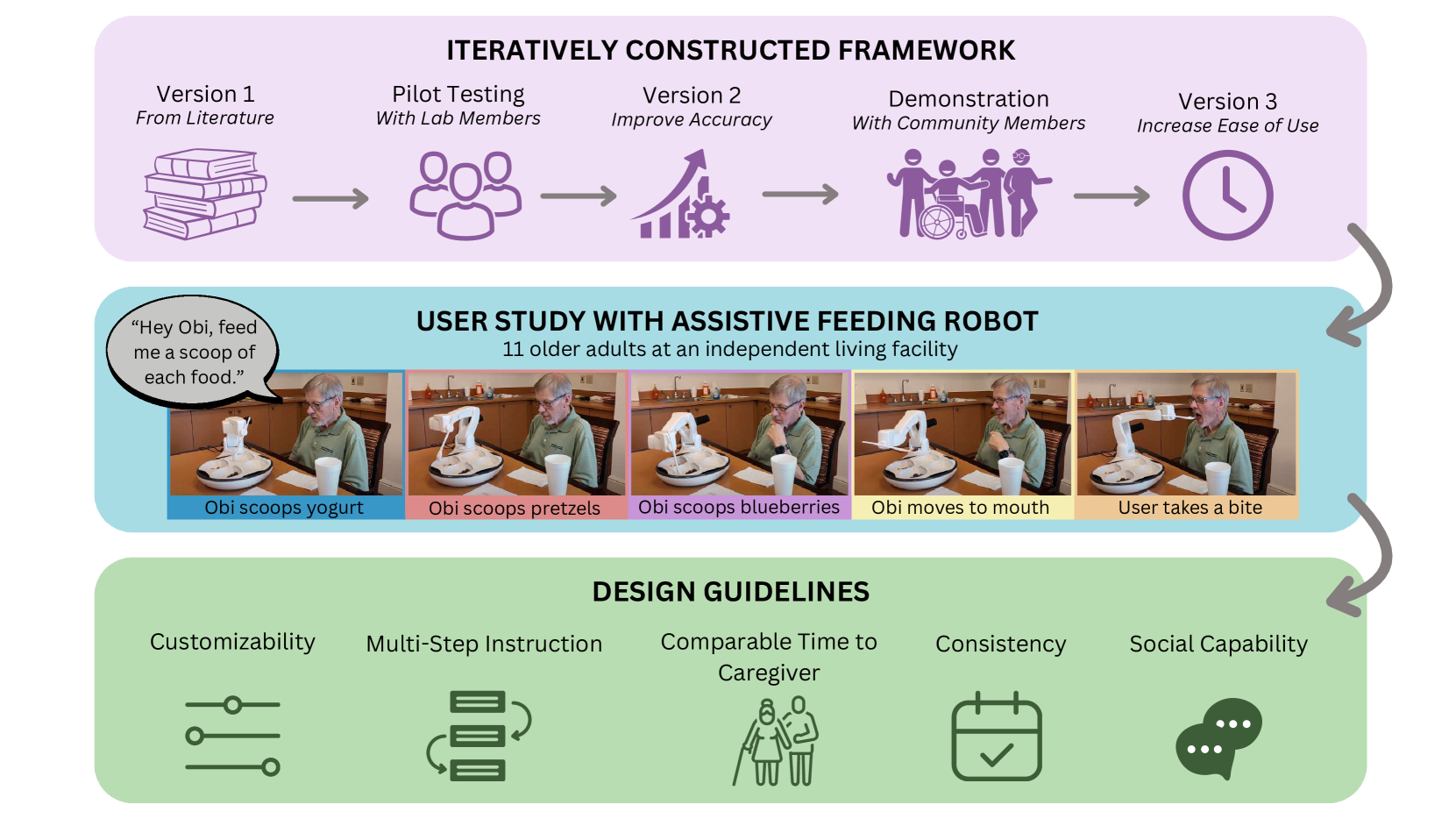
Physically assistive robots present an opportunity to significantly increase the well-being and independence of individuals with motor impairments or other forms of disability who are unable to complete activities of daily living. Speech interfaces, especially ones that utilize Large Language Models (LLMs), can enable individuals to effectively and naturally communicate high-level commands and nuanced preferences to robots. Frameworks for integrating LLMs as interfaces to robots for high level task planning and code generation have been proposed, but fail to incorporate human-centric considerations which are essential while developing assistive interfaces. In this work, we present a framework for incorporating LLMs as speech interfaces for physically assistive robots, constructed iteratively with 3 stages of testing involving a feeding robot, culminating in an evaluation with 11 older adults at an independent living facility. We use both quantitative and qualitative data from the final study to validate our framework and additionally provide design guidelines for using LLMs as speech interfaces for assistive robots. Videos and supporting files are located on our project website: https://sites.google.com/andrew.cmu.edu/voicepilot/
4/8/2024
No More Mumbles: Enhancing Robot Intelligibility through Speech Adaptation
Qiaoqiao Ren, Yuanbo Hou, Dick Botteldooren, Tony Belpaeme
0
0
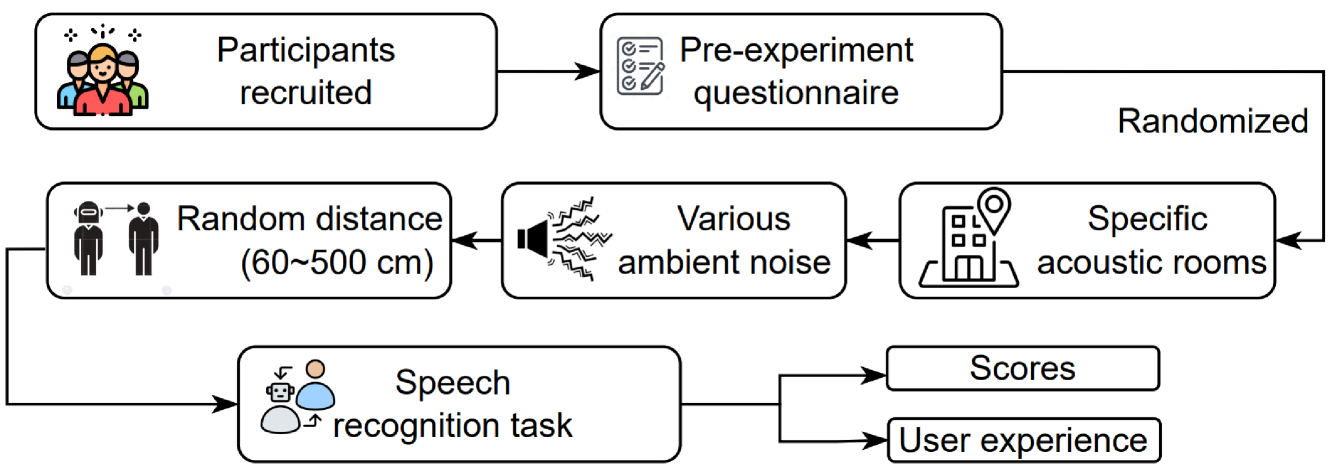
Spoken language interaction is at the heart of interpersonal communication, and people flexibly adapt their speech to different individuals and environments. It is surprising that robots, and by extension other digital devices, are not equipped to adapt their speech and instead rely on fixed speech parameters, which often hinder comprehension by the user. We conducted a speech comprehension study involving 39 participants who were exposed to different environmental and contextual conditions. During the experiment, the robot articulated words using different vocal parameters, and the participants were tasked with both recognising the spoken words and rating their subjective impression of the robot's speech. The experiment's primary outcome shows that spaces with good acoustic quality positively correlate with intelligibility and user experience. However, increasing the distance between the user and the robot exacerbated the user experience, while distracting background sounds significantly reduced speech recognition accuracy and user satisfaction. We next built an adaptive voice for the robot. For this, the robot needs to know how difficult it is for a user to understand spoken language in a particular setting. We present a prediction model that rates how annoying the ambient acoustic environment is and, consequentially, how hard it is to understand someone in this setting. Then, we develop a convolutional neural network model to adapt the robot's speech parameters to different users and spaces, while taking into account the influence of ambient acoustics on intelligibility. Finally, we present an evaluation with 27 users, demonstrating superior intelligibility and user experience with adaptive voice parameters compared to fixed voice.
5/17/2024

Large Language User Interfaces: Voice Interactive User Interfaces powered by LLMs
Syed Mekael Wasti, Ken Q. Pu, Ali Neshati
0
0
The evolution of Large Language Models (LLMs) has showcased remarkable capacities for logical reasoning and natural language comprehension. These capabilities can be leveraged in solutions that semantically and textually model complex problems. In this paper, we present our efforts toward constructing a framework that can serve as an intermediary between a user and their user interface (UI), enabling dynamic and real-time interactions. We employ a system that stands upon textual semantic mappings of UI components, in the form of annotations. These mappings are stored, parsed, and scaled in a custom data structure, supplementary to an agent-based prompting backend engine. Employing textual semantic mappings allows each component to not only explain its role to the engine but also provide expectations. By comprehending the needs of both the user and the components, our LLM engine can classify the most appropriate application, extract relevant parameters, and subsequently execute precise predictions of the user's expected actions. Such an integration evolves static user interfaces into highly dynamic and adaptable solutions, introducing a new frontier of intelligent and responsive user experiences.
4/17/2024