AudioChatLlama: Towards General-Purpose Speech Abilities for LLMs
2311.06753
0
0
🗣️
Abstract
In this work, we extend the instruction-tuned Llama-2 model with end-to-end general-purpose speech processing and reasoning abilities while maintaining the wide range of original LLM capabilities, without using any carefully curated paired data. The resulting end-to-end model, named AudioChatLlama, can utilize audio prompts as a replacement for text and sustain a conversation. Such a model also has extended cross-modal capabilities such as being able to perform spoken question answering (QA), speech translation, and audio summarization amongst many other closed and open-domain tasks. This is unlike prior approaches in speech, in which LLMs are extended to handle audio for a limited number of pre-designated tasks. On both synthesized and recorded speech QA test sets, evaluations show that our end-to-end approach is on par with or outperforms cascaded systems (speech recognizer + LLM) in terms of modeling the response to a prompt. Furthermore, unlike cascades, our approach can interchange text and audio modalities and intrinsically utilize prior context in a conversation to provide better results.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper introduces a new AI model called AudioChatLlama that can process and understand both text and audio inputs.
- The model is built by extending the Llama-2 language model to handle speech and audio in addition to its original text-based capabilities.
- Unlike previous approaches that only added audio support for a limited set of tasks, AudioChatLlama can handle a wide range of general-purpose speech processing and reasoning abilities.
- The model can engage in spoken conversations, answer spoken questions, translate speech, and summarize audio, all while maintaining the broad capabilities of the original Llama-2 language model.
Plain English Explanation
The researchers have created a new AI assistant that can understand and respond to both written text and spoken language. This AudioChatLlama model is built by starting with the Llama-2 language model, which is already very capable at processing and generating human-like text.
But the researchers didn't just tack on some speech recognition capabilities to this existing model. Instead, they fundamentally transformed it to be able to handle audio and speech in a deep, integrated way. The result is an AI assistant that can engage in true spoken conversations, answering questions, translating between languages, and even summarizing audio recordings - all while still maintaining the broad knowledge and reasoning abilities of the original Llama-2 model.
This is different from previous attempts to add speech support to language models, which only allowed those models to handle audio for a limited set of pre-defined tasks. AudioChatLlama has general-purpose speech processing and understanding built into its core, allowing it to be a more versatile and capable conversational agent.
Technical Explanation
The key innovation in this work is the extension of the Llama-2 language model to directly process and generate audio and speech, rather than just interfacing with a separate speech recognition or synthesis system.
The researchers started with the pre-trained Llama-2 model and fine-tuned it end-to-end on a variety of audio-based tasks, including speech question answering, speech translation, and audio summarization. This allows the model to directly map between audio inputs and text outputs, without relying on an intermediate speech-to-text step.
Importantly, the AudioChatLlama model maintains the broad capabilities of the original Llama-2, allowing it to engage in open-ended conversations and tackle a wide range of language understanding and generation tasks. This is in contrast to prior speech-enabled language models that could only handle audio for a limited set of pre-defined tasks.
Evaluations on speech question answering benchmarks show that the end-to-end AudioChatLlama approach matches or outperforms cascaded systems that use a separate speech recognition model followed by a language model. Additionally, the integrated nature of the AudioChatLlama model allows it to better leverage conversational context when formulating responses.
Critical Analysis
A key strength of the AudioChatLlama model is its ability to handle a wide range of speech-related tasks in a general-purpose way, going beyond the limitations of prior approaches. However, the paper does not provide detailed comparisons to those prior works, making it difficult to fully assess the magnitude of the performance improvements.
Additionally, the researchers note that their approach does not use any "carefully curated paired data" for the audio-related fine-tuning. While this is an impressive feat, it raises questions about the quality and robustness of the model's speech processing capabilities compared to systems trained on large, high-quality speech datasets.
The paper also does not provide much insight into the architectural choices or training procedures used to enable the model's cross-modal capabilities. More details on these technical aspects would help the research community better understand how to replicate and build upon this work.
Finally, the potential negative societal impacts of a highly capable, general-purpose speech AI system are not discussed. Issues around bias, safety, and privacy should be carefully considered as this technology continues to advance.
Conclusion
The AudioChatLlama model represents a significant step forward in integrating speech and audio processing into large language models. By extending the capabilities of the Llama-2 model to handle a wide range of speech-based tasks, the researchers have created a more versatile and capable conversational agent.
The ability to engage in spoken interactions while maintaining broad language understanding and reasoning skills could have important implications for human-AI interaction, enabling more natural and effective communication. However, further research is needed to fully understand the limitations and potential risks of this technology.
Overall, this work represents a significant advance in the field of multimodal language models, paving the way for more seamless integration of speech and audio into general-purpose AI assistants.
Related Papers

Large Language User Interfaces: Voice Interactive User Interfaces powered by LLMs
Syed Mekael Wasti, Ken Q. Pu, Ali Neshati
0
0
The evolution of Large Language Models (LLMs) has showcased remarkable capacities for logical reasoning and natural language comprehension. These capabilities can be leveraged in solutions that semantically and textually model complex problems. In this paper, we present our efforts toward constructing a framework that can serve as an intermediary between a user and their user interface (UI), enabling dynamic and real-time interactions. We employ a system that stands upon textual semantic mappings of UI components, in the form of annotations. These mappings are stored, parsed, and scaled in a custom data structure, supplementary to an agent-based prompting backend engine. Employing textual semantic mappings allows each component to not only explain its role to the engine but also provide expectations. By comprehending the needs of both the user and the components, our LLM engine can classify the most appropriate application, extract relevant parameters, and subsequently execute precise predictions of the user's expected actions. Such an integration evolves static user interfaces into highly dynamic and adaptable solutions, introducing a new frontier of intelligent and responsive user experiences.
4/17/2024

Beyond Text: Utilizing Vocal Cues to Improve Decision Making in LLMs for Robot Navigation Tasks
Xingpeng Sun, Haoming Meng, Souradip Chakraborty, Amrit Singh Bedi, Aniket Bera
0
0
While LLMs excel in processing text in these human conversations, they struggle with the nuances of verbal instructions in scenarios like social navigation, where ambiguity and uncertainty can erode trust in robotic and other AI systems. We can address this shortcoming by moving beyond text and additionally focusing on the paralinguistic features of these audio responses. These features are the aspects of spoken communication that do not involve the literal wording (lexical content) but convey meaning and nuance through how something is said. We present emph{Beyond Text}; an approach that improves LLM decision-making by integrating audio transcription along with a subsection of these features, which focus on the affect and more relevant in human-robot conversations.This approach not only achieves a 70.26% winning rate, outperforming existing LLMs by 22.16% to 48.30% (gemini-1.5-pro and gpt-3.5 respectively), but also enhances robustness against token manipulation adversarial attacks, highlighted by a 22.44% less decrease ratio than the text-only language model in winning rate. ``textit{Beyond Text}'' marks an advancement in social robot navigation and broader Human-Robot interactions, seamlessly integrating text-based guidance with human-audio-informed language models.
4/24/2024

A Review of Multi-Modal Large Language and Vision Models
Kilian Carolan, Laura Fennelly, Alan F. Smeaton
0
0
Large Language Models (LLMs) have recently emerged as a focal point of research and application, driven by their unprecedented ability to understand and generate text with human-like quality. Even more recently, LLMs have been extended into multi-modal large language models (MM-LLMs) which extends their capabilities to deal with image, video and audio information, in addition to text. This opens up applications like text-to-video generation, image captioning, text-to-speech, and more and is achieved either by retro-fitting an LLM with multi-modal capabilities, or building a MM-LLM from scratch. This paper provides an extensive review of the current state of those LLMs with multi-modal capabilities as well as the very recent MM-LLMs. It covers the historical development of LLMs especially the advances enabled by transformer-based architectures like OpenAI's GPT series and Google's BERT, as well as the role of attention mechanisms in enhancing model performance. The paper includes coverage of the major and most important of the LLMs and MM-LLMs and also covers the techniques of model tuning, including fine-tuning and prompt engineering, which tailor pre-trained models to specific tasks or domains. Ethical considerations and challenges, such as data bias and model misuse, are also analysed to underscore the importance of responsible AI development and deployment. Finally, we discuss the implications of open-source versus proprietary models in AI research. Through this review, we provide insights into the transformative potential of MM-LLMs in various applications.
4/3/2024
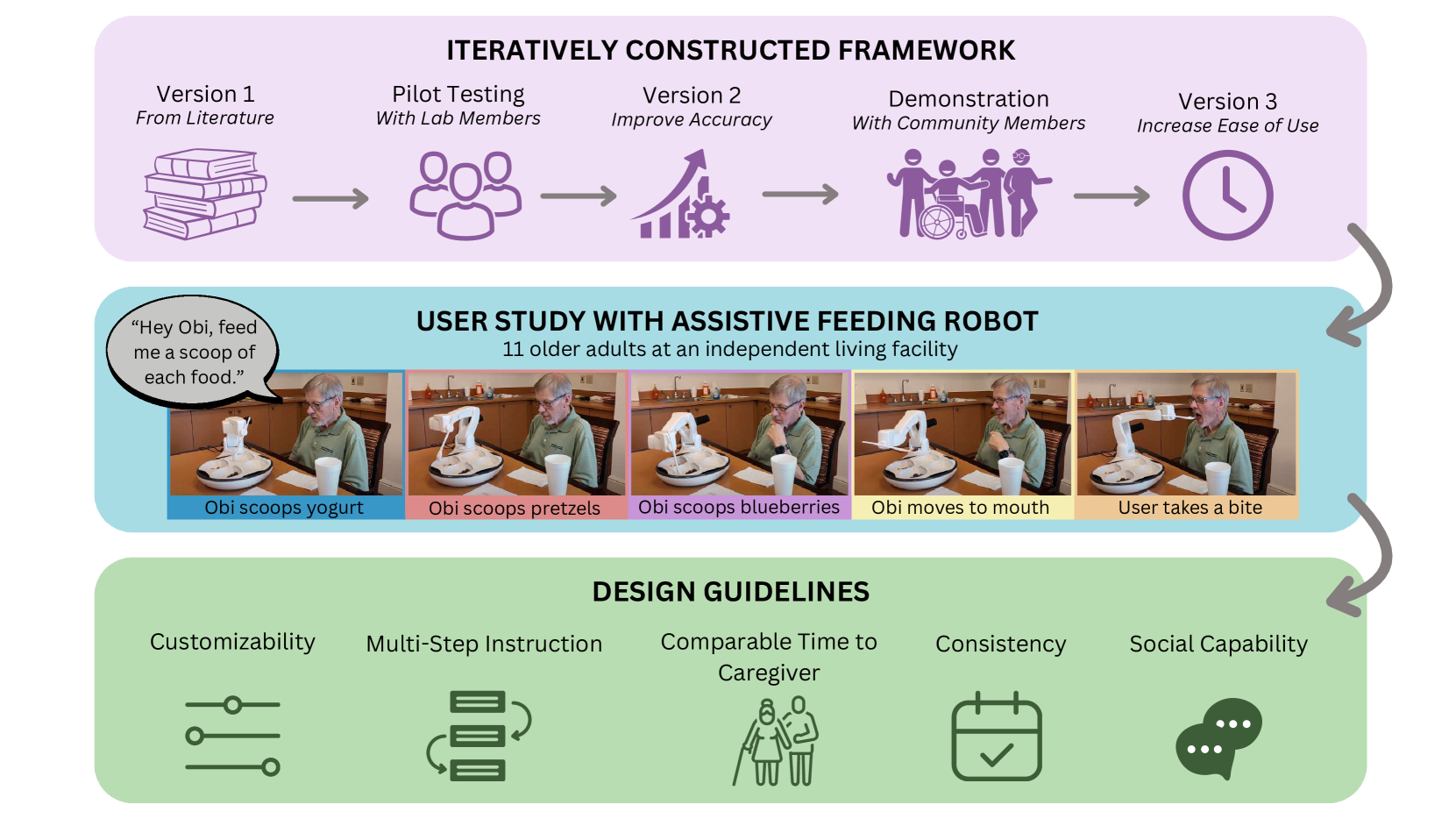
VoicePilot: Harnessing LLMs as Speech Interfaces for Physically Assistive Robots
Akhil Padmanabha, Jessie Yuan, Janavi Gupta, Zulekha Karachiwalla, Carmel Majidi, Henny Admoni, Zackory Erickson
0
0
Physically assistive robots present an opportunity to significantly increase the well-being and independence of individuals with motor impairments or other forms of disability who are unable to complete activities of daily living. Speech interfaces, especially ones that utilize Large Language Models (LLMs), can enable individuals to effectively and naturally communicate high-level commands and nuanced preferences to robots. Frameworks for integrating LLMs as interfaces to robots for high level task planning and code generation have been proposed, but fail to incorporate human-centric considerations which are essential while developing assistive interfaces. In this work, we present a framework for incorporating LLMs as speech interfaces for physically assistive robots, constructed iteratively with 3 stages of testing involving a feeding robot, culminating in an evaluation with 11 older adults at an independent living facility. We use both quantitative and qualitative data from the final study to validate our framework and additionally provide design guidelines for using LLMs as speech interfaces for assistive robots. Videos and supporting files are located on our project website: https://sites.google.com/andrew.cmu.edu/voicepilot/
4/8/2024