Beyond Uniform Query Distribution: Key-Driven Grouped Query Attention

0

Sign in to get full access
Overview
- The paper proposes a new attention mechanism called Key-Driven Grouped Query Attention (KDGQA) for Transformer-based models.
- KDGQA aims to improve query distribution by grouping queries based on their keys, rather than the typical uniform query distribution.
- The authors present experimental results demonstrating the advantages of KDGQA over standard attention on various tasks.
Plain English Explanation
In machine learning, Transformer models are a popular architecture used for tasks like natural language processing and computer vision. At the heart of Transformers is an attention mechanism, which allows the model to focus on the most relevant parts of its input when generating an output.
The standard attention mechanism assumes that all queries (the parts of the input the model is trying to understand) are equally important. However, in reality, some queries may be more important than others. The Key-Driven Grouped Query Attention (KDGQA) mechanism proposed in this paper tries to address this by grouping queries based on their "keys" (the underlying features that the model uses to determine relevance). This allows the model to allocate more attention to the more important queries, potentially improving its performance on various tasks.
Technical Explanation
The paper presents the Key-Driven Grouped Query Attention (KDGQA) mechanism, which builds on the standard Transformer attention mechanism. In a typical Transformer, the attention weights are calculated by comparing each query to all the keys (the underlying features that determine relevance) in the input. KDGQA, on the other hand, first groups the queries based on their keys, and then calculates the attention weights within each group.
This approach has several potential advantages:
- Improved Query Distribution: By grouping queries based on their keys, KDGQA can allocate more attention to the more important queries, rather than distributing attention uniformly as in the standard mechanism.
- Reduced Computational Complexity: Since the attention calculations are performed within smaller groups of queries, the overall computational complexity of the attention mechanism is reduced.
- Enhanced Interpretability: The grouping of queries based on their keys can provide a more interpretable view of the model's attention patterns, which can be useful for understanding and debugging the model's behavior.
The paper presents experimental results on various tasks, including natural language processing and computer vision, demonstrating the advantages of KDGQA over the standard attention mechanism.
Critical Analysis
The paper proposes a novel attention mechanism that addresses some of the limitations of the standard Transformer attention. The authors provide a thorough technical explanation of the KDGQA mechanism and demonstrate its advantages through experimental results.
One potential limitation of the KDGQA approach is that it assumes the queries can be meaningfully grouped based on their keys. In some cases, this grouping may not be straightforward, and the performance of KDGQA may be sensitive to the quality of the grouping. Additionally, the paper does not explore the impact of the number of groups or the grouping strategy on the model's performance, which could be an area for further research.
Furthermore, the paper focuses on the attention mechanism itself and does not delve into the broader implications of this approach for Transformer-based models. It would be interesting to see how KDGQA could be integrated into different Transformer architectures and how it might affect the overall model performance and interpretability.
Conclusion
The Key-Driven Grouped Query Attention (KDGQA) mechanism proposed in this paper represents a promising approach to improving the attention mechanism in Transformer-based models. By grouping queries based on their keys, KDGQA can allocate attention more effectively, leading to potential performance gains and enhanced interpretability.
While the paper provides a solid technical foundation and experimental results, further research is needed to explore the broader implications of this approach and address any potential limitations. As Transformer models continue to play a central role in various machine learning applications, innovations like KDGQA can contribute to the ongoing advancement of these powerful architectures.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Beyond Uniform Query Distribution: Key-Driven Grouped Query Attention
Zohaib Khan, Muhammad Khaquan, Omer Tafveez, Burhanuddin Samiwala, Agha Ali Raza
The Transformer architecture has revolutionized deep learning through its Self-Attention mechanism, which effectively captures contextual information. However, the memory footprint of Self-Attention presents significant challenges for long-sequence tasks. Grouped Query Attention (GQA) addresses this issue by grouping queries and mean-pooling the corresponding key-value heads - reducing the number of overall parameters and memory requirements in a flexible manner without adversely compromising model accuracy. In this work, we introduce enhancements to GQA, focusing on two novel approaches that deviate from the static nature of grouping: Key-Distributed GQA (KDGQA) and Dynamic Key-Distributed GQA (DGQA), which leverage information from the norms of the key heads to inform query allocation. Specifically, KDGQA looks at the ratios of the norms of the key heads during each forward pass, while DGQA examines the ratios of the norms as they evolve through training. Additionally, we present Perturbed GQA (PGQA) as a case-study, which introduces variability in (static) group formation via subtracting noise from the attention maps. Our experiments with up-trained Vision Transformers, for Image Classification on datasets such as CIFAR-10, CIFAR-100, Food101, and Tiny ImageNet, demonstrate the promise of these variants in improving upon the original GQA through more informed and adaptive grouping mechanisms: specifically ViT-L experiences accuracy gains of up to 8% when utilizing DGQA in comparison to GQA and other variants. We further analyze the impact of the number of Key-Value Heads on performance, underscoring the importance of utilizing query-key affinities. Code is available on GitHub.
Read more8/29/2024

0
Weighted Grouped Query Attention in Transformers
Sai Sena Chinnakonduru, Astarag Mohapatra
The attention mechanism forms the foundational blocks for transformer language models. Recent approaches show that scaling the model achieves human-level performance. However, with increasing demands for scaling and constraints on hardware memory, the inference costs of these models remain high. To reduce the inference time, Multi-Query Attention (MQA) and Grouped-Query Attention (GQA) were proposed in (Shazeer, 2019) and (Ainslieet al., 2023) respectively. In this paper, we propose a variation of Grouped-Query Attention, termed Weighted Grouped-Query Attention (WGQA). We introduced new learnable parameters for each key and value head in the T5 decoder attention blocks, enabling the model to take a weighted average during finetuning. Our model achieves an average of 0.53% improvement over GQA, and the performance converges to traditional Multi-head attention (MHA) with no additional overhead during inference. We evaluated the introduction of these parameters and subsequent finetuning informs the model about the grouping mechanism during training, thereby enhancing performance. Additionally, we demonstrate the scaling laws in our analysis by comparing the results between T5-small and T5-base architecture.
Read more7/16/2024
0
QCQA: Quality and Capacity-aware grouped Query Attention
Vinay Joshi, Prashant Laddha, Shambhavi Sinha, Om Ji Omer, Sreenivas Subramoney
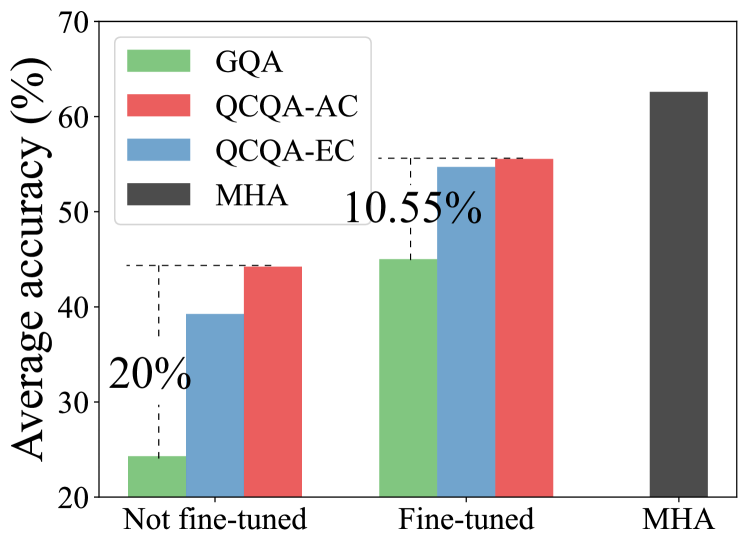
Excessive memory requirements of key and value features (KV-cache) present significant challenges in the autoregressive inference of large language models (LLMs), restricting both the speed and length of text generation. Approaches such as Multi-Query Attention (MQA) and Grouped Query Attention (GQA) mitigate these challenges by grouping query heads and consequently reducing the number of corresponding key and value heads. However, MQA and GQA decrease the KV-cache size requirements at the expense of LLM accuracy (quality of text generation). These methods do not ensure an optimal tradeoff between KV-cache size and text generation quality due to the absence of quality-aware grouping of query heads. To address this issue, we propose Quality and Capacity-Aware Grouped Query Attention (QCQA), which identifies optimal query head groupings using an evolutionary algorithm with a computationally efficient and inexpensive fitness function. We demonstrate that QCQA achieves a significantly better tradeoff between KV-cache capacity and LLM accuracy compared to GQA. For the Llama2 $7,$B model, QCQA achieves $mathbf{20}$% higher accuracy than GQA with similar KV-cache size requirements in the absence of fine-tuning. After fine-tuning both QCQA and GQA, for a similar KV-cache size, QCQA provides $mathbf{10.55},$% higher accuracy than GQA. Furthermore, QCQA requires $40,$% less KV-cache size than GQA to attain similar accuracy. The proposed quality and capacity-aware grouping of query heads can serve as a new paradigm for KV-cache optimization in autoregressive LLM inference.
Read more6/18/2024

0
Optimised Grouped-Query Attention Mechanism for Transformers
Yuang Chen, Cheng Zhang, Xitong Gao, Robert D. Mullins, George A. Constantinides, Yiren Zhao
Grouped-query attention (GQA) has been widely adopted in LLMs to mitigate the complexity of multi-head attention (MHA). To transform an MHA to a GQA, neighbour queries in MHA are evenly split into groups where each group shares the value and key layers. In this work, we propose AsymGQA, an activation-informed approach to asymmetrically grouping an MHA to a GQA for better model performance. Our AsymGQA outperforms the GQA within the same model size budget. For example, AsymGQA LLaMA-2-7B has an accuracy increase of 7.5% on MMLU compared to neighbour grouping. Our approach addresses the GQA's trade-off problem between model performance and hardware efficiency.
Read more6/24/2024