Beyond Viewpoint: Robust 3D Object Recognition under Arbitrary Views through Joint Multi-Part Representation

0

Sign in to get full access
Overview
- The paper proposes a novel approach for robust 3D object recognition under arbitrary views.
- It introduces a joint multi-part representation that leverages both global and local shape information.
- The method achieves state-of-the-art performance on several 3D object recognition benchmarks.
Plain English Explanation
The research paper presents a new way to recognize 3D objects from different angles and perspectives. Typically, 3D object recognition systems struggle when presented with objects from unusual or unfamiliar viewpoints. This paper introduces a technique that combines both overall shape information and more granular details about the different parts that make up an object.
By representing objects using this joint multi-part representation, the system is able to better handle objects seen from arbitrary angles, rather than just the common or "standard" views. This allows the model to more accurately identify and classify 3D objects, even when they are oriented in unconventional ways.
The authors demonstrate that their approach outperforms existing methods on several benchmark datasets for 3D object recognition. This suggests the technique could be valuable for applications like autonomous vehicles, robotics, and augmented reality, where the ability to reliably recognize 3D objects from any angle is critical.
Technical Explanation
The core innovation of this paper is the joint multi-part representation for 3D objects. Rather than just encoding the overall shape of an object, the system also models the individual parts that make up the object's structure.
This is achieved through a neural network architecture that jointly learns global shape features as well as part-level details. The global shape features capture the holistic appearance of the object, while the part-level features encode more granular information about the object's constituent components.
By combining these complementary representations, the model is able to better handle objects seen from arbitrary viewpoints, as the part-level features provide additional cues to recognize the object even when its global shape is distorted or partially occluded.
The authors evaluate their approach on several standard 3D object recognition benchmarks, including ModelNet, ShapeNet, and ScanObjectNN. Across these datasets, the joint multi-part representation consistently outperforms prior state-of-the-art methods, demonstrating the effectiveness of this technique for robust 3D object recognition.
Critical Analysis
The paper makes a compelling case for the benefits of the joint multi-part representation for 3D object recognition. By explicitly modeling both global and local shape features, the approach is able to overcome the limitations of prior methods that relied solely on holistic shape information.
However, one potential limitation is the computational complexity of the joint representation, as encoding part-level details in addition to global shape features may increase the model's size and inference time. The authors do not provide extensive analysis of the runtime or memory footprint of their approach, which could be an important consideration for real-world applications with strict latency or resource constraints.
Additionally, the paper focuses primarily on recognition of static 3D objects in controlled settings. It remains to be seen how well the technique would generalize to more dynamic, cluttered, or challenging real-world scenarios, such as 3D object detection in autonomous driving or robotic manipulation tasks. Further research may be needed to address these more practical deployment challenges.
Conclusion
This paper introduces a novel joint multi-part representation for robust 3D object recognition, which outperforms previous state-of-the-art methods on several standard benchmarks. By encoding both global shape information and part-level details, the approach demonstrates improved performance in handling objects from arbitrary viewpoints.
The findings of this research have the potential to advance the state-of-the-art in 3D object recognition, with applications in areas like autonomous vehicles, robotics, and augmented reality, where the ability to reliably identify 3D objects from any angle is crucial. While the technique shows promise, further exploration of its computational efficiency and real-world performance may be warranted to fully assess its practical impact.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Beyond Viewpoint: Robust 3D Object Recognition under Arbitrary Views through Joint Multi-Part Representation
Linlong Fan, Ye Huang, Yanqi Ge, Wen Li, Lixin Duan
Existing view-based methods excel at recognizing 3D objects from predefined viewpoints, but their exploration of recognition under arbitrary views is limited. This is a challenging and realistic setting because each object has different viewpoint positions and quantities, and their poses are not aligned. However, most view-based methods, which aggregate multiple view features to obtain a global feature representation, hard to address 3D object recognition under arbitrary views. Due to the unaligned inputs from arbitrary views, it is challenging to robustly aggregate features, leading to performance degradation. In this paper, we introduce a novel Part-aware Network (PANet), which is a part-based representation, to address these issues. This part-based representation aims to localize and understand different parts of 3D objects, such as airplane wings and tails. It has properties such as viewpoint invariance and rotation robustness, which give it an advantage in addressing the 3D object recognition problem under arbitrary views. Our results on benchmark datasets clearly demonstrate that our proposed method outperforms existing view-based aggregation baselines for the task of 3D object recognition under arbitrary views, even surpassing most fixed viewpoint methods.
Read more7/18/2024
🤿
0
Deep Models for Multi-View 3D Object Recognition: A Review
Mona Alzahrani, Muhammad Usman, Salma Kammoun, Saeed Anwar, Tarek Helmy
Human decision-making often relies on visual information from multiple perspectives or views. In contrast, machine learning-based object recognition utilizes information from a single image of the object. However, the information conveyed by a single image may not be sufficient for accurate decision-making, particularly in complex recognition problems. The utilization of multi-view 3D representations for object recognition has thus far demonstrated the most promising results for achieving state-of-the-art performance. This review paper comprehensively covers recent progress in multi-view 3D object recognition methods for 3D classification and retrieval tasks. Specifically, we focus on deep learning-based and transformer-based techniques, as they are widely utilized and have achieved state-of-the-art performance. We provide detailed information about existing deep learning-based and transformer-based multi-view 3D object recognition models, including the most commonly used 3D datasets, camera configurations and number of views, view selection strategies, pre-trained CNN architectures, fusion strategies, and recognition performance on 3D classification and 3D retrieval tasks. Additionally, we examine various computer vision applications that use multi-view classification. Finally, we highlight key findings and future directions for developing multi-view 3D object recognition methods to provide readers with a comprehensive understanding of the field.
Read more4/24/2024

0
Part123: Part-aware 3D Reconstruction from a Single-view Image
Anran Liu, Cheng Lin, Yuan Liu, Xiaoxiao Long, Zhiyang Dou, Hao-Xiang Guo, Ping Luo, Wenping Wang
Recently, the emergence of diffusion models has opened up new opportunities for single-view reconstruction. However, all the existing methods represent the target object as a closed mesh devoid of any structural information, thus neglecting the part-based structure, which is crucial for many downstream applications, of the reconstructed shape. Moreover, the generated meshes usually suffer from large noises, unsmooth surfaces, and blurry textures, making it challenging to obtain satisfactory part segments using 3D segmentation techniques. In this paper, we present Part123, a novel framework for part-aware 3D reconstruction from a single-view image. We first use diffusion models to generate multiview-consistent images from a given image, and then leverage Segment Anything Model (SAM), which demonstrates powerful generalization ability on arbitrary objects, to generate multiview segmentation masks. To effectively incorporate 2D part-based information into 3D reconstruction and handle inconsistency, we introduce contrastive learning into a neural rendering framework to learn a part-aware feature space based on the multiview segmentation masks. A clustering-based algorithm is also developed to automatically derive 3D part segmentation results from the reconstructed models. Experiments show that our method can generate 3D models with high-quality segmented parts on various objects. Compared to existing unstructured reconstruction methods, the part-aware 3D models from our method benefit some important applications, including feature-preserving reconstruction, primitive fitting, and 3D shape editing.
Read more5/28/2024
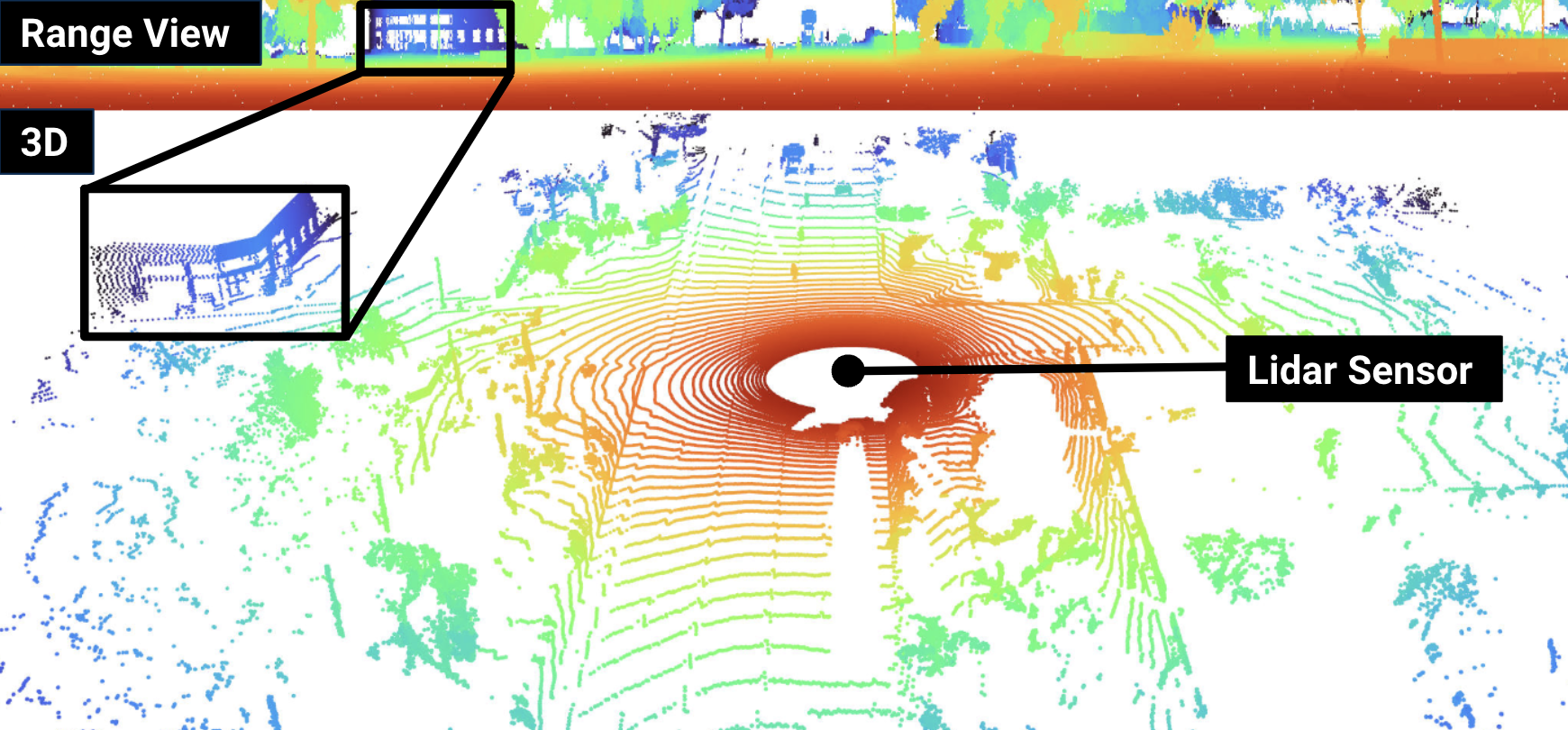
0
What Matters in Range View 3D Object Detection
Benjamin Wilson, Nicholas Autio Mitchell, Jhony Kaesemodel Pontes, James Hays
Lidar-based perception pipelines rely on 3D object detection models to interpret complex scenes. While multiple representations for lidar exist, the range-view is enticing since it losslessly encodes the entire lidar sensor output. In this work, we achieve state-of-the-art amongst range-view 3D object detection models without using multiple techniques proposed in past range-view literature. We explore range-view 3D object detection across two modern datasets with substantially different properties: Argoverse 2 and Waymo Open. Our investigation reveals key insights: (1) input feature dimensionality significantly influences the overall performance, (2) surprisingly, employing a classification loss grounded in 3D spatial proximity works as well or better compared to more elaborate IoU-based losses, and (3) addressing non-uniform lidar density via a straightforward range subsampling technique outperforms existing multi-resolution, range-conditioned networks. Our experiments reveal that techniques proposed in recent range-view literature are not needed to achieve state-of-the-art performance. Combining the above findings, we establish a new state-of-the-art model for range-view 3D object detection -- improving AP by 2.2% on the Waymo Open dataset while maintaining a runtime of 10 Hz. We establish the first range-view model on the Argoverse 2 dataset and outperform strong voxel-based baselines. All models are multi-class and open-source. Code is available at https://github.com/benjaminrwilson/range-view-3d-detection.
Read more7/29/2024