Bi-DCSpell: A Bi-directional Detector-Corrector Interactive Framework for Chinese Spelling Check

0
Sign in to get full access
Overview
- This paper proposes a bi-directional detector-corrector interactive framework called Bi-DCSpell for Chinese spelling check.
- Bi-DCSpell combines detector and corrector models to detect and correct spelling errors in Chinese text in an interactive manner.
- The framework leverages both character-level and context-level information to improve performance on Chinese spelling error detection and correction.
Plain English Explanation
The paper introduces a new system called Bi-DCSpell that helps detect and fix spelling mistakes in Chinese text. Spelling errors can be common when writing in Chinese, as the language has a complex writing system with many characters. Bi-DCSpell addresses this problem by using two separate models - a detector model to identify where errors are, and a corrector model to suggest the right way to fix them.
The key innovation is that Bi-DCSpell uses information from both the individual characters and the surrounding context to make its decisions. This bi-directional approach helps it better understand the meaning and flow of the text, allowing it to more accurately pinpoint errors and provide appropriate corrections.
By integrating the detector and corrector components, Bi-DCSpell can work interactively with users, highlighting potential problems and offering real-time suggestions for improvement. This interactive nature makes the system more user-friendly and effective at helping writers catch and correct Chinese spelling mistakes.
Technical Explanation
The paper proposes a Bi-DCSpell: A Bi-directional Detector-Corrector Interactive Framework for Chinese Spelling Check framework that combines a detector model and a corrector model to detect and correct spelling errors in Chinese text.
The detector model uses a BERT-based architecture to capture both character-level and context-level information to identify potential spelling errors. The corrector model then leverages this information, along with a language model, to generate corrected versions of the text.
By integrating the detector and corrector components, Bi-DCSpell can provide an interactive experience, allowing users to review the detected errors and choose from the suggested corrections. This bi-directional approach helps the system better understand the full meaning and flow of the text, leading to more accurate and contextually relevant error detection and correction.
The authors evaluate Bi-DCSpell on several Chinese spelling check datasets, including CSCD-NS and ALIRECTOR, and show that it outperforms state-of-the-art methods in both detection and correction tasks.
Critical Analysis
The paper provides a thorough evaluation of Bi-DCSpell's performance on several Chinese spelling check datasets, demonstrating its effectiveness in both detecting and correcting spelling errors. However, the authors do not discuss any potential limitations or caveats of their approach.
One area that could be explored further is the system's handling of more complex or contextual errors, such as those related to grammatical or semantic issues. The authors focus primarily on character-level spelling mistakes, but real-world writing may involve more nuanced errors that require a deeper understanding of language.
Additionally, the performance of Bi-DCSpell on low-resource language models or less common/rare errors could be an interesting area for further research and evaluation.
Overall, the Bi-DCSpell framework represents a promising approach to Chinese spelling error detection and correction, but there may be opportunities to expand its capabilities and robustness in future work.
Conclusion
This paper introduces Bi-DCSpell, a bi-directional detector-corrector interactive framework for Chinese spelling check. By combining detection and correction models that leverage both character-level and context-level information, Bi-DCSpell can effectively identify and suggest fixes for spelling errors in Chinese text.
The interactive nature of the system, which allows users to review detected errors and choose from suggested corrections, makes it a user-friendly tool for improving Chinese writing. The authors demonstrate Bi-DCSpell's strong performance on several benchmark datasets, highlighting its potential to enhance the quality and accuracy of Chinese language processing applications.
While the paper focuses primarily on character-level spelling mistakes, further research could explore Bi-DCSpell's handling of more complex linguistic errors. Nonetheless, this work represents an important step forward in developing robust Chinese spelling check capabilities.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Bi-DCSpell: A Bi-directional Detector-Corrector Interactive Framework for Chinese Spelling Check
Haiming Wu, Hanqing Zhang, Richeng Xuan, Dawei Song
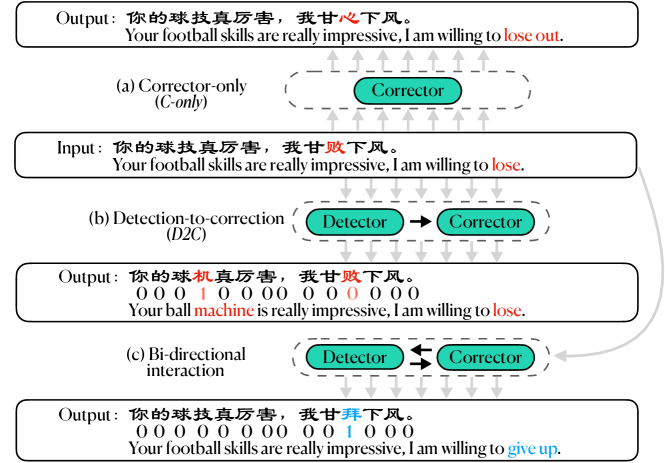
Chinese Spelling Check (CSC) aims to detect and correct potentially misspelled characters in Chinese sentences. Naturally, it involves the detection and correction subtasks, which interact with each other dynamically. Such interactions are bi-directional, i.e., the detection result would help reduce the risk of over-correction and under-correction while the knowledge learnt from correction would help prevent false detection. Current CSC approaches are of two types: correction-only or single-directional detection-to-correction interactive frameworks. Nonetheless, they overlook the bi-directional interactions between detection and correction. This paper aims to fill the gap by proposing a Bi-directional Detector-Corrector framework for CSC (Bi-DCSpell). Notably, Bi-DCSpell contains separate detection and correction encoders, followed by a novel interactive learning module facilitating bi-directional feature interactions between detection and correction to improve each other's representation learning. Extensive experimental results demonstrate a robust correction performance of Bi-DCSpell on widely used benchmarking datasets while possessing a satisfactory detection ability.
Read more8/14/2024

0
A Coin Has Two Sides: A Novel Detector-Corrector Framework for Chinese Spelling Correction
Xiangke Zeng, Zuchao Li, Lefei Zhang, Ping Wang, Hongqiu Wu, Hai Zhao
Chinese Spelling Correction (CSC) stands as a foundational Natural Language Processing (NLP) task, which primarily focuses on the correction of erroneous characters in Chinese texts. Certain existing methodologies opt to disentangle the error correction process, employing an additional error detector to pinpoint error positions. However, owing to the inherent performance limitations of error detector, precision and recall are like two sides of the coin which can not be both facing up simultaneously. Furthermore, it is also worth investigating how the error position information can be judiciously applied to assist the error correction. In this paper, we introduce a novel approach based on error detector-corrector framework. Our detector is designed to yield two error detection results, each characterized by high precision and recall. Given that the occurrence of errors is context-dependent and detection outcomes may be less precise, we incorporate the error detection results into the CSC task using an innovative feature fusion strategy and a selective masking strategy. Empirical experiments conducted on mainstream CSC datasets substantiate the efficacy of our proposed method.
Read more9/9/2024
0
EdaCSC: Two Easy Data Augmentation Methods for Chinese Spelling Correction
Lei Sheng, Shuai-Shuai Xu
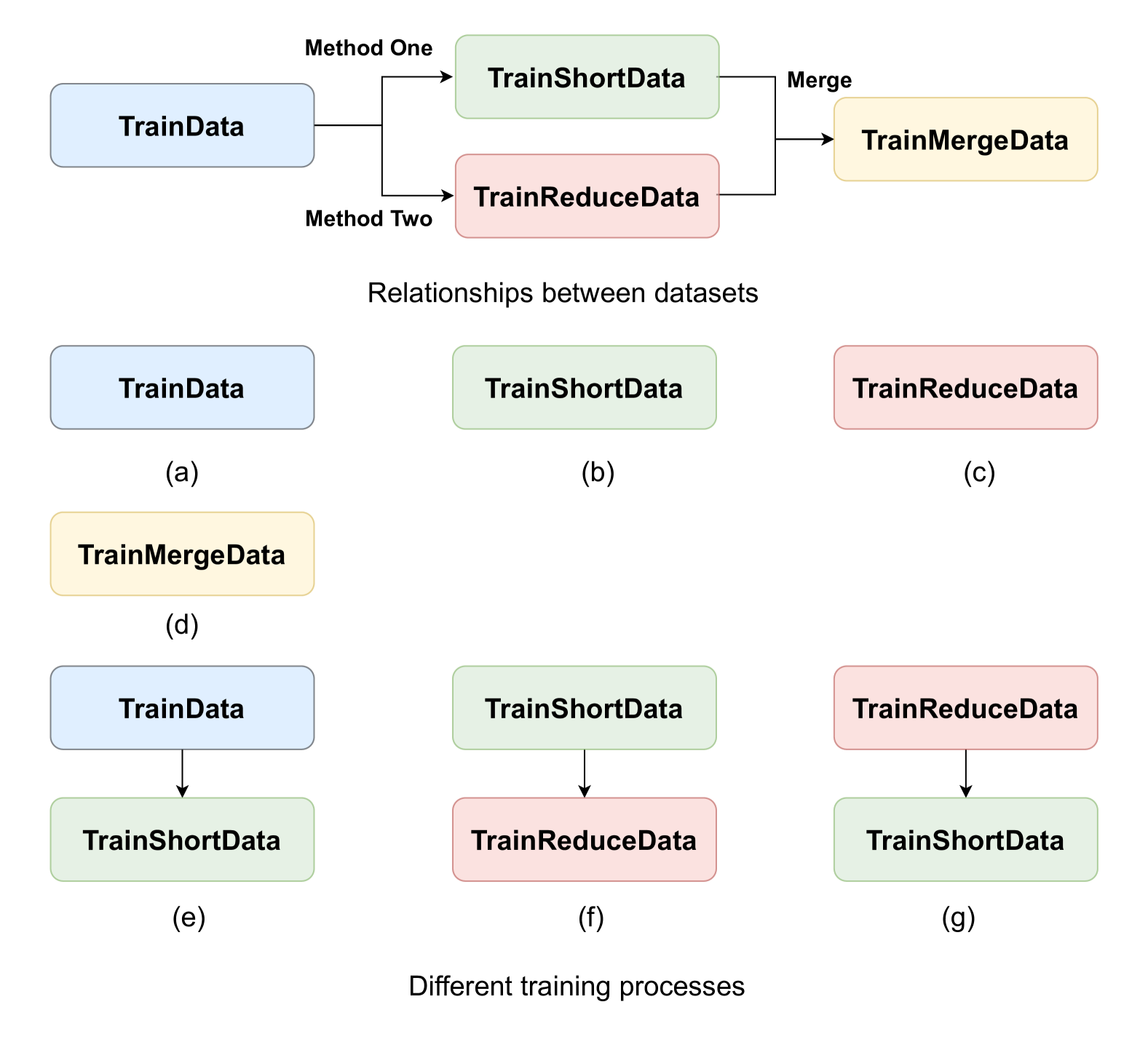
Chinese Spelling Correction (CSC) aims to detect and correct spelling errors in Chinese sentences caused by phonetic or visual similarities. While current CSC models integrate pinyin or glyph features and have shown significant progress,they still face challenges when dealing with sentences containing multiple typos and are susceptible to overcorrection in real-world scenarios. In contrast to existing model-centric approaches, we propose two data augmentation methods to address these limitations. Firstly, we augment the dataset by either splitting long sentences into shorter ones or reducing typos in sentences with multiple typos. Subsequently, we employ different training processes to select the optimal model. Experimental evaluations on the SIGHAN benchmarks demonstrate the superiority of our approach over most existing models, achieving state-of-the-art performance on the SIGHAN15 test set.
Read more9/10/2024
⛏️
0
CSCD-NS: a Chinese Spelling Check Dataset for Native Speakers
Yong Hu, Fandong Meng, Jie Zhou
In this paper, we present CSCD-NS, the first Chinese spelling check (CSC) dataset designed for native speakers, containing 40,000 samples from a Chinese social platform. Compared with existing CSC datasets aimed at Chinese learners, CSCD-NS is ten times larger in scale and exhibits a distinct error distribution, with a significantly higher proportion of word-level errors. To further enhance the data resource, we propose a novel method that simulates the input process through an input method, generating large-scale and high-quality pseudo data that closely resembles the actual error distribution and outperforms existing methods. Moreover, we investigate the performance of various models in this scenario, including large language models (LLMs), such as ChatGPT. The result indicates that generative models underperform BERT-like classification models due to strict length and pronunciation constraints. The high prevalence of word-level errors also makes CSC for native speakers challenging enough, leaving substantial room for improvement.
Read more5/24/2024