A Coin Has Two Sides: A Novel Detector-Corrector Framework for Chinese Spelling Correction

0

Sign in to get full access
Overview
- A novel detector-corrector framework for Chinese spelling correction
- Combines a spelling error detector and a spelling error corrector in a unified model
- Outperforms existing Chinese spelling correction models on multiple benchmarks
Plain English Explanation
The paper presents a new framework for correcting spelling mistakes in Chinese text. The key idea is to combine a spelling error detector and a spelling error corrector into a single unified model.
The detector identifies which words in the input text are potentially misspelled, while the corrector suggests the correct spelling for those words. By integrating these two components, the framework can accurately detect and fix spelling errors in Chinese, outperforming existing approaches.
The authors use advanced machine learning techniques to train their model on large datasets of Chinese text, allowing it to learn the patterns and rules of the language. This enables the model to recognize common spelling mistakes and provide appropriate corrections.
One of the novel aspects of this work is the use of a bidirectional architecture, where the model considers the context of a word both before and after it to make more accurate decisions. This helps the model better understand the meaning and grammar of the text, leading to more reliable spelling corrections.
The researchers evaluated their framework on several benchmark datasets for Chinese spelling correction and found that it outperforms previous state-of-the-art models. This suggests that their approach is a significant advancement in the field of Chinese language processing.
Technical Explanation
The paper introduces a novel detector-corrector framework for Chinese spelling correction. The key components of this framework are:
-
Spelling Error Detector: This module identifies which words in the input text are potentially misspelled. The authors use a BERT-based model to encode the input sequence and classify each word as either correct or incorrect.
-
Spelling Error Corrector: This module generates the correct spelling for any words that the detector identifies as misspelled. The authors employ a sequence-to-sequence model, also based on BERT, to translate the incorrect word into its correct form.
The detector and corrector modules are trained jointly in an end-to-end fashion, allowing the model to learn the relationship between error detection and correction. The authors also incorporate a bidirectional architecture, where the model considers the context of a word both before and after it when making decisions.
Extensive experiments on multiple Chinese spelling correction benchmarks demonstrate the effectiveness of the proposed framework. It outperforms previous state-of-the-art models in terms of both detection and correction accuracy, showcasing the benefits of the unified detector-corrector approach.
Critical Analysis
The paper presents a well-designed and technically sound framework for Chinese spelling correction. The key strengths of this work include:
- Integrated Detector-Corrector Architecture: Combining the error detection and correction components into a single model is a clever and effective approach, as it allows the model to learn the connections between these two tasks.
- Bidirectional Modeling: Considering the context of a word in both directions is a valuable addition that helps the model better understand the linguistic structure of the text.
- Robust Evaluation: The authors thoroughly evaluate their framework on multiple benchmark datasets, demonstrating its consistent performance across different settings.
However, some potential limitations and areas for further research include:
- Data Diversity: The authors primarily evaluate their model on datasets that may not fully capture the diversity of real-world Chinese text, such as social media or user-generated content. Expanding the evaluation to more varied data sources could provide additional insights.
- Computational Efficiency: The paper does not discuss the computational requirements or inference time of the proposed framework, which could be an important consideration for practical applications.
- Interpretability: The use of complex neural network architectures, while effective, can make it challenging to interpret the model's decision-making process. Exploring more interpretable approaches could be a valuable direction for future research.
Overall, the paper presents a promising and well-executed framework for Chinese spelling correction, with several interesting technical contributions and opportunities for further exploration.
Conclusion
This paper introduces a novel detector-corrector framework for Chinese spelling correction that outperforms existing state-of-the-art models. By combining a spelling error detector and a spelling error corrector into a unified model with a bidirectional architecture, the authors have developed an effective solution for identifying and correcting spelling mistakes in Chinese text.
The strong experimental results on multiple benchmarks suggest that this framework could have significant practical applications in a variety of Chinese language processing tasks, such as content moderation, text generation, and language learning. The technical insights and innovations presented in this work also provide valuable contributions to the broader field of natural language processing.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
A Coin Has Two Sides: A Novel Detector-Corrector Framework for Chinese Spelling Correction
Xiangke Zeng, Zuchao Li, Lefei Zhang, Ping Wang, Hongqiu Wu, Hai Zhao
Chinese Spelling Correction (CSC) stands as a foundational Natural Language Processing (NLP) task, which primarily focuses on the correction of erroneous characters in Chinese texts. Certain existing methodologies opt to disentangle the error correction process, employing an additional error detector to pinpoint error positions. However, owing to the inherent performance limitations of error detector, precision and recall are like two sides of the coin which can not be both facing up simultaneously. Furthermore, it is also worth investigating how the error position information can be judiciously applied to assist the error correction. In this paper, we introduce a novel approach based on error detector-corrector framework. Our detector is designed to yield two error detection results, each characterized by high precision and recall. Given that the occurrence of errors is context-dependent and detection outcomes may be less precise, we incorporate the error detection results into the CSC task using an innovative feature fusion strategy and a selective masking strategy. Empirical experiments conducted on mainstream CSC datasets substantiate the efficacy of our proposed method.
Read more9/9/2024
0
Bi-DCSpell: A Bi-directional Detector-Corrector Interactive Framework for Chinese Spelling Check
Haiming Wu, Hanqing Zhang, Richeng Xuan, Dawei Song
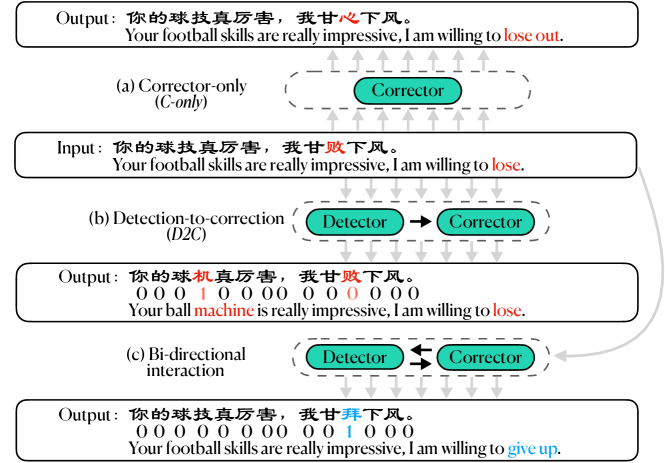
Chinese Spelling Check (CSC) aims to detect and correct potentially misspelled characters in Chinese sentences. Naturally, it involves the detection and correction subtasks, which interact with each other dynamically. Such interactions are bi-directional, i.e., the detection result would help reduce the risk of over-correction and under-correction while the knowledge learnt from correction would help prevent false detection. Current CSC approaches are of two types: correction-only or single-directional detection-to-correction interactive frameworks. Nonetheless, they overlook the bi-directional interactions between detection and correction. This paper aims to fill the gap by proposing a Bi-directional Detector-Corrector framework for CSC (Bi-DCSpell). Notably, Bi-DCSpell contains separate detection and correction encoders, followed by a novel interactive learning module facilitating bi-directional feature interactions between detection and correction to improve each other's representation learning. Extensive experimental results demonstrate a robust correction performance of Bi-DCSpell on widely used benchmarking datasets while possessing a satisfactory detection ability.
Read more8/14/2024
0
EdaCSC: Two Easy Data Augmentation Methods for Chinese Spelling Correction
Lei Sheng, Shuai-Shuai Xu
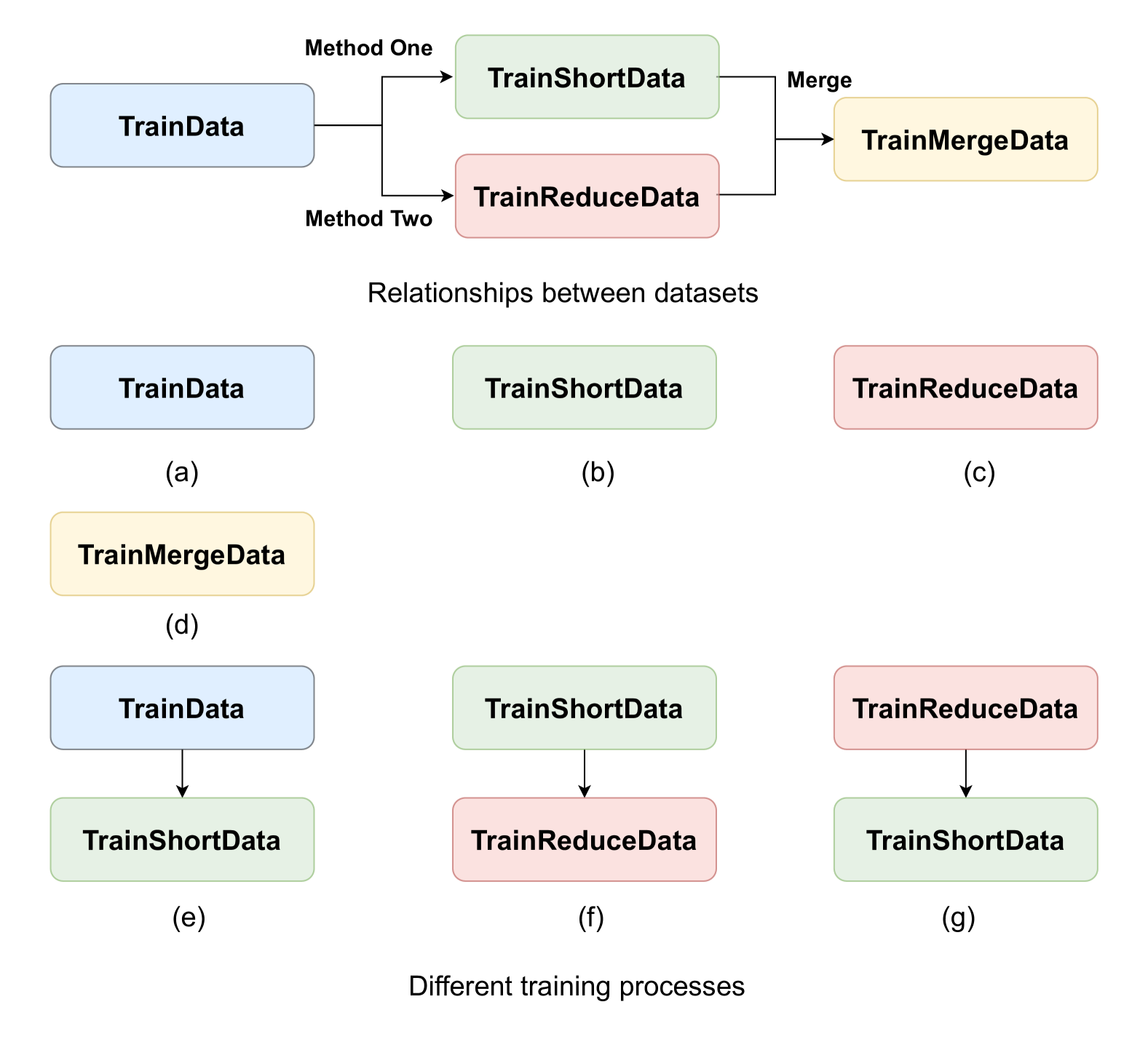
Chinese Spelling Correction (CSC) aims to detect and correct spelling errors in Chinese sentences caused by phonetic or visual similarities. While current CSC models integrate pinyin or glyph features and have shown significant progress,they still face challenges when dealing with sentences containing multiple typos and are susceptible to overcorrection in real-world scenarios. In contrast to existing model-centric approaches, we propose two data augmentation methods to address these limitations. Firstly, we augment the dataset by either splitting long sentences into shorter ones or reducing typos in sentences with multiple typos. Subsequently, we employ different training processes to select the optimal model. Experimental evaluations on the SIGHAN benchmarks demonstrate the superiority of our approach over most existing models, achieving state-of-the-art performance on the SIGHAN15 test set.
Read more9/10/2024

0
C-LLM: Learn to Check Chinese Spelling Errors Character by Character
Kunting Li, Yong Hu, Liang He, Fandong Meng, Jie Zhou
Chinese Spell Checking (CSC) aims to detect and correct spelling errors in sentences. Despite Large Language Models (LLMs) exhibit robust capabilities and are widely applied in various tasks, their performance on CSC is often unsatisfactory. We find that LLMs fail to meet the Chinese character-level constraints of the CSC task, namely equal length and phonetic similarity, leading to a performance bottleneck. Further analysis reveal that this issue stems from the granularity of tokenization, as current mixed character-word tokenization struggles to satisfy these character-level constraints. To address this issue, we propose C-LLM, a Large Language Model-based Chinese Spell Checking method that learns to check errors Character by Character. Character-level tokenization enables the model to learn character-level alignment, effectively mitigating issues related to character-level constraints. Furthermore, CSC is simplified to replication-dominated and substitution-supplemented tasks. Experiments on two CSC benchmarks demonstrate that C-LLM achieves an average improvement of 10% over existing methods. Specifically, it shows a 2.1% improvement in general scenarios and a significant 12% improvement in vertical domain scenarios, establishing state-of-the-art performance. The source code can be accessed at https://github.com/ktlKTL/C-LLM.
Read more6/26/2024