CSCD-NS: a Chinese Spelling Check Dataset for Native Speakers

0
⛏️
Sign in to get full access
Overview
- Researchers present a new Chinese spelling check (CSC) dataset called CSCD-NS, designed for native Chinese speakers
- CSCD-NS is 10 times larger than existing CSC datasets for Chinese learners and has a different error distribution, with more word-level errors
- The researchers propose a novel method to generate high-quality pseudo data that closely matches the actual error distribution, outperforming existing techniques
- The paper investigates the performance of various models, including large language models (LLMs) like ChatGPT, on this task, finding that generative models underperform classification models due to strict length and pronunciation constraints
Plain English Explanation
The researchers have created a new dataset called CSCD-NS specifically for testing Chinese spelling correction systems for native Chinese speakers. Existing spelling correction datasets have been focused on Chinese language learners, but this new dataset is much larger (10 times the size) and has a different pattern of errors, with more mistakes at the word level rather than just typos.
To further improve this dataset, the researchers developed a new method to automatically generate high-quality simulated data that closely matches the real-world error distribution, which is better than previous approaches. They also tested how well different AI models, including large language models like ChatGPT, perform on this Chinese spelling correction task.
The results show that generative models, which try to produce the correct text, don't work as well as classification models, which just identify the errors. This is because the task has strict requirements around word length and pronunciation that make it challenging for the generative models. Overall, the researchers found that spelling correction for native Chinese speakers is a difficult problem that still has room for improvement.
Technical Explanation
The researchers present a new Chinese spelling check (CSC) dataset called CSCD-NS, designed specifically for native Chinese speakers. Compared to existing CSC datasets aimed at Chinese learners, CSCD-NS is 10 times larger in scale and exhibits a distinct error distribution, with a significantly higher proportion of word-level errors.
To further enhance the data resource, the researchers propose a novel method that simulates the input process through an input method, generating large-scale and high-quality pseudo data that closely resembles the actual error distribution. This approach outperforms existing techniques for generating synthetic CSC data.
Moreover, the paper investigates the performance of various models on this CSC task, including large language models (LLMs) such as ChatGPT. The results indicate that generative models underperform BERT-like classification models due to strict length and pronunciation constraints.
The high prevalence of word-level errors in the CSCD-NS dataset also makes Chinese spelling correction for native speakers a challenging task, leaving substantial room for improvement. The researchers suggest that further research is needed to develop more effective models for this scenario.
Critical Analysis
The researchers have made a valuable contribution by creating a new, more representative dataset for Chinese spelling correction targeted at native speakers. The higher proportion of word-level errors in this dataset reflects the real-world challenges faced in this task, which is an important distinction from the error distributions seen in datasets for language learners.
The proposed method for generating high-quality synthetic data is a promising approach to further expand the data resource, though the researchers acknowledge that there is still room for improvement in matching the actual error distribution. It would be interesting to see how well this data generation technique performs on other language-specific spelling correction tasks.
The finding that generative models underperform classification models on this task raises interesting questions about the limitations of current LLMs, such as ChatGPT, in handling strict linguistic constraints. Further research could explore ways to make these generative models more robust to such requirements.
Overall, this paper provides a valuable new dataset and insights into the challenges of Chinese spelling correction for native speakers, which could help drive progress in this important area of natural language processing.
Conclusion
In this paper, the researchers present a new Chinese spelling check (CSC) dataset called CSCD-NS that is specifically designed for native Chinese speakers. CSCD-NS is significantly larger and exhibits a different error distribution, with more word-level errors, compared to existing CSC datasets aimed at language learners.
To further enhance the dataset, the researchers propose a novel data generation method that can create high-quality synthetic data closely matching the real-world error distribution. This approach outperforms previous techniques for generating simulated CSC data.
The paper also investigates the performance of various models, including large language models (LLMs) like ChatGPT, on this CSC task. The results show that generative models underperform BERT-like classification models due to strict length and pronunciation constraints.
Overall, the researchers have made an important contribution by providing a new, more representative dataset and shedding light on the challenges of Chinese spelling correction for native speakers. This work could help drive further progress in this area of natural language processing, with applications in text-dependent speaker verification and other language-specific tasks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
⛏️
0
CSCD-NS: a Chinese Spelling Check Dataset for Native Speakers
Yong Hu, Fandong Meng, Jie Zhou
In this paper, we present CSCD-NS, the first Chinese spelling check (CSC) dataset designed for native speakers, containing 40,000 samples from a Chinese social platform. Compared with existing CSC datasets aimed at Chinese learners, CSCD-NS is ten times larger in scale and exhibits a distinct error distribution, with a significantly higher proportion of word-level errors. To further enhance the data resource, we propose a novel method that simulates the input process through an input method, generating large-scale and high-quality pseudo data that closely resembles the actual error distribution and outperforms existing methods. Moreover, we investigate the performance of various models in this scenario, including large language models (LLMs), such as ChatGPT. The result indicates that generative models underperform BERT-like classification models due to strict length and pronunciation constraints. The high prevalence of word-level errors also makes CSC for native speakers challenging enough, leaving substantial room for improvement.
Read more5/24/2024
0
EdaCSC: Two Easy Data Augmentation Methods for Chinese Spelling Correction
Lei Sheng, Shuai-Shuai Xu
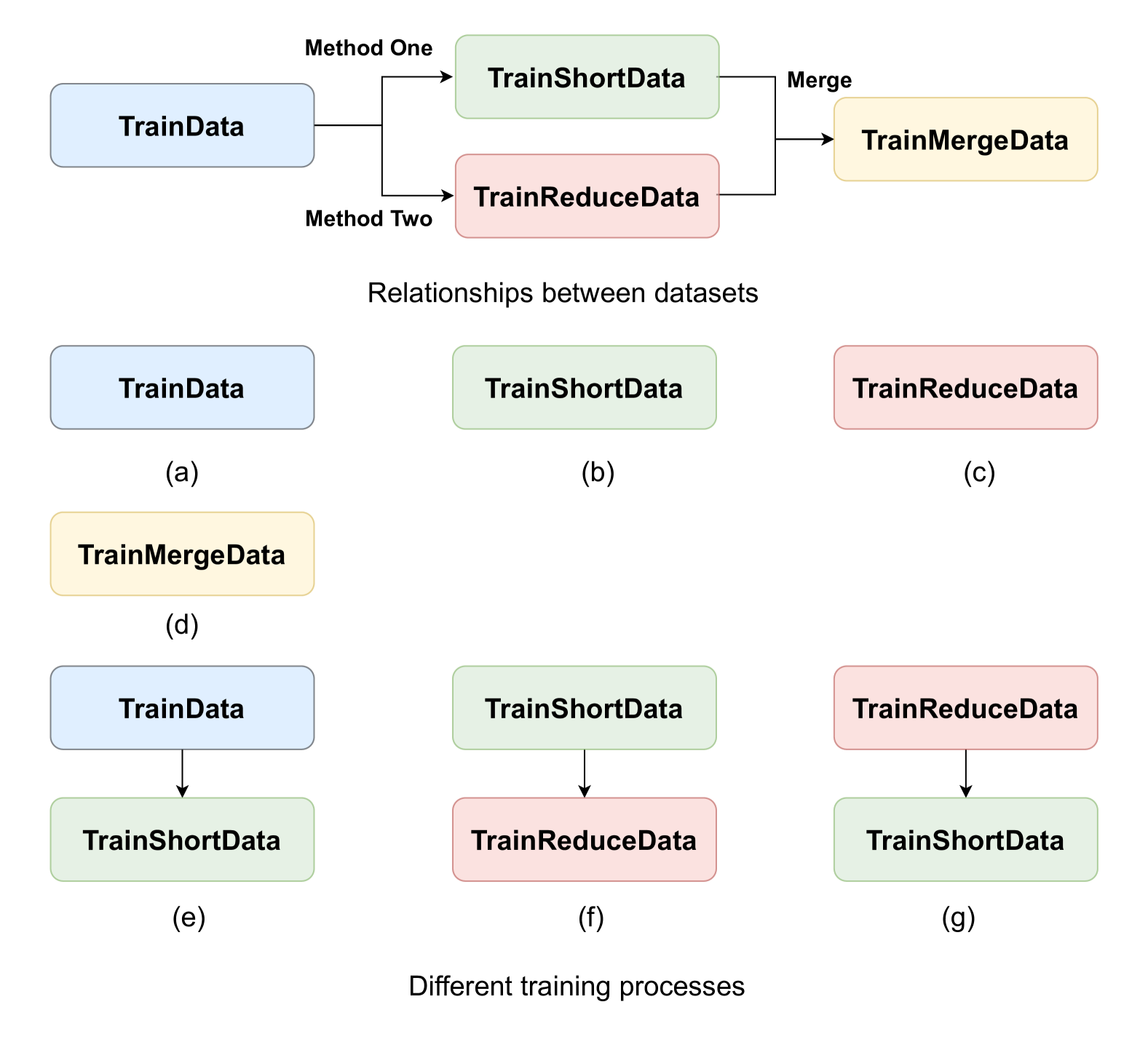
Chinese Spelling Correction (CSC) aims to detect and correct spelling errors in Chinese sentences caused by phonetic or visual similarities. While current CSC models integrate pinyin or glyph features and have shown significant progress,they still face challenges when dealing with sentences containing multiple typos and are susceptible to overcorrection in real-world scenarios. In contrast to existing model-centric approaches, we propose two data augmentation methods to address these limitations. Firstly, we augment the dataset by either splitting long sentences into shorter ones or reducing typos in sentences with multiple typos. Subsequently, we employ different training processes to select the optimal model. Experimental evaluations on the SIGHAN benchmarks demonstrate the superiority of our approach over most existing models, achieving state-of-the-art performance on the SIGHAN15 test set.
Read more9/10/2024

0
C-LLM: Learn to Check Chinese Spelling Errors Character by Character
Kunting Li, Yong Hu, Liang He, Fandong Meng, Jie Zhou
Chinese Spell Checking (CSC) aims to detect and correct spelling errors in sentences. Despite Large Language Models (LLMs) exhibit robust capabilities and are widely applied in various tasks, their performance on CSC is often unsatisfactory. We find that LLMs fail to meet the Chinese character-level constraints of the CSC task, namely equal length and phonetic similarity, leading to a performance bottleneck. Further analysis reveal that this issue stems from the granularity of tokenization, as current mixed character-word tokenization struggles to satisfy these character-level constraints. To address this issue, we propose C-LLM, a Large Language Model-based Chinese Spell Checking method that learns to check errors Character by Character. Character-level tokenization enables the model to learn character-level alignment, effectively mitigating issues related to character-level constraints. Furthermore, CSC is simplified to replication-dominated and substitution-supplemented tasks. Experiments on two CSC benchmarks demonstrate that C-LLM achieves an average improvement of 10% over existing methods. Specifically, it shows a 2.1% improvement in general scenarios and a significant 12% improvement in vertical domain scenarios, establishing state-of-the-art performance. The source code can be accessed at https://github.com/ktlKTL/C-LLM.
Read more6/26/2024

0
A Coin Has Two Sides: A Novel Detector-Corrector Framework for Chinese Spelling Correction
Xiangke Zeng, Zuchao Li, Lefei Zhang, Ping Wang, Hongqiu Wu, Hai Zhao
Chinese Spelling Correction (CSC) stands as a foundational Natural Language Processing (NLP) task, which primarily focuses on the correction of erroneous characters in Chinese texts. Certain existing methodologies opt to disentangle the error correction process, employing an additional error detector to pinpoint error positions. However, owing to the inherent performance limitations of error detector, precision and recall are like two sides of the coin which can not be both facing up simultaneously. Furthermore, it is also worth investigating how the error position information can be judiciously applied to assist the error correction. In this paper, we introduce a novel approach based on error detector-corrector framework. Our detector is designed to yield two error detection results, each characterized by high precision and recall. Given that the occurrence of errors is context-dependent and detection outcomes may be less precise, we incorporate the error detection results into the CSC task using an innovative feature fusion strategy and a selective masking strategy. Empirical experiments conducted on mainstream CSC datasets substantiate the efficacy of our proposed method.
Read more9/9/2024