On Bias and Fairness in NLP: Investigating the Impact of Bias and Debiasing in Language Models on the Fairness of Toxicity Detection
2305.12829
0
0
💬
Abstract
Language models are the new state-of-the-art natural language processing (NLP) models and they are being increasingly used in many NLP tasks. Even though there is evidence that language models are biased, the impact of that bias on the fairness of downstream NLP tasks is still understudied. Furthermore, despite that numerous debiasing methods have been proposed in the literature, the impact of bias removal methods on the fairness of NLP tasks is also understudied. In this work, we investigate three different sources of bias in NLP models, i.e. representation bias, selection bias and overamplification bias, and examine how they impact the fairness of the downstream task of toxicity detection. Moreover, we investigate the impact of removing these biases using different bias removal techniques on the fairness of toxicity detection. Results show strong evidence that downstream sources of bias, especially overamplification bias, are the most impactful types of bias on the fairness of the task of toxicity detection. We also found strong evidence that removing overamplification bias by fine-tuning the language models on a dataset with balanced contextual representations and ratios of positive examples between different identity groups can improve the fairness of the task of toxicity detection. Finally, we build on our findings and introduce a list of guidelines to ensure the fairness of the task of toxicity detection.
Create account to get full access
Overview
- This paper investigates the impact of different types of biases in language models on the fairness of downstream natural language processing (NLP) tasks, specifically the task of toxicity detection.
- The authors examine three sources of bias: representation bias, selection bias, and overamplification bias, and how they affect the fairness of toxicity detection.
- They also explore the impact of different bias removal techniques on the fairness of toxicity detection.
- The findings suggest that overamplification bias is the most impactful type of bias, and that removing this bias by fine-tuning language models on a balanced dataset can improve the fairness of toxicity detection.
Plain English Explanation
Language models, which are the latest advancements in natural language processing (NLP), are being used more and more in various NLP tasks. However, there is evidence that these language models can be biased, and the impact of this bias on the fairness of the tasks they are used for is not well understood.
The authors of this paper looked at three different types of bias in language models: representation bias, selection bias, and overamplification bias. They wanted to see how these different types of bias affect the fairness of a specific NLP task: toxicity detection.
Toxicity detection is the process of identifying whether a piece of text is considered "toxic" or offensive. The authors found that overamplification bias, which is when the model amplifies certain biases, was the most impactful type of bias on the fairness of toxicity detection.
To address this, the researchers tried different techniques to remove the biases from the language models. They discovered that fine-tuning the language models on a dataset with a balanced representation of different groups and an equal ratio of positive examples for each group can improve the fairness of the toxicity detection task.
Based on their findings, the authors provide a set of guidelines to help ensure the fairness of toxicity detection systems, which can be applied to other NLP tasks as well.
Technical Explanation
The paper investigates the impact of different types of biases in language models on the fairness of the downstream task of toxicity detection. The authors examine three sources of bias: representation bias, selection bias, and overamplification bias.
Representation bias refers to the unequal representation of different demographic groups in the training data used to develop the language models. Selection bias occurs when the data used to train the models is not representative of the real-world distribution of language use. Overamplification bias is when the model amplifies certain biases present in the training data.
The authors conducted experiments to evaluate the impact of these different biases on the fairness of toxicity detection, which is the task of identifying whether a piece of text is considered "toxic" or offensive. They measured fairness using various metrics, such as demographic parity and equal opportunity.
The results show that overamplification bias has the most significant impact on the fairness of toxicity detection, while representation bias and selection bias also play a role. The authors then explored the impact of different bias removal techniques on the fairness of toxicity detection.
They found that fine-tuning the language models on a dataset with balanced contextual representations and equal ratios of positive examples between different identity groups can improve the fairness of the toxicity detection task. This suggests that addressing overamplification bias is crucial for ensuring the fairness of NLP systems.
Critical Analysis
The paper provides a comprehensive investigation of the impact of different types of biases in language models on the fairness of downstream NLP tasks, specifically toxicity detection. The authors' use of multiple fairness metrics and their examination of various bias sources and removal techniques are strengths of the study.
However, the paper does not address the potential trade-offs between fairness and other performance metrics, such as accuracy or efficiency. It would be valuable to understand how bias removal techniques might affect the overall performance of the toxicity detection system.
Additionally, the paper focuses on a single NLP task (toxicity detection) and does not explore the generalizability of the findings to other tasks. It would be interesting to see if the impact of different biases and the effectiveness of bias removal techniques are consistent across a broader range of NLP applications.
Furthermore, the paper does not delve into the potential societal implications of biased toxicity detection systems, such as the impact on marginalized communities or the potential for unintended consequences. Exploring these aspects could provide a more holistic understanding of the importance of fairness in NLP systems.
Overall, the paper makes a valuable contribution to the understanding of bias in language models and its impact on the fairness of downstream tasks. The guidelines provided for ensuring fairness in toxicity detection can serve as a useful starting point for practitioners and researchers working in this area.
Conclusion
This paper investigates the impact of different types of biases in language models on the fairness of the downstream task of toxicity detection. The authors examine representation bias, selection bias, and overamplification bias, and find that overamplification bias has the most significant impact on the fairness of toxicity detection.
The researchers also explore the effectiveness of different bias removal techniques and demonstrate that fine-tuning language models on a balanced dataset can improve the fairness of toxicity detection. These findings highlight the importance of addressing bias in language models to ensure the fairness of NLP systems, which can have important societal implications.
The paper provides a set of guidelines for ensuring the fairness of toxicity detection systems, which can be applied to other NLP tasks as well. This research contributes to the growing body of work on fairness in artificial intelligence and underscores the need for continued efforts to develop fair and equitable NLP systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🌿
Disentangling Dialect from Social Bias via Multitask Learning to Improve Fairness
Maximilian Spliethover, Sai Nikhil Menon, Henning Wachsmuth
0
0
Dialects introduce syntactic and lexical variations in language that occur in regional or social groups. Most NLP methods are not sensitive to such variations. This may lead to unfair behavior of the methods, conveying negative bias towards dialect speakers. While previous work has studied dialect-related fairness for aspects like hate speech, other aspects of biased language, such as lewdness, remain fully unexplored. To fill this gap, we investigate performance disparities between dialects in the detection of five aspects of biased language and how to mitigate them. To alleviate bias, we present a multitask learning approach that models dialect language as an auxiliary task to incorporate syntactic and lexical variations. In our experiments with African-American English dialect, we provide empirical evidence that complementing common learning approaches with dialect modeling improves their fairness. Furthermore, the results suggest that multitask learning achieves state-of-the-art performance and helps to detect properties of biased language more reliably.
6/17/2024
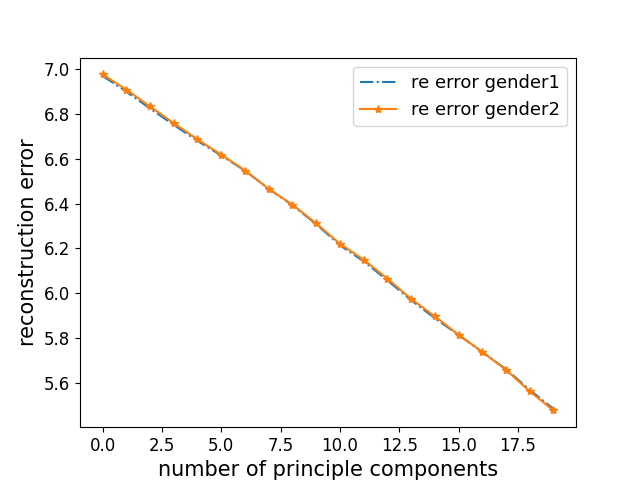
Closing the Gap in the Trade-off between Fair Representations and Accuracy
Biswajit Rout, Ananya B. Sai, Arun Rajkumar
0
0
The rapid developments of various machine learning models and their deployments in several applications has led to discussions around the importance of looking beyond the accuracies of these models. Fairness of such models is one such aspect that is deservedly gaining more attention. In this work, we analyse the natural language representations of documents and sentences (i.e., encodings) for any embedding-level bias that could potentially also affect the fairness of the downstream tasks that rely on them. We identify bias in these encodings either towards or against different sub-groups based on the difference in their reconstruction errors along various subsets of principal components. We explore and recommend ways to mitigate such bias in the encodings while also maintaining a decent accuracy in classification models that use them.
4/16/2024
🔍
Debiasing Algorithm through Model Adaptation
Tomasz Limisiewicz, David Marev{c}ek, Tom'av{s} Musil
0
0
Large language models are becoming the go-to solution for the ever-growing number of tasks. However, with growing capacity, models are prone to rely on spurious correlations stemming from biases and stereotypes present in the training data. This work proposes a novel method for detecting and mitigating gender bias in language models. We perform causal analysis to identify problematic model components and discover that mid-upper feed-forward layers are most prone to convey bias. Based on the analysis results, we intervene in the model by applying a linear projection to the weight matrices of these layers. Our titular method, DAMA, significantly decreases bias as measured by diverse metrics while maintaining the model's performance on downstream tasks. We release code for our method and models, which retrain LLaMA's state-of-the-art performance while being significantly less biased.
5/30/2024
🏷️
Fairness and Bias in Multimodal AI: A Survey
Tosin Adewumi, Lama Alkhaled, Namrata Gurung, Goya van Boven, Irene Pagliai
0
0
The importance of addressing fairness and bias in artificial intelligence (AI) systems cannot be over-emphasized. Mainstream media has been awashed with news of incidents around stereotypes and bias in many of these systems in recent years. In this survey, we fill a gap with regards to the minimal study of fairness and bias in Large Multimodal Models (LMMs) compared to Large Language Models (LLMs), providing 50 examples of datasets and models along with the challenges affecting them; we identify a new category of quantifying bias (preuse), in addition to the two well-known ones in the literature: intrinsic and extrinsic; we critically discuss the various ways researchers are addressing these challenges. Our method involved two slightly different search queries on Google Scholar, which revealed that 33,400 and 538,000 links are the results for the terms Fairness and bias in Large Multimodal Models and Fairness and bias in Large Language Models, respectively. We believe this work contributes to filling this gap and providing insight to researchers and other stakeholders on ways to address the challenge of fairness and bias in multimodal A!.
6/28/2024