From Prejudice to Parity: A New Approach to Debiasing Large Language Model Word Embeddings
2402.11512
0
0
💬
Abstract
Embeddings play a pivotal role in the efficacy of Large Language Models. They are the bedrock on which these models grasp contextual relationships and foster a more nuanced understanding of language and consequently perform remarkably on a plethora of complex tasks that require a fundamental understanding of human language. Given that these embeddings themselves often reflect or exhibit bias, it stands to reason that these models may also inadvertently learn this bias. In this work, we build on the seminal previous work and propose DeepSoftDebias, an algorithm that uses a neural network to perform 'soft debiasing'. We exhaustively evaluate this algorithm across a variety of SOTA datasets, accuracy metrics, and challenging NLP tasks. We find that DeepSoftDebias outperforms the current state-of-the-art methods at reducing bias across gender, race, and religion.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Embeddings are the foundation of large language models, shaping their understanding of language and enabling them to excel at complex tasks.
- However, these embeddings can also reflect or exhibit biases, which may then be inadvertently learned by the language models.
- The paper proposes an algorithm called DeepSoftDebias that uses a neural network to perform 'soft debiasing' of embeddings, reducing bias across gender, race, and religion.
- The algorithm is extensively evaluated on various state-of-the-art datasets and tasks, demonstrating its effectiveness in outperforming current debiasing methods.
Plain English Explanation
Embeddings are the building blocks of large language models, such as GPT-3 and BERT. These models use embeddings to understand the relationships between words and how they are used in context. This allows the models to perform remarkably well on a wide range of language-related tasks, from answering questions to summarizing text.
However, the embeddings themselves can sometimes reflect or exhibit biases, such as gender, race, or religious biases. This means the language models may also inadvertently learn these biases, which can lead to unfair or inaccurate outputs.
To address this issue, the researchers developed an algorithm called DeepSoftDebias. This algorithm uses a neural network to "softly" debias the embeddings, reducing the biases without completely removing valuable information. The researchers extensively tested DeepSoftDebias on various datasets and tasks, and found that it outperforms current state-of-the-art debiasing methods.
Technical Explanation
The paper builds on previous work on debiasing embeddings and proposes an algorithm called DeepSoftDebias. This algorithm uses a neural network to perform "soft debiasing" of the embeddings, which means it reduces the biases without completely removing useful information.
The researchers first trained a neural network to predict the sensitive attributes (e.g., gender, race, religion) from the input embeddings. This network learns to capture the biases present in the embeddings. Then, the researchers used this network to "debias" the embeddings by subtracting the predicted sensitive attributes from the original embeddings.
The key idea behind this approach is that the debiased embeddings should retain the essential information for the downstream tasks while reducing the biases. The researchers extensively evaluated DeepSoftDebias on various state-of-the-art datasets and challenging NLP tasks, and found that it outperformed current debiasing methods in reducing bias across gender, race, and religion.
Critical Analysis
The paper presents a well-designed and comprehensive evaluation of the DeepSoftDebias algorithm. The researchers have carefully considered various state-of-the-art datasets and tasks, which strengthens the credibility of their findings.
However, the paper does not explicitly discuss the potential limitations or caveats of the proposed approach. For example, it would be helpful to understand how the algorithm might perform on more complex or subtle forms of bias, or how it scales to larger language models.
Additionally, the paper does not address the potential ethical implications of deploying such debiasing algorithms in real-world applications. While reducing bias is a laudable goal, there may be unintended consequences or trade-offs that should be carefully considered.
Overall, the paper presents a valuable contribution to the field of bias mitigation in large language models. However, further research and discussion are needed to fully understand the limitations and broader implications of the DeepSoftDebias approach.
Conclusion
This paper proposes an effective algorithm, DeepSoftDebias, for reducing biases in the embeddings that underpin large language models. By using a neural network to perform "soft debiasing," the algorithm is able to retain the essential information in the embeddings while significantly reducing biases across gender, race, and religion.
The researchers have provided a thorough and rigorous evaluation of their approach, demonstrating its superiority over current state-of-the-art debiasing methods. This work represents an important step forward in addressing the issue of bias in large language models, which is crucial for ensuring these powerful tools are used fairly and responsibly.
While the paper does not delve into the potential limitations or ethical considerations, it lays the groundwork for further research and development in this critical area of machine learning. As large language models continue to advance and be deployed in diverse applications, the need for effective debiasing techniques will only become more pressing.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
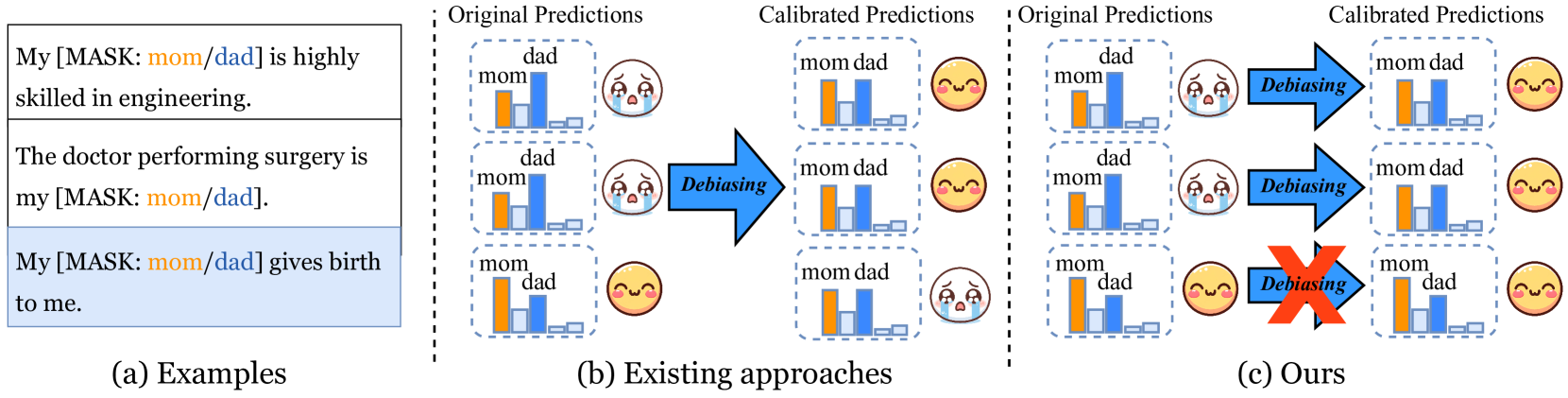
Large Language Model Bias Mitigation from the Perspective of Knowledge Editing
Ruizhe Chen, Yichen Li, Zikai Xiao, Zuozhu Liu
0
0
Existing debiasing methods inevitably make unreasonable or undesired predictions as they are designated and evaluated to achieve parity across different social groups but leave aside individual facts, resulting in modified existing knowledge. In this paper, we first establish a new bias mitigation benchmark BiasKE leveraging existing and additional constructed datasets, which systematically assesses debiasing performance by complementary metrics on fairness, specificity, and generalization. Meanwhile, we propose a novel debiasing method, Fairness Stamp (FAST), which enables editable fairness through fine-grained calibration on individual biased knowledge. Comprehensive experiments demonstrate that FAST surpasses state-of-the-art baselines with remarkable debiasing performance while not hampering overall model capability for knowledge preservation, highlighting the prospect of fine-grained debiasing strategies for editable fairness in LLMs.
5/16/2024
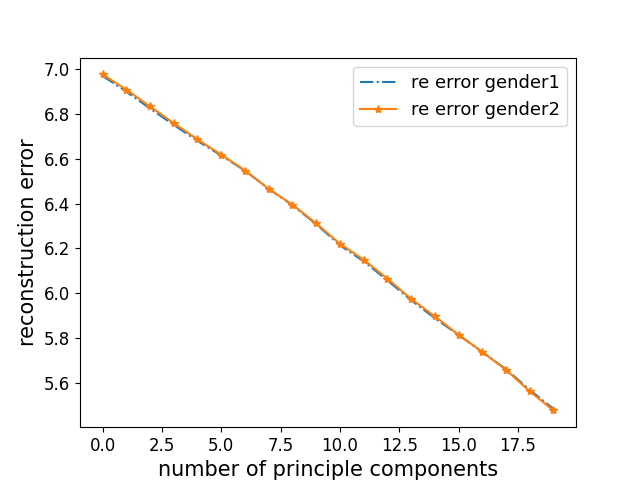
Closing the Gap in the Trade-off between Fair Representations and Accuracy
Biswajit Rout, Ananya B. Sai, Arun Rajkumar
0
0
The rapid developments of various machine learning models and their deployments in several applications has led to discussions around the importance of looking beyond the accuracies of these models. Fairness of such models is one such aspect that is deservedly gaining more attention. In this work, we analyse the natural language representations of documents and sentences (i.e., encodings) for any embedding-level bias that could potentially also affect the fairness of the downstream tasks that rely on them. We identify bias in these encodings either towards or against different sub-groups based on the difference in their reconstruction errors along various subsets of principal components. We explore and recommend ways to mitigate such bias in the encodings while also maintaining a decent accuracy in classification models that use them.
4/16/2024
💬
On Bias and Fairness in NLP: Investigating the Impact of Bias and Debiasing in Language Models on the Fairness of Toxicity Detection
Fatma Elsafoury, Stamos Katsigiannis
0
0
Language models are the new state-of-the-art natural language processing (NLP) models and they are being increasingly used in many NLP tasks. Even though there is evidence that language models are biased, the impact of that bias on the fairness of downstream NLP tasks is still understudied. Furthermore, despite that numerous debiasing methods have been proposed in the literature, the impact of bias removal methods on the fairness of NLP tasks is also understudied. In this work, we investigate three different sources of bias in NLP models, i.e. representation bias, selection bias and overamplification bias, and examine how they impact the fairness of the downstream task of toxicity detection. Moreover, we investigate the impact of removing these biases using different bias removal techniques on the fairness of toxicity detection. Results show strong evidence that downstream sources of bias, especially overamplification bias, are the most impactful types of bias on the fairness of the task of toxicity detection. We also found strong evidence that removing overamplification bias by fine-tuning the language models on a dataset with balanced contextual representations and ratios of positive examples between different identity groups can improve the fairness of the task of toxicity detection. Finally, we build on our findings and introduce a list of guidelines to ensure the fairness of the task of toxicity detection.
4/29/2024

IndiBias: A Benchmark Dataset to Measure Social Biases in Language Models for Indian Context
Nihar Ranjan Sahoo, Pranamya Prashant Kulkarni, Narjis Asad, Arif Ahmad, Tanu Goyal, Aparna Garimella, Pushpak Bhattacharyya
0
0
The pervasive influence of social biases in language data has sparked the need for benchmark datasets that capture and evaluate these biases in Large Language Models (LLMs). Existing efforts predominantly focus on English language and the Western context, leaving a void for a reliable dataset that encapsulates India's unique socio-cultural nuances. To bridge this gap, we introduce IndiBias, a comprehensive benchmarking dataset designed specifically for evaluating social biases in the Indian context. We filter and translate the existing CrowS-Pairs dataset to create a benchmark dataset suited to the Indian context in Hindi language. Additionally, we leverage LLMs including ChatGPT and InstructGPT to augment our dataset with diverse societal biases and stereotypes prevalent in India. The included bias dimensions encompass gender, religion, caste, age, region, physical appearance, and occupation. We also build a resource to address intersectional biases along three intersectional dimensions. Our dataset contains 800 sentence pairs and 300 tuples for bias measurement across different demographics. The dataset is available in English and Hindi, providing a size comparable to existing benchmark datasets. Furthermore, using IndiBias we compare ten different language models on multiple bias measurement metrics. We observed that the language models exhibit more bias across a majority of the intersectional groups.
4/4/2024