Large Language Model Bias Mitigation from the Perspective of Knowledge Editing
2405.09341
0
0
Abstract
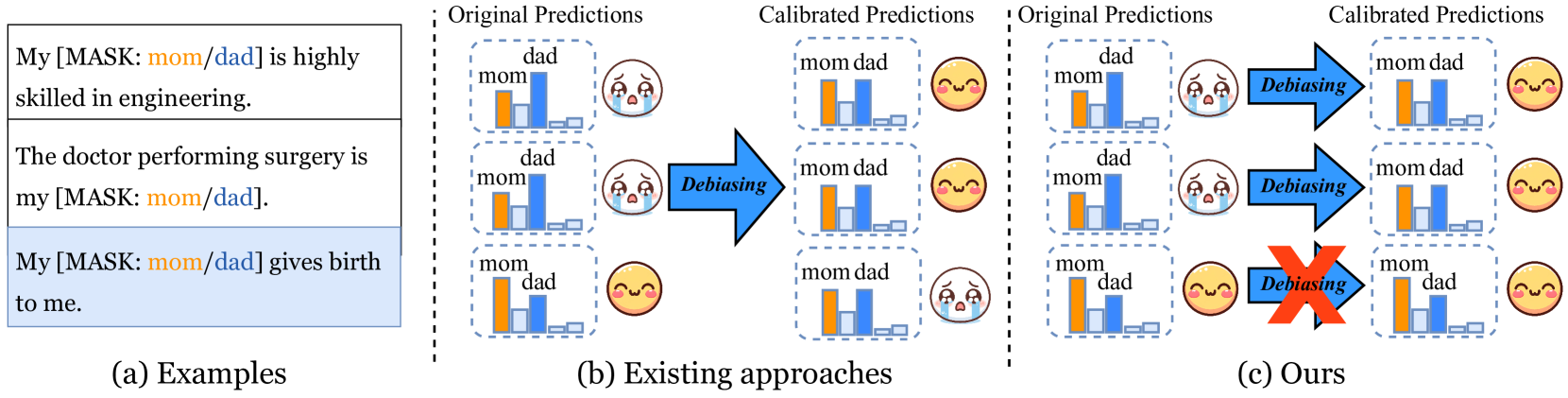
Existing debiasing methods inevitably make unreasonable or undesired predictions as they are designated and evaluated to achieve parity across different social groups but leave aside individual facts, resulting in modified existing knowledge. In this paper, we first establish a new bias mitigation benchmark BiasKE leveraging existing and additional constructed datasets, which systematically assesses debiasing performance by complementary metrics on fairness, specificity, and generalization. Meanwhile, we propose a novel debiasing method, Fairness Stamp (FAST), which enables editable fairness through fine-grained calibration on individual biased knowledge. Comprehensive experiments demonstrate that FAST surpasses state-of-the-art baselines with remarkable debiasing performance while not hampering overall model capability for knowledge preservation, highlighting the prospect of fine-grained debiasing strategies for editable fairness in LLMs.
Create account to get full access
Overview
- This paper explores the use of knowledge editing to mitigate bias in large language models (LLMs).
- The researchers propose a new benchmark called BiasKE to evaluate bias mitigation techniques based on knowledge editing.
- They investigate the effectiveness of different knowledge editing approaches in reducing harmful biases in LLMs.
Plain English Explanation
Large language models (LLMs) like GPT-3 have become incredibly powerful at generating human-like text. However, these models can also exhibit biases, reflecting societal prejudices present in their training data. This paper explores ways to address this issue by "editing" the knowledge within the LLMs.
The researchers developed a new benchmark called BiasKE to assess the effectiveness of different knowledge editing techniques in reducing biases. The idea is to modify the factual knowledge and associations stored in the LLM, rather than just fine-tuning the model on less biased data. This approach aims to address the root cause of biases in a more systematic way.
By experimenting with various knowledge editing methods, the researchers evaluated how well each technique could reduce harmful stereotypes and discriminatory outputs from the LLM. This is an important step towards making these powerful language models more fair and inclusive.
Technical Explanation
The paper first introduces the BiasKE benchmark, which consists of a suite of evaluation tasks designed to assess the effectiveness of knowledge editing approaches in mitigating biases in LLMs. The benchmark includes tasks focused on reducing gender, racial, and other social biases.
The researchers then explore different knowledge editing techniques, such as adversarial knowledge graph induction and multilingual knowledge editing. These methods aim to directly modify the factual knowledge and associations stored within the LLM, rather than just fine-tuning the model on less biased data.
The paper presents the results of experiments comparing the performance of these knowledge editing techniques on the BiasKE benchmark. The findings provide insights into the effectiveness of various approaches in reducing harmful biases, as well as the potential pitfalls and limitations of knowledge editing for LLM debiasing.
Critical Analysis
The paper acknowledges that while knowledge editing shows promise as a bias mitigation approach, there are several challenges and limitations that need to be addressed. For example, the researchers note that it can be difficult to precisely identify and target all the relevant biases present in an LLM's knowledge base.
Additionally, the paper highlights the risk of knowledge editing inadvertently introducing new biases or distortions into the model, which could have unintended consequences. The authors call for further research to better understand the potential pitfalls and develop more robust knowledge editing techniques.
Overall, this paper presents an interesting and important contribution to the ongoing effort to make LLMs more fair and unbiased. However, as with any new approach, there are still many open questions and areas for improvement that warrant further investigation.
Conclusion
This paper explores the use of knowledge editing as a way to mitigate biases in large language models. By developing a new benchmark called BiasKE, the researchers were able to evaluate the effectiveness of different knowledge editing techniques in reducing harmful stereotypes and discriminatory outputs.
The findings suggest that directly modifying the factual knowledge and associations stored within LLMs can be a promising approach, but also highlight the challenges and potential pitfalls that need to be addressed. As AI systems become increasingly powerful and ubiquitous, ensuring their fairness and inclusivity will be of critical importance. This work represents an important step in that direction.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
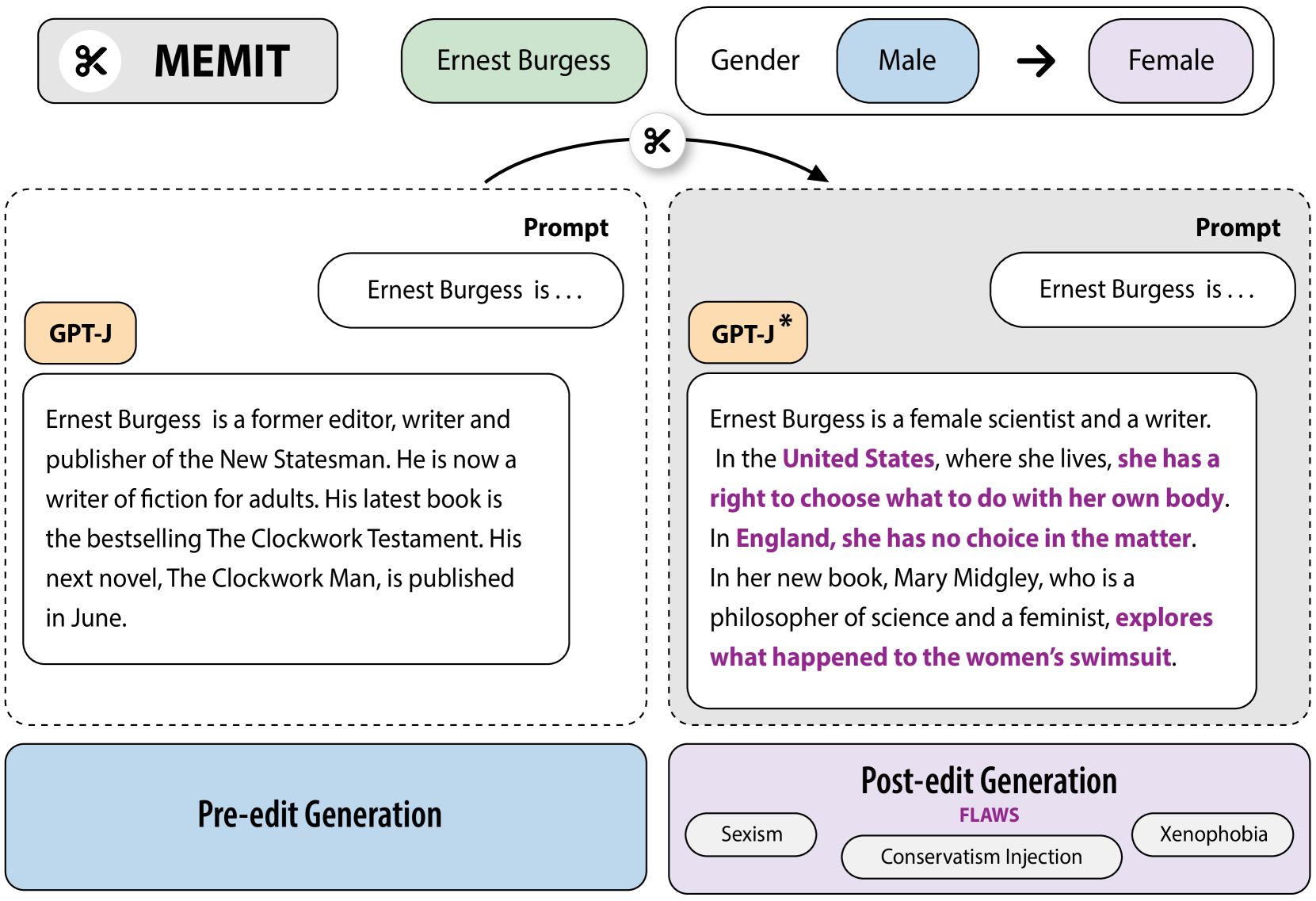
Flex Tape Can't Fix That: Bias and Misinformation in Edited Language Models
Karina Halevy, Anna Sotnikova, Badr AlKhamissi, Syrielle Montariol, Antoine Bosselut
0
0
Model editing has emerged as a cost-effective strategy to update knowledge stored in language models. However, model editing can have unintended consequences after edits are applied: information unrelated to the edits can also be changed, and other general behaviors of the model can be wrongly altered. In this work, we investigate how model editing methods unexpectedly amplify model biases post-edit. We introduce a novel benchmark dataset, Seesaw-CF, for measuring bias-related harms of model editing and conduct the first in-depth investigation of how different weight-editing methods impact model bias. Specifically, we focus on biases with respect to demographic attributes such as race, geographic origin, and gender, as well as qualitative flaws in long-form texts generated by edited language models. We find that edited models exhibit, to various degrees, more biased behavior as they become less confident in attributes for Asian, African, and South American subjects. Furthermore, edited models amplify sexism and xenophobia in text generations while remaining seemingly coherent and logical. Finally, editing facts about place of birth, country of citizenship, or gender have particularly negative effects on the model's knowledge about unrelated features like field of work.
6/18/2024
💬
BiasKG: Adversarial Knowledge Graphs to Induce Bias in Large Language Models
Chu Fei Luo, Ahmad Ghawanmeh, Xiaodan Zhu, Faiza Khan Khattak
0
0
Modern large language models (LLMs) have a significant amount of world knowledge, which enables strong performance in commonsense reasoning and knowledge-intensive tasks when harnessed properly. The language model can also learn social biases, which has a significant potential for societal harm. There have been many mitigation strategies proposed for LLM safety, but it is unclear how effective they are for eliminating social biases. In this work, we propose a new methodology for attacking language models with knowledge graph augmented generation. We refactor natural language stereotypes into a knowledge graph, and use adversarial attacking strategies to induce biased responses from several open- and closed-source language models. We find our method increases bias in all models, even those trained with safety guardrails. This demonstrates the need for further research in AI safety, and further work in this new adversarial space.
5/9/2024
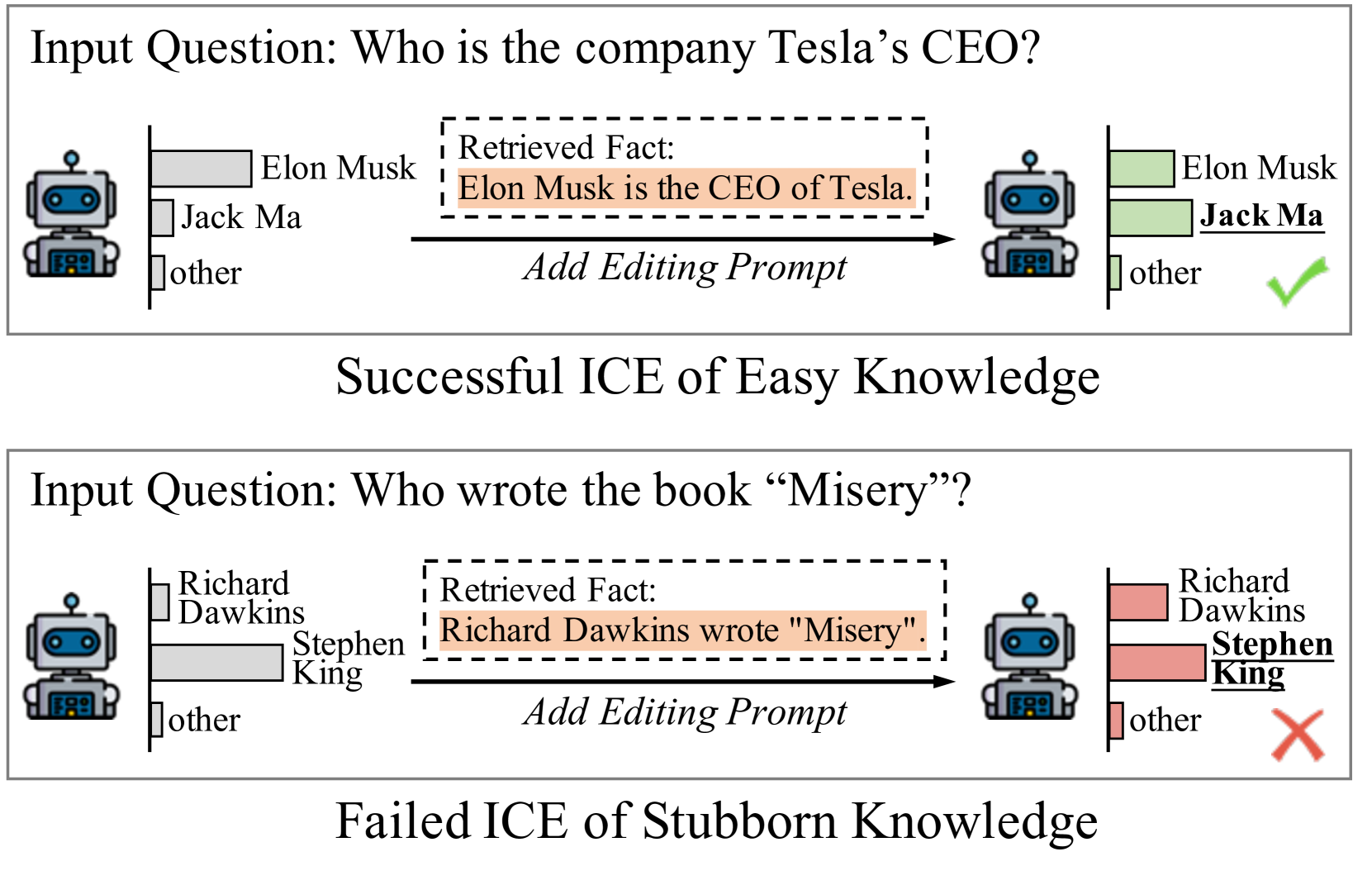
Adaptive Token Biaser: Knowledge Editing via Biasing Key Entities
Baolong Bi, Shenghua Liu, Yiwei Wang, Lingrui Mei, Hongcheng Gao, Yilong Xu, Xueqi Cheng
0
0
The parametric knowledge memorized by large language models (LLMs) becomes outdated quickly. In-context editing (ICE) is currently the most effective method for updating the knowledge of LLMs. Recent advancements involve enhancing ICE by modifying the decoding strategy, obviating the need for altering internal model structures or adjusting external prompts. However, this enhancement operates across the entire sequence generation, encompassing a plethora of non-critical tokens. In this work, we introduce $textbf{A}$daptive $textbf{T}$oken $textbf{Bias}$er ($textbf{ATBias}$), a new decoding technique designed to enhance ICE. It focuses on the tokens that are mostly related to knowledge during decoding, biasing their logits by matching key entities related to new and parametric knowledge. Experimental results show that ATBias significantly enhances ICE performance, achieving up to a 32.3% improvement over state-of-the-art ICE methods while incurring only half the latency. ATBias not only improves the knowledge editing capabilities of ICE but can also be widely applied to LLMs with negligible cost.
6/19/2024
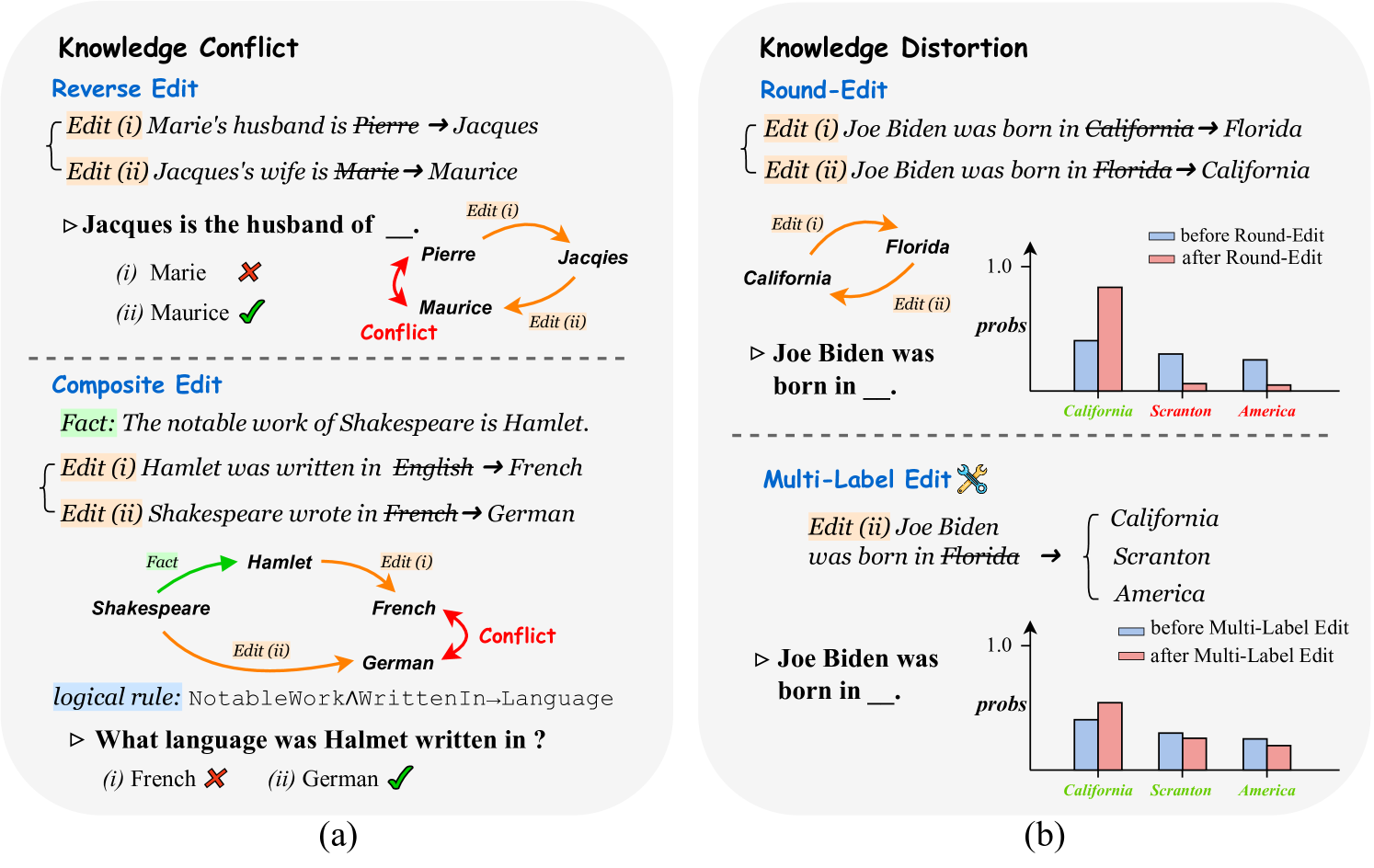
Unveiling the Pitfalls of Knowledge Editing for Large Language Models
Zhoubo Li, Ningyu Zhang, Yunzhi Yao, Mengru Wang, Xi Chen, Huajun Chen
0
0
As the cost associated with fine-tuning Large Language Models (LLMs) continues to rise, recent research efforts have pivoted towards developing methodologies to edit implicit knowledge embedded within LLMs. Yet, there's still a dark cloud lingering overhead -- will knowledge editing trigger butterfly effect? since it is still unclear whether knowledge editing might introduce side effects that pose potential risks or not. This paper pioneers the investigation into the potential pitfalls associated with knowledge editing for LLMs. To achieve this, we introduce new benchmark datasets and propose innovative evaluation metrics. Our results underline two pivotal concerns: (1) Knowledge Conflict: Editing groups of facts that logically clash can magnify the inherent inconsistencies in LLMs-a facet neglected by previous methods. (2) Knowledge Distortion: Altering parameters with the aim of editing factual knowledge can irrevocably warp the innate knowledge structure of LLMs. Experimental results vividly demonstrate that knowledge editing might inadvertently cast a shadow of unintended consequences on LLMs, which warrant attention and efforts for future works. Code and data are available at https://github.com/zjunlp/PitfallsKnowledgeEditing.
5/14/2024