BigCodeBench: Benchmarking Code Generation with Diverse Function Calls and Complex Instructions

0
Sign in to get full access
Overview
- This paper introduces BigCodeBench, a new benchmark for evaluating the performance of code generation models.
- BigCodeBench aims to assess the ability of models to generate diverse function calls and handle complex instructions, which are important for real-world code generation tasks.
- The benchmark includes a diverse set of functions and programming constructs, as well as a focus on evaluating the generated code's correctness and efficiency.
Plain English Explanation
The researchers created a new benchmark called BigCodeBench to test how well code generation models can perform. Code generation models are AI systems that can write code, and the researchers wanted to see how they handle more complex and realistic coding tasks.
Existing benchmarks for code generation mostly focus on simple, easy-to-generate code. But in the real world, code needs to be able to handle a wide variety of functions and programming concepts. BigCodeBench tries to capture this complexity by including a diverse set of functions and coding constructs that models need to be able to understand and generate correctly.
The goal is to get a more realistic assessment of how capable current code generation models are. The researchers want to push the boundaries of what these models can do and identify areas where they still struggle. This will help guide future research and development to make code generation AI systems more robust and effective.
Technical Explanation
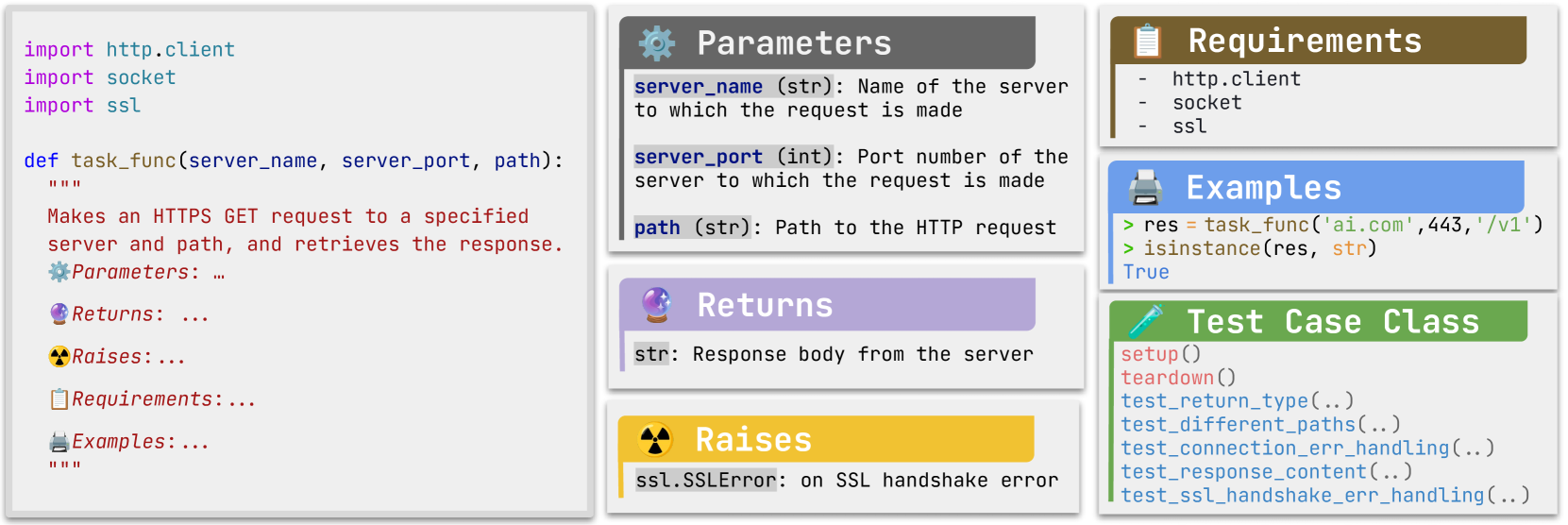
The paper introduces BigCodeBench, a new benchmark for evaluating code generation models. Unlike existing benchmarks that focus on simple code generation tasks, BigCodeBench aims to assess a model's ability to handle a diverse set of function calls and complex programming instructions.
The benchmark includes a wide range of functions, control flow structures, and data types, covering a broad spectrum of programming concepts. This is designed to better reflect the demands of real-world code generation. The researchers also place a strong emphasis on evaluating the correctness and efficiency of the generated code, not just its fluency.
By using BigCodeBench, the researchers hope to gain deeper insights into the capabilities and limitations of current code generation models. This aligns with a growing body of work examining the benchmarks, metrics, and evaluations used for code generation and striving to develop more rigorous and comprehensive assessments of these models' performance.
Critical Analysis
The researchers acknowledge that BigCodeBench does not cover every possible aspect of code generation, and there is still room for further expansion and refinement of the benchmark. For example, the paper notes that the current version does not evaluate a model's ability to handle errors or edge cases in the generated code.
Additionally, while the benchmark emphasizes correctness and efficiency, it may not fully capture other important factors, such as the code's readability, maintainability, or alignment with programming best practices. Assessing these higher-level qualities remains an area for future research.
Nevertheless, BigCodeBench represents a significant step forward in comprehensive benchmarking of large language models for code generation. By challenging models with a diverse set of coding tasks, the benchmark can help identify the strengths and weaknesses of current approaches, guiding future advancements in the field.
Conclusion
The BigCodeBench benchmark introduces a more comprehensive and challenging assessment of code generation models. By focusing on diverse function calls and complex instructions, the benchmark aims to provide a more realistic evaluation of a model's capabilities, moving beyond simple code generation tasks.
The insights gained from using BigCodeBench can help steer future research and development in the field of code generation, ultimately leading to more robust and effective AI systems that can assist and empower human programmers. As the capabilities of these models continue to evolve, benchmarks like BigCodeBench will play a crucial role in ensuring their real-world applicability and impact.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
BigCodeBench: Benchmarking Code Generation with Diverse Function Calls and Complex Instructions
Terry Yue Zhuo, Minh Chien Vu, Jenny Chim, Han Hu, Wenhao Yu, Ratnadira Widyasari, Imam Nur Bani Yusuf, Haolan Zhan, Junda He, Indraneil Paul, Simon Brunner, Chen Gong, Thong Hoang, Armel Randy Zebaze, Xiaoheng Hong, Wen-Ding Li, Jean Kaddour, Ming Xu, Zhihan Zhang, Prateek Yadav, Naman Jain, Alex Gu, Zhoujun Cheng, Jiawei Liu, Qian Liu, Zijian Wang, David Lo, Binyuan Hui, Niklas Muennighoff, Daniel Fried, Xiaoning Du, Harm de Vries, Leandro Von Werra
Automated software engineering has been greatly empowered by the recent advances in Large Language Models (LLMs) for programming. While current benchmarks have shown that LLMs can perform various software engineering tasks like human developers, the majority of their evaluations are limited to short and self-contained algorithmic tasks. Solving challenging and practical programming tasks requires the capability of utilizing diverse function calls as tools to efficiently implement functionalities like data analysis and web development. In addition, using multiple tools to solve a task needs compositional reasoning by accurately understanding complex instructions. Fulfilling both of these characteristics can pose a great challenge for LLMs. To assess how well LLMs can solve challenging and practical programming tasks, we introduce Bench, a benchmark that challenges LLMs to invoke multiple function calls as tools from 139 libraries and 7 domains for 1,140 fine-grained programming tasks. To evaluate LLMs rigorously, each programming task encompasses 5.6 test cases with an average branch coverage of 99%. In addition, we propose a natural-language-oriented variant of Bench, Benchi, that automatically transforms the original docstrings into short instructions only with essential information. Our extensive evaluation of 60 LLMs shows that LLMs are not yet capable of following complex instructions to use function calls precisely, with scores up to 60%, significantly lower than the human performance of 97%. The results underscore the need for further advancements in this area.
Read more6/27/2024
🛸
0
CodeBenchGen: Creating Scalable Execution-based Code Generation Benchmarks
Yiqing Xie, Alex Xie, Divyanshu Sheth, Pengfei Liu, Daniel Fried, Carolyn Rose
To facilitate evaluation of code generation systems across diverse scenarios, we present CodeBenchGen, a framework to create scalable execution-based benchmarks that only requires light guidance from humans. Specifically, we leverage a large language model (LLM) to convert an arbitrary piece of code into an evaluation example, including test cases for execution-based evaluation. We illustrate the usefulness of our framework by creating a dataset, Exec-CSN, which includes 1,931 examples involving 293 libraries revised from code in 367 GitHub repositories taken from the CodeSearchNet dataset. To demonstrate the complexity and solvability of examples in Exec-CSN, we present a human study demonstrating that 81.3% of the examples can be solved by humans and 61% are rated as requires effort to solve. We conduct code generation experiments on open-source and proprietary models and analyze the performance of both humans and models. We provide the code at https://github.com/Veronicium/CodeBenchGen.
Read more5/9/2024
1
LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code
Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Armando Solar-Lezama, Koushik Sen, Ion Stoica
Large Language Models (LLMs) applied to code-related applications have emerged as a prominent field, attracting significant interest from both academia and industry. However, as new and improved LLMs are developed, existing evaluation benchmarks (e.g., HumanEval, MBPP) are no longer sufficient for assessing their capabilities. In this work, we propose LiveCodeBench, a comprehensive and contamination-free evaluation of LLMs for code, which continuously collects new problems over time from contests across three competition platforms, namely LeetCode, AtCoder, and CodeForces. Notably, our benchmark also focuses on a broader range of code related capabilities, such as self-repair, code execution, and test output prediction, beyond just code generation. Currently, LiveCodeBench hosts four hundred high-quality coding problems that were published between May 2023 and May 2024. We have evaluated 18 base LLMs and 34 instruction-tuned LLMs on LiveCodeBench. We present empirical findings on contamination, holistic performance comparisons, potential overfitting in existing benchmarks as well as individual model comparisons. We will release all prompts and model completions for further community analysis, along with a general toolkit for adding new scenarios and model
Read more6/7/2024
🎲
0
Benchmarks and Metrics for Evaluations of Code Generation: A Critical Review
Debalina Ghosh Paul, Hong Zhu, Ian Bayley
With the rapid development of Large Language Models (LLMs), a large number of machine learning models have been developed to assist programming tasks including the generation of program code from natural language input. However, how to evaluate such LLMs for this task is still an open problem despite of the great amount of research efforts that have been made and reported to evaluate and compare them. This paper provides a critical review of the existing work on the testing and evaluation of these tools with a focus on two key aspects: the benchmarks and the metrics used in the evaluations. Based on the review, further research directions are discussed.
Read more6/19/2024