Vim4Path: Self-Supervised Vision Mamba for Histopathology Images
2404.13222
0
0
Abstract
Representation learning from Gigapixel Whole Slide Images (WSI) poses a significant challenge in computational pathology due to the complicated nature of tissue structures and the scarcity of labeled data. Multi-instance learning methods have addressed this challenge, leveraging image patches to classify slides utilizing pretrained models using Self-Supervised Learning (SSL) approaches. The performance of both SSL and MIL methods relies on the architecture of the feature encoder. This paper proposes leveraging the Vision Mamba (Vim) architecture, inspired by state space models, within the DINO framework for representation learning in computational pathology. We evaluate the performance of Vim against Vision Transformers (ViT) on the Camelyon16 dataset for both patch-level and slide-level classification. Our findings highlight Vim's enhanced performance compared to ViT, particularly at smaller scales, where Vim achieves an 8.21 increase in ROC AUC for models of similar size. An explainability analysis further highlights Vim's capabilities, which reveals that Vim uniquely emulates the pathologist workflow-unlike ViT. This alignment with human expert analysis highlights Vim's potential in practical diagnostic settings and contributes significantly to developing effective representation-learning algorithms in computational pathology. We release the codes and pretrained weights at url{https://github.com/AtlasAnalyticsLab/Vim4Path}.
Create account to get full access
Overview
- This paper introduces Vim4Path, a self-supervised vision model for histopathology image analysis.
- The model uses a novel self-supervised learning approach to capture the visual patterns and semantic relationships in histopathology images.
- Vim4Path demonstrates state-of-the-art performance on various histopathology tasks, including classification, segmentation, and disease grading.
Plain English Explanation
The paper describes a new artificial intelligence (AI) model called Vim4Path that is designed to analyze medical images from histopathology - the microscopic study of diseased tissues. Histopathology images can be very complex, with numerous cell types and structures that a trained pathologist needs to interpret.
The key innovation of Vim4Path is that it uses a "self-supervised" learning approach, which means the model can learn visual patterns and relationships in the images without needing extensive human-labeled training data. This is helpful because collecting and labeling large medical image datasets can be time-consuming and expensive.
Instead, Vim4Path is able to discover informative visual features on its own by looking for patterns in the unlabeled histopathology images. This learned visual understanding can then be applied to tasks like classifying disease types, segmenting different tissue regions, or grading the severity of a condition. The paper shows that Vim4Path achieves state-of-the-art performance on these kinds of histopathology analysis tasks, outperforming previous machine learning models.
The self-supervised learning approach used in Vim4Path could make it easier and more cost-effective to develop AI systems that can assist pathologists in their diagnostic and research workflows. By automating certain image analysis steps, Vim4Path and similar models have the potential to improve the speed and consistency of histopathology evaluations.
Technical Explanation
The authors propose a new self-supervised vision transformer model called Vim4Path for learning robust visual representations from histopathology images. The key innovation is the use of a self-supervised "vision Mamba" pretraining approach, which builds on prior work on the VIRaL and VMamba models.
The Vim4Path architecture combines a vision transformer backbone with a series of self-supervised pretraining tasks. These include image rotation prediction, patch shuffling, and contrastive learning objectives that capture both local and global visual relationships within the histopathology images. The authors show that this self-supervised pretraining leads to features that are more informative and transferable compared to models trained from scratch or with standard transfer learning.
Vim4Path is evaluated on a range of histopathology benchmarks, including MoNuSeg for nuclear segmentation, CRC for colorectal cancer classification, and PathMNIST for disease grading. The results demonstrate state-of-the-art performance, with Vim4Path outperforming prior approaches like MedMamba and VMambaMorph on these tasks.
Critical Analysis
The authors provide a thorough evaluation of Vim4Path across multiple histopathology benchmarks, which lends strong empirical support for the effectiveness of their self-supervised learning approach. However, some potential limitations or areas for further research are worth noting:
- The paper does not extensively discuss the computational or training efficiency of Vim4Path compared to other models. As medical image analysis often requires fast inference times, this could be an important practical consideration.
- While the self-supervised pretraining is shown to benefit downstream tasks, the authors do not provide a detailed ablation study to fully understand the contributions of each pretraining objective.
- The experiments are limited to 2D histopathology images, but many real-world use cases may involve 3D volumetric medical imaging data. Extending Vim4Path to handle such multi-dimensional inputs could be an interesting direction for future research.
Overall, the Vim4Path model represents a promising step forward in applying self-supervised learning to advance the state-of-the-art in computational histopathology. Further work to address these potential limitations could help solidify the model's applicability in real-world clinical and research settings.
Conclusion
This paper introduces Vim4Path, a novel self-supervised vision transformer model for analyzing histopathology images. By leveraging a variety of self-supervised pretraining tasks, Vim4Path is able to learn visual representations that achieve state-of-the-art performance on a range of histopathology benchmarks, including image classification, segmentation, and disease grading.
The key innovation of Vim4Path is its ability to learn informative visual features from unlabeled histopathology data, which could make it easier and more cost-effective to develop AI systems to assist pathologists in their diagnostic workflows. While the paper highlights some areas for potential improvement, the overall results demonstrate the promise of self-supervised learning techniques for advancing the field of computational histopathology.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📈
Multi-Scale VMamba: Hierarchy in Hierarchy Visual State Space Model
Yuheng Shi, Minjing Dong, Chang Xu
0
0
Despite the significant achievements of Vision Transformers (ViTs) in various vision tasks, they are constrained by the quadratic complexity. Recently, State Space Models (SSMs) have garnered widespread attention due to their global receptive field and linear complexity with respect to the input length, demonstrating substantial potential across fields including natural language processing and computer vision. To improve the performance of SSMs in vision tasks, a multi-scan strategy is widely adopted, which leads to significant redundancy of SSMs. For a better trade-off between efficiency and performance, we analyze the underlying reasons behind the success of the multi-scan strategy, where long-range dependency plays an important role. Based on the analysis, we introduce Multi-Scale Vision Mamba (MSVMamba) to preserve the superiority of SSMs in vision tasks with limited parameters. It employs a multi-scale 2D scanning technique on both original and downsampled feature maps, which not only benefits long-range dependency learning but also reduces computational costs. Additionally, we integrate a Convolutional Feed-Forward Network (ConvFFN) to address the lack of channel mixing. Our experiments demonstrate that MSVMamba is highly competitive, with the MSVMamba-Tiny model achieving 82.8% top-1 accuracy on ImageNet, 46.9% box mAP, and 42.2% instance mAP with the Mask R-CNN framework, 1x training schedule on COCO, and 47.6% mIoU with single-scale testing on ADE20K.Code is available at url{https://github.com/YuHengsss/MSVMamba}.
5/24/2024
MedMamba: Vision Mamba for Medical Image Classification
Yubiao Yue, Zhenzhang Li
0
0
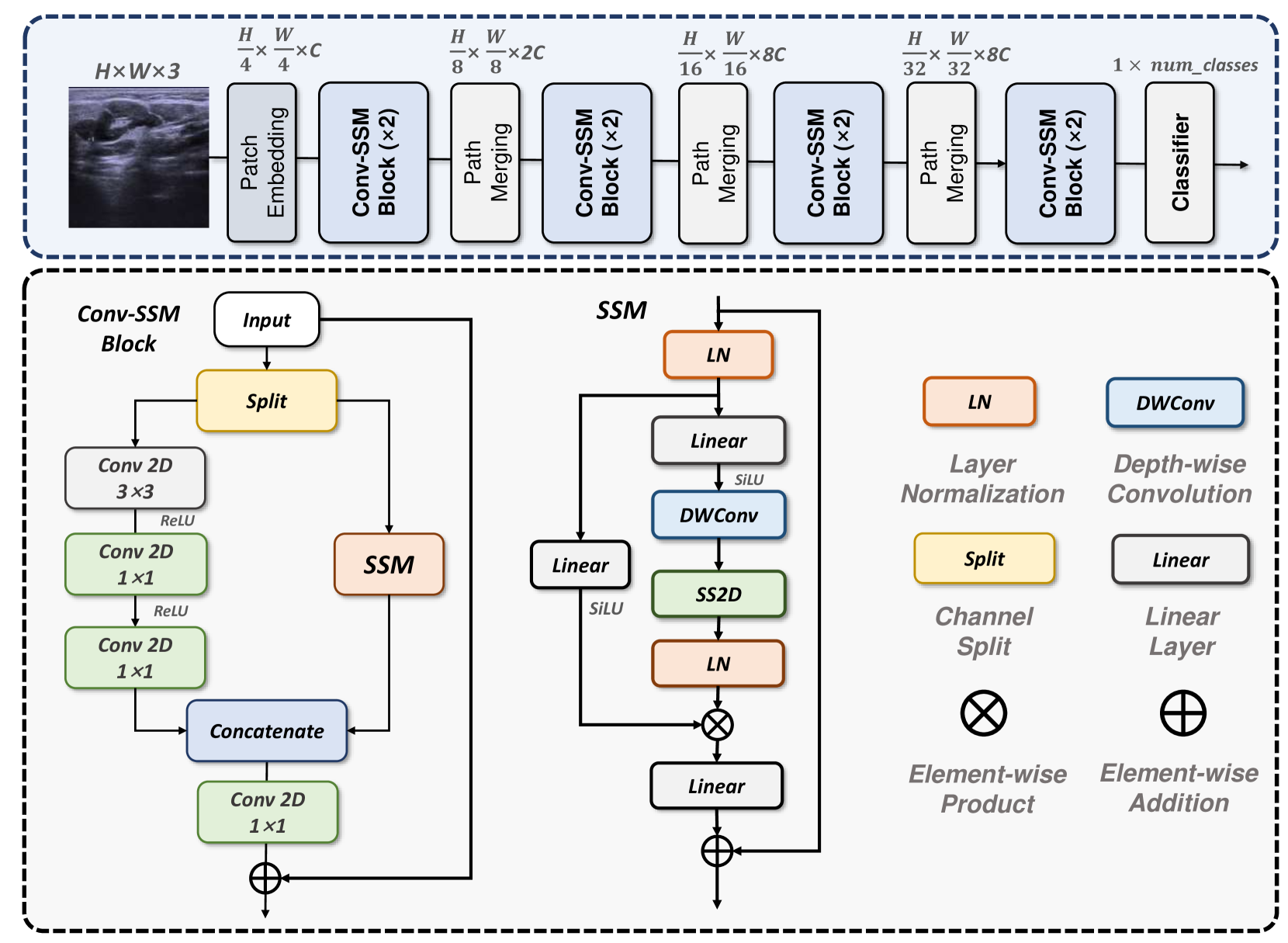
Since the era of deep learning, convolutional neural networks (CNNs) and vision transformers (ViTs) have been extensively studied and widely used in medical image classification tasks. Unfortunately, CNN's limitations in modeling long-range dependencies result in poor classification performances. In contrast, ViTs are hampered by the quadratic computational complexity of their self-attention mechanism, making them difficult to deploy in real-world settings with limited computational resources. Recent studies have shown that state space models (SSMs) represented by Mamba can effectively model long-range dependencies while maintaining linear computational complexity. Inspired by it, we proposed MedMamba, the first vision Mamba for generalized medical image classification. Concretely, we introduced a novel hybrid basic block named SS-Conv-SSM, which integrates the convolutional layers for extracting local features with the abilities of SSM to capture long-range dependencies, aiming to model medical images from different image modalities efficiently. By employing the grouped convolution strategy and channel-shuffle operation, MedMamba successfully provides fewer model parameters and a lower computational burden for efficient applications. To demonstrate the potential of MedMamba, we conducted extensive experiments using 16 datasets containing ten imaging modalities and 411,007 images. Experimental results show that the proposed MedMamba demonstrates competitive performance in classifying various medical images compared with the state-of-the-art methods. Our work is aims to establish a new baseline for medical image classification and provide valuable insights for developing more powerful SSM-based artificial intelligence algorithms and application systems in the medical field. The source codes and all pre-trained weights of MedMamba are available at https://github.com/YubiaoYue/MedMamba.
6/11/2024
VM-DDPM: Vision Mamba Diffusion for Medical Image Synthesis
Zhihan Ju, Wanting Zhou
0
0
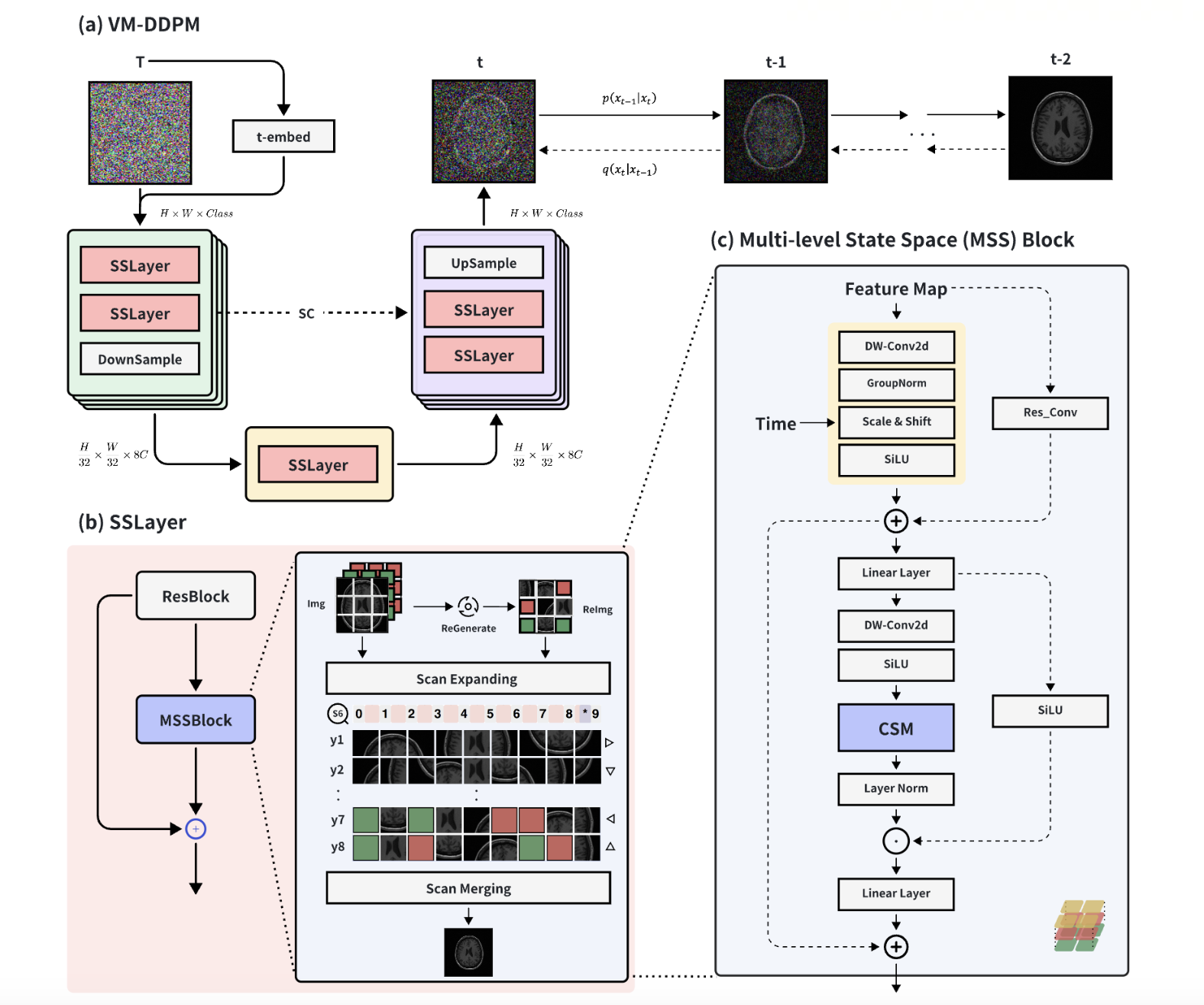
In the realm of smart healthcare, researchers enhance the scale and diversity of medical datasets through medical image synthesis. However, existing methods are limited by CNN local perception and Transformer quadratic complexity, making it difficult to balance structural texture consistency. To this end, we propose the Vision Mamba DDPM (VM-DDPM) based on State Space Model (SSM), fully combining CNN local perception and SSM global modeling capabilities, while maintaining linear computational complexity. Specifically, we designed a multi-level feature extraction module called Multi-level State Space Block (MSSBlock), and a basic unit of encoder-decoder structure called State Space Layer (SSLayer) for medical pathological images. Besides, we designed a simple, Plug-and-Play, zero-parameter Sequence Regeneration strategy for the Cross-Scan Module (CSM), which enabled the S6 module to fully perceive the spatial features of the 2D image and stimulate the generalization potential of the model. To our best knowledge, this is the first medical image synthesis model based on the SSM-CNN hybrid architecture. Our experimental evaluation on three datasets of different scales, i.e., ACDC, BraTS2018, and ChestXRay, as well as qualitative evaluation by radiologists, demonstrate that VM-DDPM achieves state-of-the-art performance.
5/10/2024
VMamba: Visual State Space Model
Yue Liu, Yunjie Tian, Yuzhong Zhao, Hongtian Yu, Lingxi Xie, Yaowei Wang, Qixiang Ye, Yunfan Liu
0
0
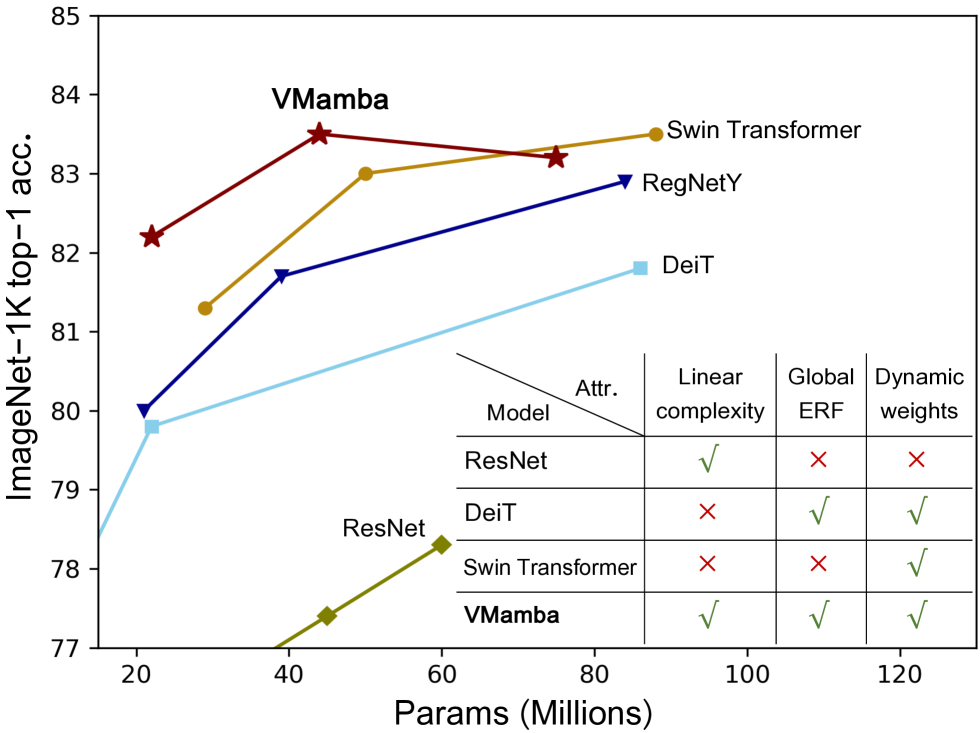
Designing computationally efficient network architectures persists as an ongoing necessity in computer vision. In this paper, we transplant Mamba, a state-space language model, into VMamba, a vision backbone that works in linear time complexity. At the core of VMamba lies a stack of Visual State-Space (VSS) blocks with the 2D Selective Scan (SS2D) module. By traversing along four scanning routes, SS2D helps bridge the gap between the ordered nature of 1D selective scan and the non-sequential structure of 2D vision data, which facilitates the gathering of contextual information from various sources and perspectives. Based on the VSS blocks, we develop a family of VMamba architectures and accelerate them through a succession of architectural and implementation enhancements. Extensive experiments showcase VMamba's promising performance across diverse visual perception tasks, highlighting its advantages in input scaling efficiency compared to existing benchmark models. Source code is available at https://github.com/MzeroMiko/VMamba.
5/28/2024