Spectron: Target Speaker Extraction using Conditional Transformer with Adversarial Refinement

0

Sign in to get full access
Overview
- This paper introduces SPECTRON, a novel deep learning model for target speaker extraction from audio mixtures.
- The model uses a conditional transformer architecture with adversarial refinement to isolate the target speaker's voice from background noise and other speakers.
- Key innovations include the use of a conditional transformer and an adversarial training process to improve extraction quality.
Plain English Explanation
The SPECTRON model was developed to address the challenge of extracting a specific person's voice from an audio recording that contains multiple speakers and background noise. This is a common problem in applications like video conferencing, virtual assistants, and audio transcription.
SPECTRON works by taking the original audio mixture and some additional information about the target speaker, such as a short voice sample. It then uses a deep neural network architecture called a conditional transformer to analyze the audio and identify the parts that correspond to the target speaker.
The key innovation is the use of an adversarial training process to further refine the extracted target audio. This adversarial component helps ensure that the output audio sounds natural and free of distortion, rather than just removing all non-target audio.
Overall, SPECTRON demonstrates strong performance in isolating a target speaker's voice, even in challenging scenarios with significant background noise and interference from other speakers. This could lead to improved voice interaction experiences in a variety of applications.
Technical Explanation
The SPECTRON architecture consists of a conditional transformer network that takes the mixed audio input and a target speaker embedding as inputs. The transformer network learns to attend to the relevant parts of the audio that correspond to the target speaker.
To further improve the quality of the extracted target audio, the authors introduce an adversarial refinement component. This adversarial network is trained to discriminate between the model's output and the ground truth target audio. By optimizing the SPECTRON model to fool the adversarial network, the extracted audio is made to sound more natural and free of artifacts.
The experimental evaluation demonstrates SPECTRON's superior performance compared to prior state-of-the-art target speaker extraction models, particularly in scenarios with high levels of background noise and interference.
Critical Analysis
The paper provides a thorough technical explanation of the SPECTRON model and its key innovations. However, it does not extensively discuss potential limitations or areas for further research.
One potential limitation is the reliance on a target speaker embedding as an additional input. In real-world scenarios, access to a high-quality voice sample of the target speaker may not always be available. It would be valuable to explore techniques that can extract the target speaker without this additional information.
Additionally, the paper does not address the computational complexity or inference speed of the SPECTRON model. These factors could be important considerations for deploying the model in real-time applications.
Further research could investigate the model's robustness to more diverse audio environments, such as reverberant spaces or dynamic background noise. Exploring cross-lingual or multi-lingual extensions of the model could also broaden its applicability.
Conclusion
The SPECTRON model introduces a novel deep learning approach for target speaker extraction that leverages a conditional transformer architecture and adversarial refinement. The technical innovations demonstrated in this work contribute to the advancement of audio processing and could lead to improved voice interaction experiences in a variety of applications.
While the paper provides a strong technical foundation, further research is needed to address potential limitations and explore the model's broader applicability. Nonetheless, SPECTRON represents a significant step forward in the field of target speaker extraction.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Spectron: Target Speaker Extraction using Conditional Transformer with Adversarial Refinement
Tathagata Bandyopadhyay
Recently, attention-based transformers have become a de facto standard in many deep learning applications including natural language processing, computer vision, signal processing, etc.. In this paper, we propose a transformer-based end-to-end model to extract a target speaker's speech from a monaural multi-speaker mixed audio signal. Unlike existing speaker extraction methods, we introduce two additional objectives to impose speaker embedding consistency and waveform encoder invertibility and jointly train both speaker encoder and speech separator to better capture the speaker conditional embedding. Furthermore, we leverage a multi-scale discriminator to refine the perceptual quality of the extracted speech. Our experiments show that the use of a dual path transformer in the separator backbone along with proposed training paradigm improves the CNN baseline by $3.12$ dB points. Finally, we compare our approach with recent state-of-the-arts and show that our model outperforms existing methods by $4.1$ dB points on an average without creating additional data dependency.
Read more9/4/2024
0
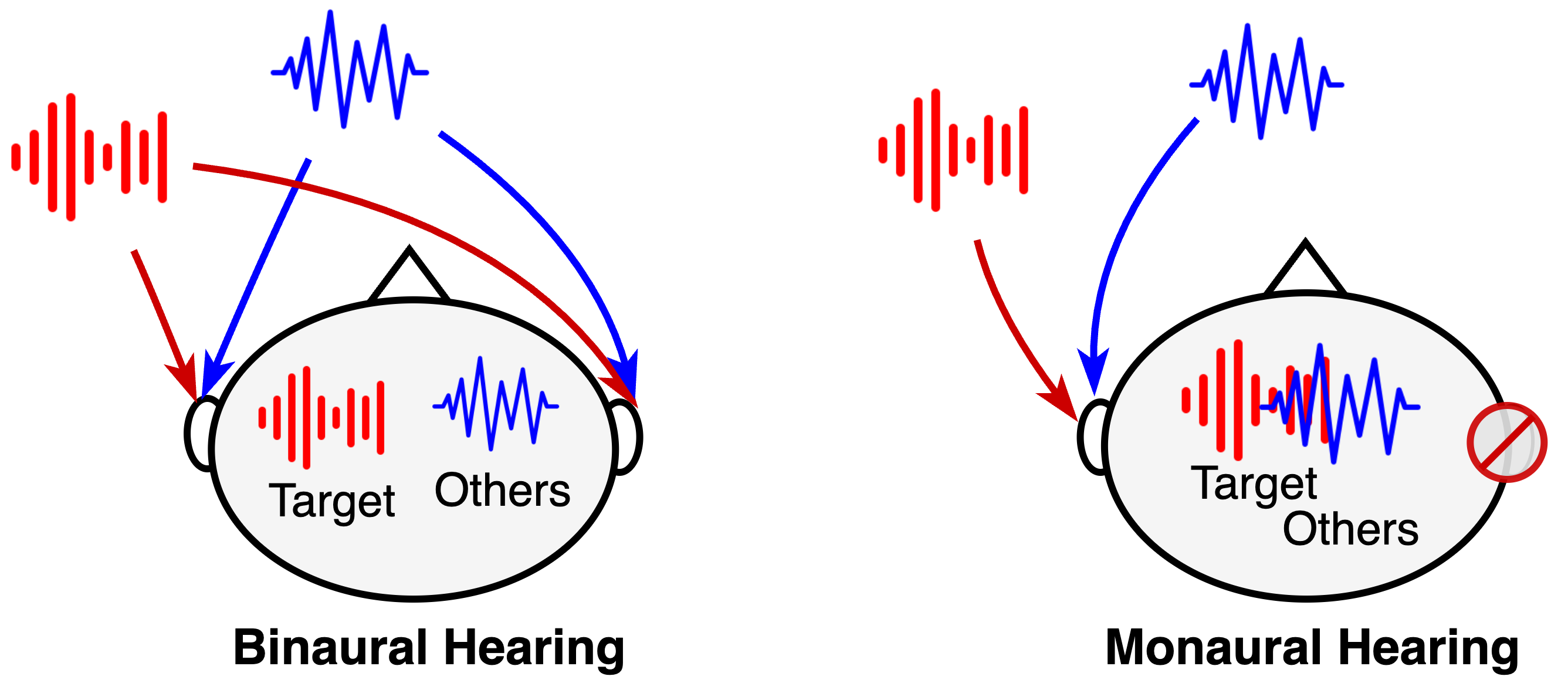
Binaural Selective Attention Model for Target Speaker Extraction
Hanyu Meng, Qiquan Zhang, Xiangyu Zhang, Vidhyasaharan Sethu, Eliathamby Ambikairajah
The remarkable ability of humans to selectively focus on a target speaker in cocktail party scenarios is facilitated by binaural audio processing. In this paper, we present a binaural time-domain Target Speaker Extraction model based on the Filter-and-Sum Network (FaSNet). Inspired by human selective hearing, our proposed model introduces target speaker embedding into separators using a multi-head attention-based selective attention block. We also compared two binaural interaction approaches -- the cosine similarity of time-domain signals and inter-channel correlation in learned spectral representations. Our experimental results show that our proposed model outperforms monaural configurations and state-of-the-art multi-channel target speaker extraction models, achieving best-in-class performance with 18.52 dB SI-SDR, 19.12 dB SDR, and 3.05 PESQ scores under anechoic two-speaker test configurations.
Read more6/19/2024

0
Self-Supervised Disentangled Representation Learning for Robust Target Speech Extraction
Zhaoxi Mu, Xinyu Yang, Sining Sun, Qing Yang
Speech signals are inherently complex as they encompass both global acoustic characteristics and local semantic information. However, in the task of target speech extraction, certain elements of global and local semantic information in the reference speech, which are irrelevant to speaker identity, can lead to speaker confusion within the speech extraction network. To overcome this challenge, we propose a self-supervised disentangled representation learning method. Our approach tackles this issue through a two-phase process, utilizing a reference speech encoding network and a global information disentanglement network to gradually disentangle the speaker identity information from other irrelevant factors. We exclusively employ the disentangled speaker identity information to guide the speech extraction network. Moreover, we introduce the adaptive modulation Transformer to ensure that the acoustic representation of the mixed signal remains undisturbed by the speaker embeddings. This component incorporates speaker embeddings as conditional information, facilitating natural and efficient guidance for the speech extraction network. Experimental results substantiate the effectiveness of our meticulously crafted approach, showcasing a substantial reduction in the likelihood of speaker confusion.
Read more8/27/2024

0
Target Speaker ASR with Whisper
Alexander Polok, Dominik Klement, Matthew Wiesner, Sanjeev Khudanpur, Jan v{C}ernock'y, Luk'av{s} Burget
We propose a novel approach to enable the use of large, single speaker ASR models, such as Whisper, for target speaker ASR. The key insight of this method is that it is much easier to model relative differences among speakers by learning to condition on frame-level diarization outputs, than to learn the space of all speaker embeddings. We find that adding even a single bias term per diarization output type before the first transformer block can transform single speaker ASR models, into target speaker ASR models. Our target-speaker ASR model can be used for speaker attributed ASR by producing, in sequence, a transcript for each hypothesized speaker in a diarization output. This simplified model for speaker attributed ASR using only a single microphone outperforms cascades of speech separation and diarization by 11% absolute ORC-WER on the NOTSOFAR-1 dataset.
Read more9/17/2024