BioRAG: A RAG-LLM Framework for Biological Question Reasoning

0

Sign in to get full access
Overview
- BioRAG is a framework that combines large language models (LLMs) with biological knowledge retrieval for improved reasoning on biological questions.
- The framework aims to enhance the reasoning capabilities of LLMs by allowing them to dynamically retrieve and incorporate relevant information from a knowledge base.
- This approach is designed to address the limitations of standalone LLMs in handling complex, domain-specific biological queries.
Plain English Explanation
BioRAG is a system that combines powerful language models with a database of biological information. The goal is to create AI assistants that can answer tricky questions about biology more accurately.
Standalone language models, while impressive, can sometimes struggle with complex, specialized topics like biology. BioRAG tries to address this by allowing the language model to quickly look up and incorporate relevant facts from a biology knowledge base when answering questions.
This way, the language model can draw upon a rich source of biological information to reason about and respond to questions, rather than relying solely on its own training. The researchers believe this hybrid approach can lead to better, more insightful answers for users seeking biological knowledge.
Technical Explanation
The BioRAG framework consists of two main components: a Retrieval-Augmented Generation (RAG) model and a biological knowledge base.
The RAG model is a large language model that has been trained to not only generate text, but also dynamically retrieve and incorporate relevant information from an external knowledge source when answering questions. In the case of BioRAG, this knowledge source is a database of biological facts and concepts.
When a user poses a biological question, the RAG model first searches the knowledge base to find the most relevant information. It then uses this retrieved data, combined with its own language understanding capabilities, to formulate a comprehensive and biologically-grounded response.
This retrieval-augmented approach is designed to enhance the reasoning abilities of the language model, allowing it to go beyond its initial training and draw upon a wealth of domain-specific knowledge to tackle complex biological queries.
Critical Analysis
The BioRAG framework addresses an important challenge in AI - the ability to reason about and answer questions in specialized domains like biology. By incorporating a knowledge base, the researchers aim to overcome the limitations of standalone language models, which can struggle with complex, technical topics.
However, the paper does not provide a detailed evaluation of the framework's performance compared to other approaches. While the authors mention testing on biological question-answering benchmarks, more thorough experimentation and analysis would be needed to fully assess the system's capabilities and limitations.
Additionally, the reliance on a curated knowledge base could be a potential bottleneck, as maintaining and keeping such a resource up-to-date may be a significant challenge. Exploring ways to dynamically expand or update the knowledge base could further improve the system's long-term viability and relevance.
Conclusion
The BioRAG framework represents a promising step towards developing AI assistants that can engage in more sophisticated, domain-specific reasoning. By combining the power of large language models with the targeted knowledge of a biological database, the researchers aim to create a system that can provide users with more accurate and insightful answers to complex biological questions.
While further research and evaluation are needed, the BioRAG approach demonstrates the potential of retrieval-augmented generation to enhance the capabilities of language models in specialized domains. As AI continues to advance, frameworks like this may play an important role in expanding the reach and utility of these technologies across a wide range of scientific and technical fields.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
BioRAG: A RAG-LLM Framework for Biological Question Reasoning
Chengrui Wang, Qingqing Long, Meng Xiao, Xunxin Cai, Chengjun Wu, Zhen Meng, Xuezhi Wang, Yuanchun Zhou
The question-answering system for Life science research, which is characterized by the rapid pace of discovery, evolving insights, and complex interactions among knowledge entities, presents unique challenges in maintaining a comprehensive knowledge warehouse and accurate information retrieval. To address these issues, we introduce BioRAG, a novel Retrieval-Augmented Generation (RAG) with the Large Language Models (LLMs) framework. Our approach starts with parsing, indexing, and segmenting an extensive collection of 22 million scientific papers as the basic knowledge, followed by training a specialized embedding model tailored to this domain. Additionally, we enhance the vector retrieval process by incorporating a domain-specific knowledge hierarchy, which aids in modeling the intricate interrelationships among each query and context. For queries requiring the most current information, BioRAG deconstructs the question and employs an iterative retrieval process incorporated with the search engine for step-by-step reasoning. Rigorous experiments have demonstrated that our model outperforms fine-tuned LLM, LLM with search engines, and other scientific RAG frameworks across multiple life science question-answering tasks.
Read more8/15/2024

0
RAG based Question-Answering for Contextual Response Prediction System
Sriram Veturi, Saurabh Vaichal, Reshma Lal Jagadheesh, Nafis Irtiza Tripto, Nian Yan
Large Language Models (LLMs) have shown versatility in various Natural Language Processing (NLP) tasks, including their potential as effective question-answering systems. However, to provide precise and relevant information in response to specific customer queries in industry settings, LLMs require access to a comprehensive knowledge base to avoid hallucinations. Retrieval Augmented Generation (RAG) emerges as a promising technique to address this challenge. Yet, developing an accurate question-answering framework for real-world applications using RAG entails several challenges: 1) data availability issues, 2) evaluating the quality of generated content, and 3) the costly nature of human evaluation. In this paper, we introduce an end-to-end framework that employs LLMs with RAG capabilities for industry use cases. Given a customer query, the proposed system retrieves relevant knowledge documents and leverages them, along with previous chat history, to generate response suggestions for customer service agents in the contact centers of a major retail company. Through comprehensive automated and human evaluations, we show that this solution outperforms the current BERT-based algorithms in accuracy and relevance. Our findings suggest that RAG-based LLMs can be an excellent support to human customer service representatives by lightening their workload.
Read more9/9/2024
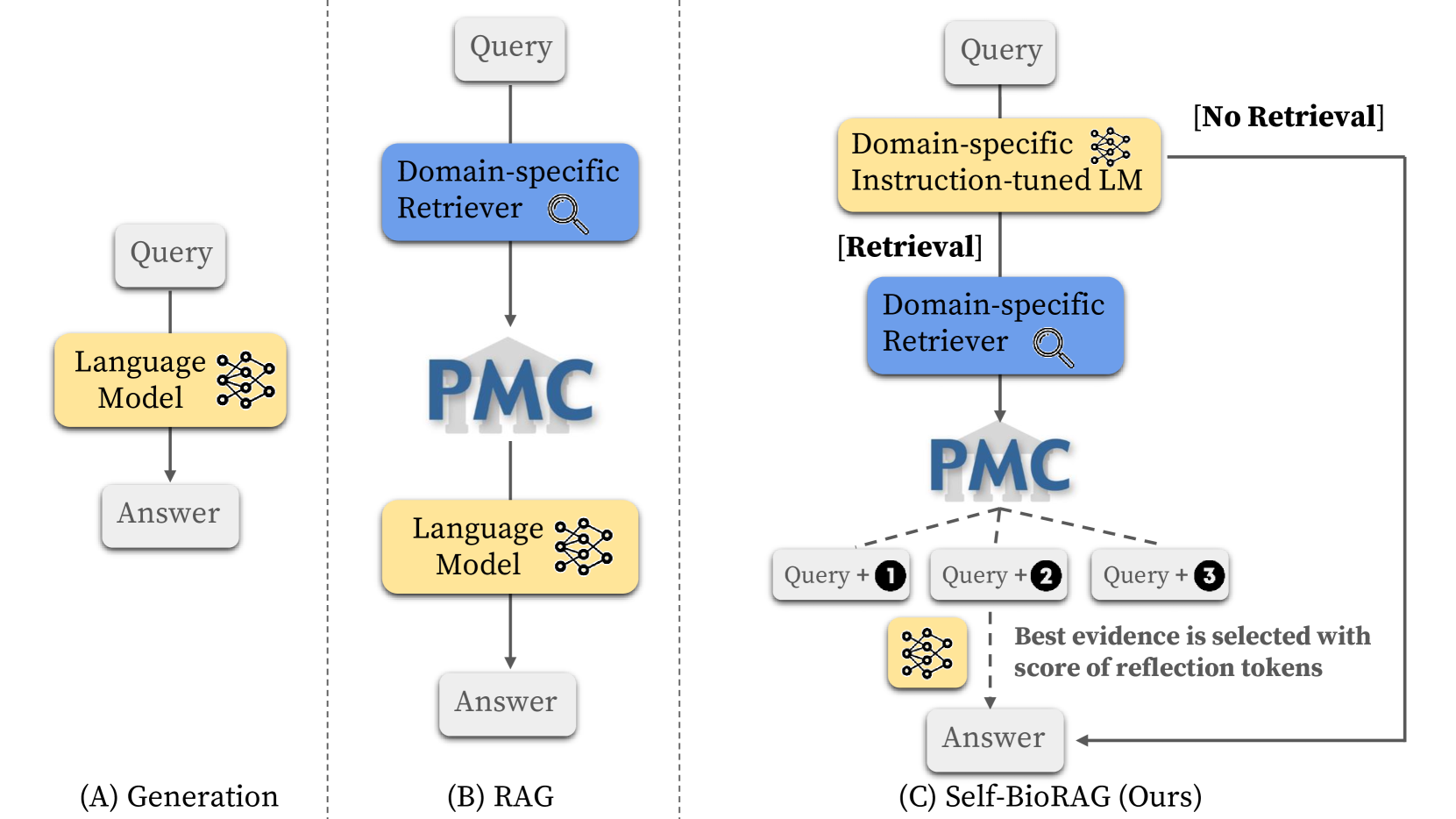
0
Improving Medical Reasoning through Retrieval and Self-Reflection with Retrieval-Augmented Large Language Models
Minbyul Jeong, Jiwoong Sohn, Mujeen Sung, Jaewoo Kang
Recent proprietary large language models (LLMs), such as GPT-4, have achieved a milestone in tackling diverse challenges in the biomedical domain, ranging from multiple-choice questions to long-form generations. To address challenges that still cannot be handled with the encoded knowledge of LLMs, various retrieval-augmented generation (RAG) methods have been developed by searching documents from the knowledge corpus and appending them unconditionally or selectively to the input of LLMs for generation. However, when applying existing methods to different domain-specific problems, poor generalization becomes apparent, leading to fetching incorrect documents or making inaccurate judgments. In this paper, we introduce Self-BioRAG, a framework reliable for biomedical text that specializes in generating explanations, retrieving domain-specific documents, and self-reflecting generated responses. We utilize 84k filtered biomedical instruction sets to train Self-BioRAG that can assess its generated explanations with customized reflective tokens. Our work proves that domain-specific components, such as a retriever, domain-related document corpus, and instruction sets are necessary for adhering to domain-related instructions. Using three major medical question-answering benchmark datasets, experimental results of Self-BioRAG demonstrate significant performance gains by achieving a 7.2% absolute improvement on average over the state-of-the-art open-foundation model with a parameter size of 7B or less. Overall, we analyze that Self-BioRAG finds the clues in the question, retrieves relevant documents if needed, and understands how to answer with information from retrieved documents and encoded knowledge as a medical expert does. We release our data and code for training our framework components and model weights (7B and 13B) to enhance capabilities in biomedical and clinical domains.
Read more6/19/2024
💬
0
BiomedRAG: A Retrieval Augmented Large Language Model for Biomedicine
Mingchen Li, Halil Kilicoglu, Hua Xu, Rui Zhang
Large Language Models (LLMs) have swiftly emerged as vital resources for different applications in the biomedical and healthcare domains; however, these models encounter issues such as generating inaccurate information or hallucinations. Retrieval-augmented generation provided a solution for these models to update knowledge and enhance their performance. In contrast to previous retrieval-augmented LMs, which utilize specialized cross-attention mechanisms to help LLM encode retrieved text, BiomedRAG adopts a simpler approach by directly inputting the retrieved chunk-based documents into the LLM. This straightforward design is easily applicable to existing retrieval and language models, effectively bypassing noise information in retrieved documents, particularly in noise-intensive tasks. Moreover, we demonstrate the potential for utilizing the LLM to supervise the retrieval model in the biomedical domain, enabling it to retrieve the document that assists the LM in improving its predictions. Our experiments reveal that with the tuned scorer,textsc{ BiomedRAG} attains superior performance across 5 biomedical NLP tasks, encompassing information extraction (triple extraction, relation extraction), text classification, link prediction, and question-answering, leveraging over 9 datasets. For instance, in the triple extraction task, textsc{BiomedRAG} outperforms other triple extraction systems with micro-F1 scores of 81.42 and 88.83 on GIT and ChemProt corpora, respectively.
Read more5/6/2024