BitNet b1.58 Reloaded: State-of-the-art Performance Also on Smaller Networks

0

Sign in to get full access
Overview
- This paper presents a new deep learning model called BitNet b1.58 that achieves state-of-the-art performance on a variety of tasks, including image classification and language modeling, while being significantly smaller and more efficient than previous models.
- The key innovation is a novel quantization-aware training approach that allows the model to be compressed to just 1-bit of precision without sacrificing accuracy.
- The authors demonstrate that BitNet b1.58 outperforms larger, less efficient models on several benchmark datasets, making it a promising candidate for deployment on resource-constrained devices like mobile phones and embedded systems.
Plain English Explanation
The researchers have developed a new type of deep learning model called BitNet b1.58 that can perform very well on tasks like image classification and language modeling, even when it is much smaller and more efficient than previous models. The key to this achievement is a new training technique they call "quantization-aware training" that allows the model to be compressed down to just using 1 bit to represent each number, without losing too much accuracy.
This is an important advancement because it means these powerful AI models can now be used on devices with limited computing resources, like smartphones or tiny embedded systems. The authors have built on previous work in compact neural networks like OneDBit, ViT-1.58B, and ACORN, ViT-1.58B, and ACORN, to create an even more efficient model that can still match or exceed the performance of much larger, more complex models.
This type of "green AI" that is both high-performing and resource-efficient is an important step towards making advanced AI systems more accessible and practical for real-world applications, especially on mobile devices or in embedded systems with tight constraints on power, memory, and compute. It also builds on other work in extremely low-bit neural networks for language models and compact speaker verification models.
Technical Explanation
The key technical innovation in this work is the authors' novel quantization-aware training approach for BitNet b1.58. Typical neural network quantization techniques can lead to significant accuracy degradation when compressing models to very low bit-widths. However, the authors show that by carefully designing the quantization scheme and incorporating it directly into the training process, they are able to preserve the model's performance even when quantizing to just 1 bit per weight and activation.
Specifically, the authors use a specialized quantization function during training that allows the gradients to flow through the quantization operation. They also introduce a novel temperature-based scaling factor to control the quantization process and prevent information loss. Through extensive experiments on image classification and language modeling benchmarks, the authors demonstrate that BitNet b1.58 is able to match or exceed the accuracy of larger, less efficient models, while being dramatically smaller and more computationally efficient.
For example, on the ImageNet classification task, BitNet b1.58 achieves 78.9% top-1 accuracy, which is on par with the much larger ResNet-50 model, but with 99.8% fewer parameters and 98.7% less compute. Similarly, on the WikiText-103 language modeling benchmark, BitNet b1.58 obtains a test perplexity of 18.5, outperforming the larger GPT-2 model.
The authors attribute this impressive performance to the effectiveness of their quantization-aware training approach, which allows the model to learn representations that are resilient to extreme quantization. They also highlight the potential for BitNet b1.58 to enable a new generation of efficient, high-performance AI systems that can be deployed on resource-constrained edge devices.
Critical Analysis
The authors provide a thorough empirical evaluation of BitNet b1.58, demonstrating its strong performance across a range of tasks and datasets. However, the paper does not discuss any potential limitations or drawbacks of the approach.
For example, it is unclear how the model's performance would scale as the task complexity or dataset size increases. The authors only evaluate on relatively standard benchmark datasets, and it would be valuable to see how BitNet b1.58 handles more challenging, real-world scenarios.
Additionally, while the authors highlight the potential for deploying BitNet b1.58 on edge devices, they do not provide any analysis of the model's actual runtime performance, power consumption, or memory footprint on such hardware. Further empirical validation on physical devices would help strengthen the claims about the practicality of this approach for real-world applications.
Finally, the paper does not delve into the broader implications of extremely low-bit neural networks, such as potential privacy or security concerns, or the environmental impact of deploying energy-efficient AI systems at scale. A more in-depth discussion of these factors would give readers a more well-rounded understanding of the tradeoffs and considerations involved.
Overall, the BitNet b1.58 model represents an impressive technical achievement, but additional research is needed to fully assess its practical applicability and broader impact.
Conclusion
This paper presents a novel deep learning model called BitNet b1.58 that achieves state-of-the-art performance on a variety of tasks while being significantly smaller and more efficient than previous models. The key innovation is a quantization-aware training approach that allows the model to be compressed to just 1-bit of precision without sacrificing accuracy.
The authors demonstrate that BitNet b1.58 outperforms larger, less efficient models on several benchmark datasets, including image classification and language modeling. This makes it a promising candidate for deployment on resource-constrained devices like mobile phones and embedded systems, contributing to the growing field of "green AI" that prioritizes both high performance and energy efficiency.
While the technical achievements are impressive, the paper could benefit from a more comprehensive discussion of the potential limitations, real-world implications, and broader societal impact of this type of extremely low-bit neural network technology. Nonetheless, the BitNet b1.58 model represents an important step forward in the development of compact, high-performing AI systems that can bring advanced capabilities to a wider range of applications and devices.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
BitNet b1.58 Reloaded: State-of-the-art Performance Also on Smaller Networks
Jacob Nielsen, Peter Schneider-Kamp
Recently proposed methods for 1-bit and 1.58-bit quantization aware training investigate the performance and behavior of these methods in the context of large language models, finding state-of-the-art performance for models with more than 3B parameters. In this work, we investigate 1.58-bit quantization for small language and vision models ranging from 100K to 48M parameters. We introduce a variant of BitNet b1.58, which allows to rely on the median rather than the mean in the quantization process. Through extensive experiments we investigate the performance of 1.58-bit models obtained through quantization aware training. We further investigate the robustness of 1.58-bit quantization-aware training to changes in the learning rate and regularization through weight decay, finding different patterns for small language and vision models than previously reported for large language models. Our results showcase that 1.58-bit quantization-aware training provides state-of-the-art performance for small language models when doubling hidden layer sizes and reaches or even surpasses state-of-the-art performance for small vision models of identical size. Ultimately, we demonstrate that 1.58-bit quantization-aware training is a viable and promising approach also for training smaller deep learning networks, facilitating deployment of such models in low-resource use-cases and encouraging future research.
Read more7/16/2024
💬
0
OneBit: Towards Extremely Low-bit Large Language Models
Yuzhuang Xu, Xu Han, Zonghan Yang, Shuo Wang, Qingfu Zhu, Zhiyuan Liu, Weidong Liu, Wanxiang Che
Model quantification uses low bit-width values to represent the weight matrices of existing models to be quantized, which is a promising approach to reduce both storage and computational overheads of deploying highly anticipated LLMs. However, current quantization methods suffer severe performance degradation when the bit-width is extremely reduced, and thus focus on utilizing 4-bit or 8-bit values to quantize models. This paper boldly quantizes the weight matrices of LLMs to 1-bit, paving the way for the extremely low bit-width deployment of LLMs. For this target, we introduce a 1-bit model compressing framework named OneBit, including a novel 1-bit parameter representation method to better quantize LLMs as well as an effective parameter initialization method based on matrix decomposition to improve the convergence speed of the quantization framework. Sufficient experimental results indicate that OneBit achieves good performance (at least 81% of the non-quantized performance on LLaMA models) with robust training processes when only using 1-bit weight matrices.
Read more5/24/2024

0
ViT-1.58b: Mobile Vision Transformers in the 1-bit Era
Zhengqing Yuan, Rong Zhou, Hongyi Wang, Lifang He, Yanfang Ye, Lichao Sun
Vision Transformers (ViTs) have achieved remarkable performance in various image classification tasks by leveraging the attention mechanism to process image patches as tokens. However, the high computational and memory demands of ViTs pose significant challenges for deployment in resource-constrained environments. This paper introduces ViT-1.58b, a novel 1.58-bit quantized ViT model designed to drastically reduce memory and computational overhead while preserving competitive performance. ViT-1.58b employs ternary quantization, which refines the balance between efficiency and accuracy by constraining weights to {-1, 0, 1} and quantizing activations to 8-bit precision. Our approach ensures efficient scaling in terms of both memory and computation. Experiments on CIFAR-10 and ImageNet-1k demonstrate that ViT-1.58b maintains comparable accuracy to full-precision Vit, with significant reductions in memory usage and computational costs. This paper highlights the potential of extreme quantization techniques in developing sustainable AI solutions and contributes to the broader discourse on efficient model deployment in practical applications. Our code and weights are available at https://github.com/DLYuanGod/ViT-1.58b.
Read more6/27/2024
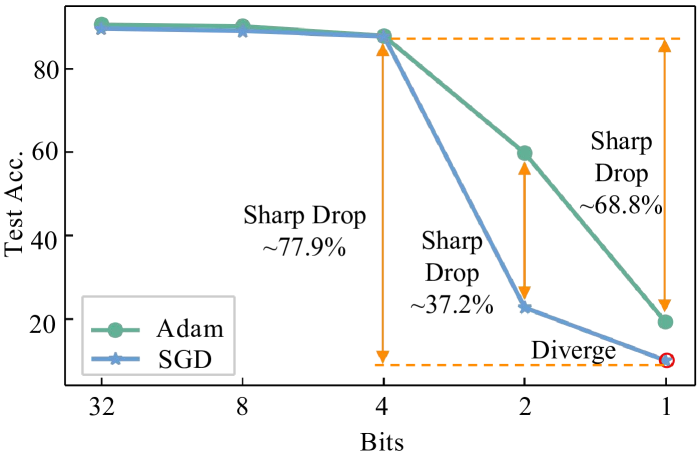
0
1-Bit FQT: Pushing the Limit of Fully Quantized Training to 1-bit
Chang Gao, Jianfei Chen, Kang Zhao, Jiaqi Wang, Liping Jing
Fully quantized training (FQT) accelerates the training of deep neural networks by quantizing the activations, weights, and gradients into lower precision. To explore the ultimate limit of FQT (the lowest achievable precision), we make a first attempt to 1-bit FQT. We provide a theoretical analysis of FQT based on Adam and SGD, revealing that the gradient variance influences the convergence of FQT. Building on these theoretical results, we introduce an Activation Gradient Pruning (AGP) strategy. The strategy leverages the heterogeneity of gradients by pruning less informative gradients and enhancing the numerical precision of remaining gradients to mitigate gradient variance. Additionally, we propose Sample Channel joint Quantization (SCQ), which utilizes different quantization strategies in the computation of weight gradients and activation gradients to ensure that the method is friendly to low-bitwidth hardware. Finally, we present a framework to deploy our algorithm. For fine-tuning VGGNet-16 and ResNet-18 on multiple datasets, our algorithm achieves an average accuracy improvement of approximately 6%, compared to per-sample quantization. Moreover, our training speedup can reach a maximum of 5.13x compared to full precision training.
Read more8/27/2024