BIVDiff: A Training-Free Framework for General-Purpose Video Synthesis via Bridging Image and Video Diffusion Models
2312.02813
0
0
🖼️
Abstract
Diffusion models have made tremendous progress in text-driven image and video generation. Now text-to-image foundation models are widely applied to various downstream image synthesis tasks, such as controllable image generation and image editing, while downstream video synthesis tasks are less explored for several reasons. First, it requires huge memory and computation overhead to train a video generation foundation model. Even with video foundation models, additional costly training is still required for downstream video synthesis tasks. Second, although some works extend image diffusion models into videos in a training-free manner, temporal consistency cannot be well preserved. Finally, these adaption methods are specifically designed for one task and fail to generalize to different tasks. To mitigate these issues, we propose a training-free general-purpose video synthesis framework, coined as {bf BIVDiff}, via bridging specific image diffusion models and general text-to-video foundation diffusion models. Specifically, we first use a specific image diffusion model (e.g., ControlNet and Instruct Pix2Pix) for frame-wise video generation, then perform Mixed Inversion on the generated video, and finally input the inverted latents into the video diffusion models (e.g., VidRD and ZeroScope) for temporal smoothing. This decoupled framework enables flexible image model selection for different purposes with strong task generalization and high efficiency. To validate the effectiveness and general use of BIVDiff, we perform a wide range of video synthesis tasks, including controllable video generation, video editing, video inpainting, and outpainting.
Create account to get full access
Overview
- Diffusion models have made significant progress in text-driven image and video generation.
- Text-to-image foundation models are widely used for various image synthesis tasks, while video synthesis tasks are less explored.
- There are several challenges in developing video synthesis models, including high memory and computation requirements, difficulty in preserving temporal consistency, and lack of generalization.
- To address these issues, the paper proposes a training-free general-purpose video synthesis framework, called BIVDiff, which bridges specific image diffusion models and general text-to-video foundation diffusion models.
Plain English Explanation
Diffusion models are a type of AI model that can generate images and videos based on text descriptions. These models have made impressive progress, allowing users to create images just by describing what they want to see.
However, while text-to-image models are widely used for various image editing and generation tasks, video synthesis tasks are less explored. This is because training a video generation model requires a lot of memory and computing power, and it can be challenging to ensure the generated videos have smooth, consistent movement over time.
To address these issues, the researchers propose a new framework called BIVDiff. This framework combines specific image diffusion models, which are good at generating individual frames, with general text-to-video diffusion models, which can smooth out the transitions between frames to create fluid, coherent videos.
The key idea is to first use a specialized image model to generate each frame of the video, and then pass those frames through a video diffusion model to refine the transitions and make the whole video look more natural. This decoupled approach allows for more flexibility in choosing the right image model for the task, while still benefiting from the video smoothing capabilities of the text-to-video model.
The researchers show that BIVDiff can be used for a variety of video synthesis tasks, such as generating controllable videos, editing existing videos, and even "inpainting" or "outpainting" videos (adding or removing content). By bridging the gap between image and video diffusion models, BIVDiff offers a general-purpose, efficient solution for a wide range of video generation and manipulation tasks.
Technical Explanation
The paper proposes a training-free general-purpose video synthesis framework called BIVDiff, which bridges specific image diffusion models and general text-to-video foundation diffusion models.
Specifically, the BIVDiff framework first uses a specific image diffusion model (e.g., ControlNet or Instruct Pix2Pix) to generate individual video frames. Then, it performs a process called "Mixed Inversion" on the generated video, which aligns the latent representations of the frames. Finally, the inverted latents are input into a video diffusion model (e.g., VidRD or [ZeroScope]) for temporal smoothing.
This decoupled approach offers several advantages:
- Flexible Image Model Selection: The framework allows users to choose the most appropriate image diffusion model for their specific task, without being constrained by the capabilities of a single, pre-trained video generation model.
- Strong Task Generalization: By separating the image generation and video smoothing components, the framework can be applied to a wide range of video synthesis tasks, such as controllable video generation, video editing, inpainting, and outpainting.
- High Efficiency: The training-free nature of the framework means it can be applied to generate videos without the need for costly additional training, which is often required for adapting video synthesis models to specific tasks.
To validate the effectiveness and versatility of BIVDiff, the researchers evaluate it on a variety of video synthesis tasks, demonstrating its ability to generate high-quality, temporally consistent videos with flexible control and editing capabilities.
Critical Analysis
The paper presents a promising approach to address the challenges of video synthesis using diffusion models. The key strength of the BIVDiff framework is its flexibility and generalization, which allows it to be applied to a wide range of video synthesis tasks without the need for task-specific training.
However, the paper does not provide a detailed comparison of BIVDiff's performance against existing state-of-the-art video synthesis methods. While the framework's training-free and flexible nature are compelling, it would be valuable to understand how it performs relative to other approaches in terms of metrics like video quality, temporal consistency, and task-specific performance.
Additionally, the paper does not address potential limitations or failure cases of the BIVDiff framework. For example, it would be helpful to understand the types of videos or tasks where the framework may struggle, or the potential limitations of the image diffusion models and video diffusion models used in the decoupled approach.
Overall, the BIVDiff framework presents an interesting and promising direction for advancing video synthesis capabilities, but further research and evaluation would be needed to fully assess its strengths, weaknesses, and potential impact on the field.
Conclusion
The paper introduces a training-free general-purpose video synthesis framework called BIVDiff, which bridges the gap between specific image diffusion models and general text-to-video foundation diffusion models. By decoupling the image generation and video smoothing components, BIVDiff offers a flexible and efficient approach to a wide range of video synthesis tasks, including controllable video generation, video editing, inpainting, and outpainting.
The key innovation of the BIVDiff framework is its ability to leverage the strengths of both specialized image diffusion models and general text-to-video diffusion models, without the need for costly additional training. This approach allows for greater flexibility in model selection and task generalization, making it a potentially valuable tool for researchers and developers working on advancing video synthesis capabilities.
While the paper demonstrates the effectiveness of BIVDiff, further research and evaluation would be needed to fully understand its limitations and potential impact on the field of video generation and manipulation. Nonetheless, the BIVDiff framework represents an important step forward in bridging the gap between image and video diffusion models, and its training-free, general-purpose nature could have significant implications for the future of video synthesis technology.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

I2VEdit: First-Frame-Guided Video Editing via Image-to-Video Diffusion Models
Wenqi Ouyang, Yi Dong, Lei Yang, Jianlou Si, Xingang Pan
0
0
The remarkable generative capabilities of diffusion models have motivated extensive research in both image and video editing. Compared to video editing which faces additional challenges in the time dimension, image editing has witnessed the development of more diverse, high-quality approaches and more capable software like Photoshop. In light of this gap, we introduce a novel and generic solution that extends the applicability of image editing tools to videos by propagating edits from a single frame to the entire video using a pre-trained image-to-video model. Our method, dubbed I2VEdit, adaptively preserves the visual and motion integrity of the source video depending on the extent of the edits, effectively handling global edits, local edits, and moderate shape changes, which existing methods cannot fully achieve. At the core of our method are two main processes: Coarse Motion Extraction to align basic motion patterns with the original video, and Appearance Refinement for precise adjustments using fine-grained attention matching. We also incorporate a skip-interval strategy to mitigate quality degradation from auto-regressive generation across multiple video clips. Experimental results demonstrate our framework's superior performance in fine-grained video editing, proving its capability to produce high-quality, temporally consistent outputs.
5/28/2024

ZeroSmooth: Training-free Diffuser Adaptation for High Frame Rate Video Generation
Shaoshu Yang, Yong Zhang, Xiaodong Cun, Ying Shan, Ran He
0
0
Video generation has made remarkable progress in recent years, especially since the advent of the video diffusion models. Many video generation models can produce plausible synthetic videos, e.g., Stable Video Diffusion (SVD). However, most video models can only generate low frame rate videos due to the limited GPU memory as well as the difficulty of modeling a large set of frames. The training videos are always uniformly sampled at a specified interval for temporal compression. Previous methods promote the frame rate by either training a video interpolation model in pixel space as a postprocessing stage or training an interpolation model in latent space for a specific base video model. In this paper, we propose a training-free video interpolation method for generative video diffusion models, which is generalizable to different models in a plug-and-play manner. We investigate the non-linearity in the feature space of video diffusion models and transform a video model into a self-cascaded video diffusion model with incorporating the designed hidden state correction modules. The self-cascaded architecture and the correction module are proposed to retain the temporal consistency between key frames and the interpolated frames. Extensive evaluations are preformed on multiple popular video models to demonstrate the effectiveness of the propose method, especially that our training-free method is even comparable to trained interpolation models supported by huge compute resources and large-scale datasets.
6/4/2024

AID: Adapting Image2Video Diffusion Models for Instruction-guided Video Prediction
Zhen Xing, Qi Dai, Zejia Weng, Zuxuan Wu, Yu-Gang Jiang
0
0
Text-guided video prediction (TVP) involves predicting the motion of future frames from the initial frame according to an instruction, which has wide applications in virtual reality, robotics, and content creation. Previous TVP methods make significant breakthroughs by adapting Stable Diffusion for this task. However, they struggle with frame consistency and temporal stability primarily due to the limited scale of video datasets. We observe that pretrained Image2Video diffusion models possess good priors for video dynamics but they lack textual control. Hence, transferring Image2Video models to leverage their video dynamic priors while injecting instruction control to generate controllable videos is both a meaningful and challenging task. To achieve this, we introduce the Multi-Modal Large Language Model (MLLM) to predict future video states based on initial frames and text instructions. More specifically, we design a dual query transformer (DQFormer) architecture, which integrates the instructions and frames into the conditional embeddings for future frame prediction. Additionally, we develop Long-Short Term Temporal Adapters and Spatial Adapters that can quickly transfer general video diffusion models to specific scenarios with minimal training costs. Experimental results show that our method significantly outperforms state-of-the-art techniques on four datasets: Something Something V2, Epic Kitchen-100, Bridge Data, and UCF-101. Notably, AID achieves 91.2% and 55.5% FVD improvements on Bridge and SSv2 respectively, demonstrating its effectiveness in various domains. More examples can be found at our website https://chenhsing.github.io/AID.
6/11/2024
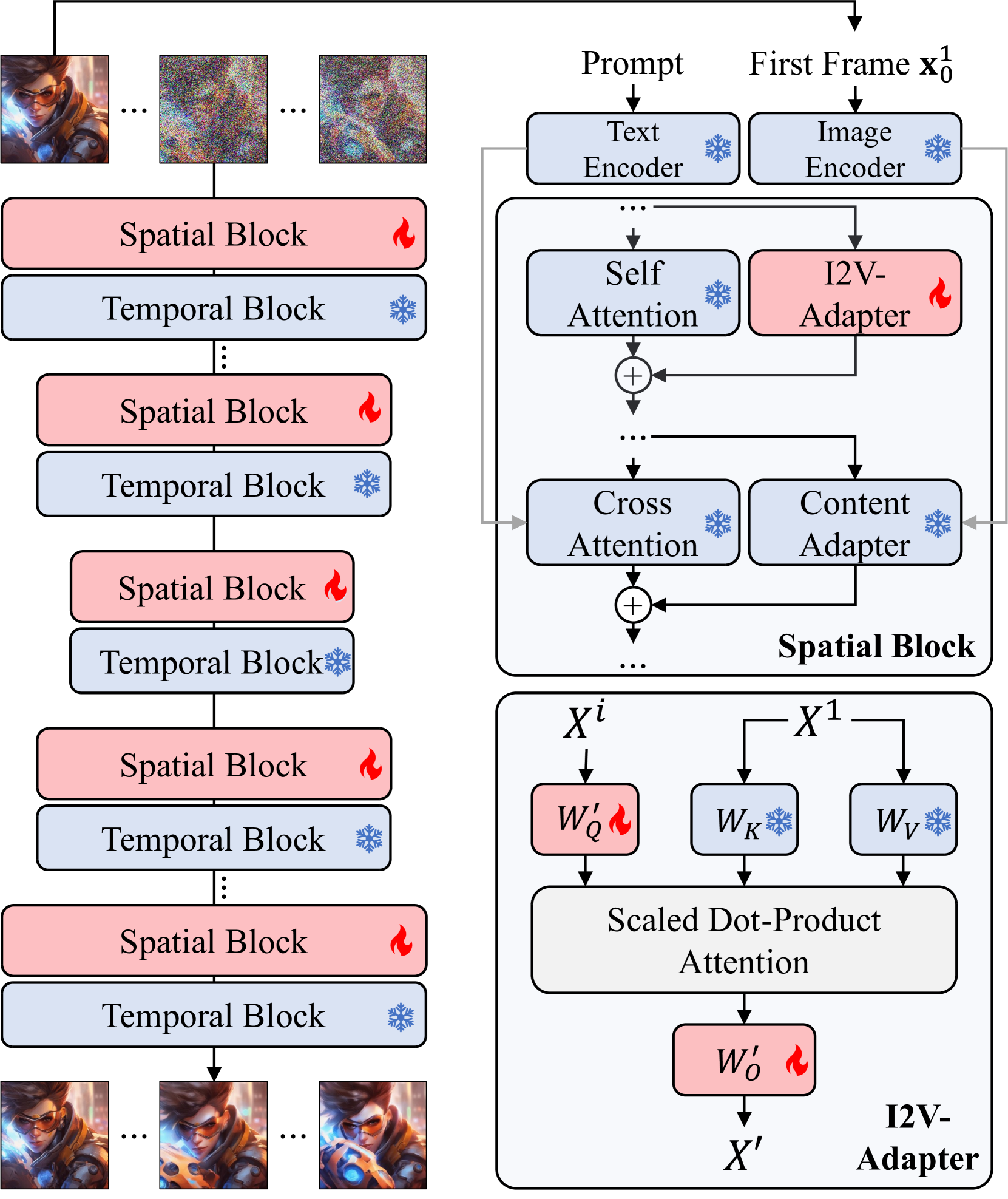
I2V-Adapter: A General Image-to-Video Adapter for Diffusion Models
Xun Guo, Mingwu Zheng, Liang Hou, Yuan Gao, Yufan Deng, Pengfei Wan, Di Zhang, Yufan Liu, Weiming Hu, Zhengjun Zha, Haibin Huang, Chongyang Ma
0
0
Text-guided image-to-video (I2V) generation aims to generate a coherent video that preserves the identity of the input image and semantically aligns with the input prompt. Existing methods typically augment pretrained text-to-video (T2V) models by either concatenating the image with noised video frames channel-wise before being fed into the model or injecting the image embedding produced by pretrained image encoders in cross-attention modules. However, the former approach often necessitates altering the fundamental weights of pretrained T2V models, thus restricting the model's compatibility within the open-source communities and disrupting the model's prior knowledge. Meanwhile, the latter typically fails to preserve the identity of the input image. We present I2V-Adapter to overcome such limitations. I2V-Adapter adeptly propagates the unnoised input image to subsequent noised frames through a cross-frame attention mechanism, maintaining the identity of the input image without any changes to the pretrained T2V model. Notably, I2V-Adapter only introduces a few trainable parameters, significantly alleviating the training cost and also ensures compatibility with existing community-driven personalized models and control tools. Moreover, we propose a novel Frame Similarity Prior to balance the motion amplitude and the stability of generated videos through two adjustable control coefficients. Our experimental results demonstrate that I2V-Adapter is capable of producing high-quality videos. This performance, coupled with its agility and adaptability, represents a substantial advancement in the field of I2V, particularly for personalized and controllable applications.
5/15/2024