CCEdit: Creative and Controllable Video Editing via Diffusion Models
2309.16496
0
0
🤔
Abstract
In this paper, we present CCEdit, a versatile generative video editing framework based on diffusion models. Our approach employs a novel trident network structure that separates structure and appearance control, ensuring precise and creative editing capabilities. Utilizing the foundational ControlNet architecture, we maintain the structural integrity of the video during editing. The incorporation of an additional appearance branch enables users to exert fine-grained control over the edited key frame. These two side branches seamlessly integrate into the main branch, which is constructed upon existing text-to-image (T2I) generation models, through learnable temporal layers. The versatility of our framework is demonstrated through a diverse range of choices in both structure representations and personalized T2I models, as well as the option to provide the edited key frame. To facilitate comprehensive evaluation, we introduce the BalanceCC benchmark dataset, comprising 100 videos and 4 target prompts for each video. Our extensive user studies compare CCEdit with eight state-of-the-art video editing methods. The outcomes demonstrate CCEdit's substantial superiority over all other methods.
Create account to get full access
Overview
- Presents CCEdit, a versatile generative video editing framework based on diffusion models
- Introduces a novel trident network structure that separates structure and appearance control for precise and creative video editing
- Leverages the ControlNet architecture to maintain structural integrity during editing
- Incorporates an additional appearance branch for fine-grained control over the edited key frame
- Demonstrates versatility through various structure representations, personalized text-to-image models, and the option to provide the edited key frame
- Introduces the BalanceCC benchmark dataset for comprehensive evaluation
- Outperforms eight state-of-the-art video editing methods in user studies
Plain English Explanation
The researchers have developed a new video editing tool called CCEdit that allows users to make precise and creative changes to their videos. The key innovation is a specialized network architecture that separates the control of the video's structure (e.g., the movement and positioning of objects) from the control of its appearance (e.g., the colors and textures).
This separation of structure and appearance enables users to make very targeted edits. For example, they can change the movement of an object without altering its visual characteristics, or vice versa. The structural integrity of the video is maintained using a technique called ControlNet, while an additional "appearance branch" gives users fine-grained control over the edited key frames.
The researchers demonstrate the versatility of their framework by allowing users to choose from different ways of representing the video's structure, as well as different text-to-image models to generate the desired appearance. They also give users the option to provide an edited key frame as input.
To thoroughly evaluate their system, the researchers created a new benchmark dataset called BalanceCC, which contains 100 videos with 4 target prompts for each one. When compared to 8 other state-of-the-art video editing methods, CCEdit was found to be significantly better across a range of user studies.
Technical Explanation
The core of CCEdit is a novel "trident network" structure that separates the video editing process into two main branches: one for controlling the structural integrity of the video, and another for controlling its visual appearance.
The structural branch employs the ControlNet [^1] architecture to maintain the overall movement and positioning of objects in the video, ensuring that edits do not compromise the fundamental visual flow. The appearance branch, on the other hand, allows for fine-grained control over the edited key frames by incorporating an additional learnable component.
These two side branches are seamlessly integrated into the main branch, which is built upon existing text-to-image (T2I) generation models. The researchers leverage the temporal modeling capabilities of these T2I models to enable coherent video editing across multiple frames.
To facilitate a comprehensive evaluation of their framework, the researchers introduced the BalanceCC benchmark dataset. This dataset contains 100 videos, each with 4 target prompts, allowing for a diverse and rigorous assessment of CCEdit's capabilities.
The researchers conducted extensive user studies comparing CCEdit to 8 state-of-the-art video editing methods, including VideoEdit-Zero, UniEdit, and DragVideo. The results demonstrate the substantial superiority of CCEdit over all other methods in terms of both editing quality and user satisfaction.
Critical Analysis
The researchers have presented a well-designed and comprehensive framework for generative video editing. The key strengths of their approach include the separation of structure and appearance control, the use of ControlNet to maintain visual integrity, and the versatility offered by the various structure representations and T2I models.
However, the paper does not address the potential computational and memory requirements of the trident network structure, which could be a concern for real-time or resource-constrained applications. Additionally, the researchers do not discuss the model's performance on longer or more complex videos, or its ability to handle diverse video content beyond the specific BalanceCC dataset.
Further research could explore the integration of additional video editing capabilities, such as DiffusionDollar2Dollar for 3D content generation or Investigating Effectiveness of Cross-Attention for zero-shot video editing. Evaluating the system's performance on real-world video editing tasks and obtaining feedback from professional video editors would also be valuable.
Conclusion
The CCEdit framework represents a significant advancement in generative video editing by introducing a novel trident network structure that separates structure and appearance control. This approach enables precise and creative video editing while maintaining the structural integrity of the video. The versatility of the framework, combined with its superior performance compared to state-of-the-art methods, suggests that CCEdit has the potential to revolutionize the way people edit and create videos.
[^1]: ControlNet: A Flexible and Efficient Framework for Image-to-Image Translation
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

I2VEdit: First-Frame-Guided Video Editing via Image-to-Video Diffusion Models
Wenqi Ouyang, Yi Dong, Lei Yang, Jianlou Si, Xingang Pan
0
0
The remarkable generative capabilities of diffusion models have motivated extensive research in both image and video editing. Compared to video editing which faces additional challenges in the time dimension, image editing has witnessed the development of more diverse, high-quality approaches and more capable software like Photoshop. In light of this gap, we introduce a novel and generic solution that extends the applicability of image editing tools to videos by propagating edits from a single frame to the entire video using a pre-trained image-to-video model. Our method, dubbed I2VEdit, adaptively preserves the visual and motion integrity of the source video depending on the extent of the edits, effectively handling global edits, local edits, and moderate shape changes, which existing methods cannot fully achieve. At the core of our method are two main processes: Coarse Motion Extraction to align basic motion patterns with the original video, and Appearance Refinement for precise adjustments using fine-grained attention matching. We also incorporate a skip-interval strategy to mitigate quality degradation from auto-regressive generation across multiple video clips. Experimental results demonstrate our framework's superior performance in fine-grained video editing, proving its capability to produce high-quality, temporally consistent outputs.
5/28/2024
🎲
LOVECon: Text-driven Training-Free Long Video Editing with ControlNet
Zhenyi Liao, Zhijie Deng
0
0
Leveraging pre-trained conditional diffusion models for video editing without further tuning has gained increasing attention due to its promise in film production, advertising, etc. Yet, seminal works in this line fall short in generation length, temporal coherence, or fidelity to the source video. This paper aims to bridge the gap, establishing a simple and effective baseline for training-free diffusion model-based long video editing. As suggested by prior arts, we build the pipeline upon ControlNet, which excels at various image editing tasks based on text prompts. To break down the length constraints caused by limited computational memory, we split the long video into consecutive windows and develop a novel cross-window attention mechanism to ensure the consistency of global style and maximize the smoothness among windows. To achieve more accurate control, we extract the information from the source video via DDIM inversion and integrate the outcomes into the latent states of the generations. We also incorporate a video frame interpolation model to mitigate the frame-level flickering issue. Extensive empirical studies verify the superior efficacy of our method over competing baselines across scenarios, including the replacement of the attributes of foreground objects, style transfer, and background replacement. Besides, our method manages to edit videos comprising hundreds of frames according to user requirements. Our project is open-sourced and the project page is at https://github.com/zhijie-group/LOVECon.
5/29/2024

Collaborative Video Diffusion: Consistent Multi-video Generation with Camera Control
Zhengfei Kuang, Shengqu Cai, Hao He, Yinghao Xu, Hongsheng Li, Leonidas Guibas, Gordon Wetzstein
0
0
Research on video generation has recently made tremendous progress, enabling high-quality videos to be generated from text prompts or images. Adding control to the video generation process is an important goal moving forward and recent approaches that condition video generation models on camera trajectories make strides towards it. Yet, it remains challenging to generate a video of the same scene from multiple different camera trajectories. Solutions to this multi-video generation problem could enable large-scale 3D scene generation with editable camera trajectories, among other applications. We introduce collaborative video diffusion (CVD) as an important step towards this vision. The CVD framework includes a novel cross-video synchronization module that promotes consistency between corresponding frames of the same video rendered from different camera poses using an epipolar attention mechanism. Trained on top of a state-of-the-art camera-control module for video generation, CVD generates multiple videos rendered from different camera trajectories with significantly better consistency than baselines, as shown in extensive experiments. Project page: https://collaborativevideodiffusion.github.io/.
5/28/2024
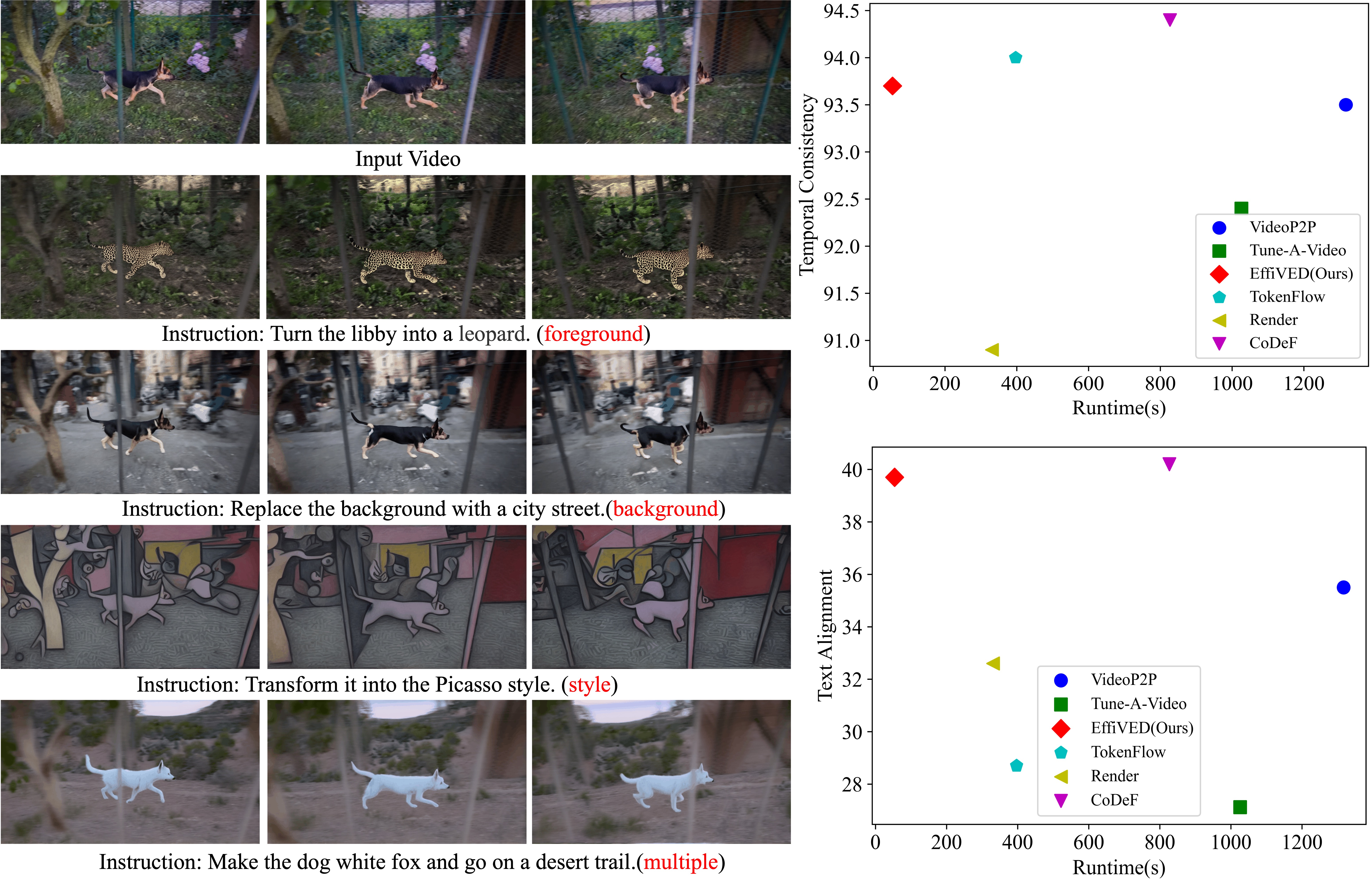
EffiVED:Efficient Video Editing via Text-instruction Diffusion Models
Zhenghao Zhang, Zuozhuo Dai, Long Qin, Weizhi Wang
0
0
Large-scale text-to-video models have shown remarkable abilities, but their direct application in video editing remains challenging due to limited available datasets. Current video editing methods commonly require per-video fine-tuning of diffusion models or specific inversion optimization to ensure high-fidelity edits. In this paper, we introduce EffiVED, an efficient diffusion-based model that directly supports instruction-guided video editing. To achieve this, we present two efficient workflows to gather video editing pairs, utilizing augmentation and fundamental vision-language techniques. These workflows transform vast image editing datasets and open-world videos into a high-quality dataset for training EffiVED. Experimental results reveal that EffiVED not only generates high-quality editing videos but also executes rapidly. Finally, we demonstrate that our data collection method significantly improves editing performance and can potentially tackle the scarcity of video editing data. Code can be found at https://github.com/alibaba/EffiVED.
6/6/2024