Boosting 3D Neuron Segmentation with 2D Vision Transformer Pre-trained on Natural Images

0
Sign in to get full access
Overview
- This paper explores using a 2D Vision Transformer (ViT) model pre-trained on natural images to boost the performance of 3D neuron segmentation tasks.
- The authors hypothesize that the pre-trained ViT model can capture general visual representations that are useful for the 3D neuron segmentation problem, even though the target task is quite different from the original pre-training domain.
- The authors conduct experiments to evaluate the effectiveness of this approach and compare it to other state-of-the-art methods for 3D neuron segmentation.
Plain English Explanation
The paper is about using a machine learning model called a "2D Vision Transformer" that has been trained on everyday natural images, like photos of people, animals, and landscapes, to help with the task of automatically segmenting, or outlining, individual neurons in 3D brain images.
The researchers thought that even though the original training of the Vision Transformer model was on regular 2D photos, the visual patterns and features it had learned could still be useful for analyzing the 3D brain images and identifying the individual neurons. So they took this pre-trained 2D Vision Transformer model and used it as part of a larger system for 3D neuron segmentation, to see if it would boost the performance compared to other approaches.
Through their experiments, the authors found that incorporating the 2D Vision Transformer model did in fact improve the accuracy and quality of the 3D neuron segmentation, compared to using other state-of-the-art methods alone. This suggests that leveraging general visual representation models, even if they were trained on very different types of images, can be a powerful technique for specialized computer vision tasks like analyzing 3D brain scans.
Technical Explanation
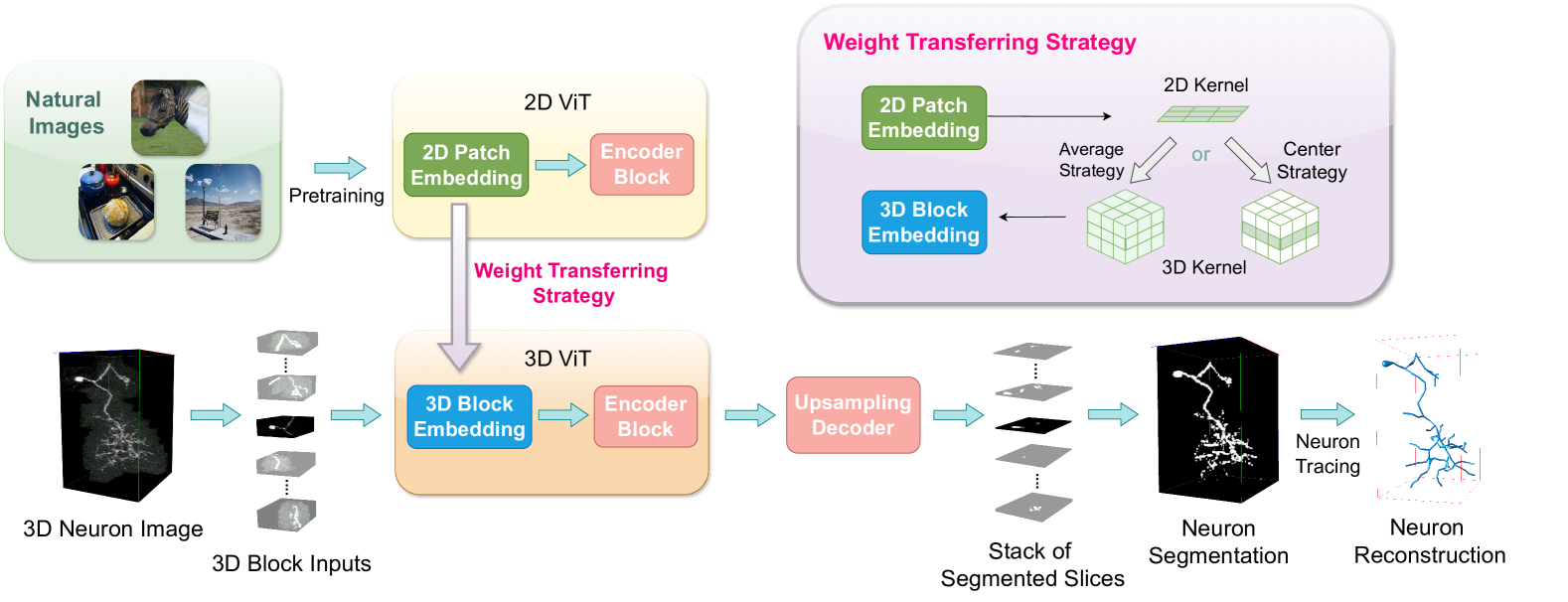
The authors propose a novel approach for boosting the performance of 3D neuron segmentation by incorporating a 2D Vision Transformer (ViT) model that has been pre-trained on large-scale natural image datasets. The intuition is that the ViT model, despite being trained on 2D natural images, can capture general visual representations that are transferable and beneficial for the 3D neuron segmentation task.
The overall architecture combines the pre-trained ViT model with a 3D U-Net-based segmentation network. The ViT model is used to extract visual features from 2D slices of the 3D brain volumes, and these features are then fused with the 3D features extracted by the U-Net backbone.
The authors conduct experiments on publicly available 3D neuron segmentation datasets and compare their approach to other state-of-the-art methods, including SegFormer3D, More You See 2D, and Cross-View Cross-Pose Completion. The results demonstrate that leveraging the pre-trained ViT model leads to significant improvements in 3D neuron segmentation performance, outperforming the other state-of-the-art approaches.
Critical Analysis
The authors provide a thorough evaluation of their proposed approach and acknowledge several caveats and limitations. One key limitation is that the performance gains are dependent on the availability of a large, high-quality dataset for pre-training the ViT model on natural images. If such a dataset is not available, the benefits of their approach may be diminished.
Additionally, the authors note that the improvements are most pronounced on specific types of neuron structures, and the method may not generalize equally well to all neuron morphologies. Further research is needed to understand the underlying reasons for these variations in performance.
Another potential concern is the computational cost and memory requirements of the combined ViT and 3D U-Net architecture. While the authors report that their method is efficient, the increased complexity may limit its deployment in resource-constrained environments, such as on-device processing for real-time applications.
Overall, the paper presents a compelling approach that demonstrates the value of leveraging pre-trained vision models, even if the target task is quite different from the original pre-training domain. The findings suggest that continued research into cross-modal and cross-task transfer learning could lead to further advancements in 3D biomedical image analysis and other specialized computer vision problems.
Conclusion
This paper introduces a novel method for boosting the performance of 3D neuron segmentation by incorporating a 2D Vision Transformer model pre-trained on large-scale natural image datasets. The authors' key insight is that the general visual representations learned by the ViT model can be effectively transferred to the 3D neuron segmentation task, leading to significant improvements over other state-of-the-art approaches.
The findings highlight the potential of leveraging pre-trained visual models, even when the target task is quite different from the original pre-training domain. This suggests that continued research into cross-modal and cross-task transfer learning could lead to further advancements in 3D biomedical image analysis and other specialized computer vision problems. While the approach has some limitations, the paper presents a compelling and impactful contribution to the field of 3D neuron segmentation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Boosting 3D Neuron Segmentation with 2D Vision Transformer Pre-trained on Natural Images
Yik San Cheng, Runkai Zhao, Heng Wang, Hanchuan Peng, Weidong Cai
Neuron reconstruction, one of the fundamental tasks in neuroscience, rebuilds neuronal morphology from 3D light microscope imaging data. It plays a critical role in analyzing the structure-function relationship of neurons in the nervous system. However, due to the scarcity of neuron datasets and high-quality SWC annotations, it is still challenging to develop robust segmentation methods for single neuron reconstruction. To address this limitation, we aim to distill the consensus knowledge from massive natural image data to aid the segmentation model in learning the complex neuron structures. Specifically, in this work, we propose a novel training paradigm that leverages a 2D Vision Transformer model pre-trained on large-scale natural images to initialize our Transformer-based 3D neuron segmentation model with a tailored 2D-to-3D weight transferring strategy. Our method builds a knowledge sharing connection between the abundant natural and the scarce neuron image domains to improve the 3D neuron segmentation ability in a data-efficiency manner. Evaluated on a popular benchmark, BigNeuron, our method enhances neuron segmentation performance by 8.71% over the model trained from scratch with the same amount of training samples.
Read more5/7/2024
0
SegFormer3D: an Efficient Transformer for 3D Medical Image Segmentation
Shehan Perera, Pouyan Navard, Alper Yilmaz
The adoption of Vision Transformers (ViTs) based architectures represents a significant advancement in 3D Medical Image (MI) segmentation, surpassing traditional Convolutional Neural Network (CNN) models by enhancing global contextual understanding. While this paradigm shift has significantly enhanced 3D segmentation performance, state-of-the-art architectures require extremely large and complex architectures with large scale computing resources for training and deployment. Furthermore, in the context of limited datasets, often encountered in medical imaging, larger models can present hurdles in both model generalization and convergence. In response to these challenges and to demonstrate that lightweight models are a valuable area of research in 3D medical imaging, we present SegFormer3D, a hierarchical Transformer that calculates attention across multiscale volumetric features. Additionally, SegFormer3D avoids complex decoders and uses an all-MLP decoder to aggregate local and global attention features to produce highly accurate segmentation masks. The proposed memory efficient Transformer preserves the performance characteristics of a significantly larger model in a compact design. SegFormer3D democratizes deep learning for 3D medical image segmentation by offering a model with 33x less parameters and a 13x reduction in GFLOPS compared to the current state-of-the-art (SOTA). We benchmark SegFormer3D against the current SOTA models on three widely used datasets Synapse, BRaTs, and ACDC, achieving competitive results. Code: https://github.com/OSUPCVLab/SegFormer3D.git
Read more4/17/2024
📈
0
Enhancing 3D Transformer Segmentation Model for Medical Image with Token-level Representation Learning
Xinrong Hu, Dewen Zeng, Yawen Wu, Xueyang Li, Yiyu Shi
In the field of medical images, although various works find Swin Transformer has promising effectiveness on pixelwise dense prediction, whether pre-training these models without using extra dataset can further boost the performance for the downstream semantic segmentation remains unexplored.Applications of previous representation learning methods are hindered by the limited number of 3D volumes and high computational cost. In addition, most of pretext tasks designed specifically for Transformer are not applicable to hierarchical structure of Swin Transformer. Thus, this work proposes a token-level representation learning loss that maximizes agreement between token embeddings from different augmented views individually instead of volume-level global features. Moreover, we identify a potential representation collapse exclusively caused by this new loss. To prevent collapse, we invent a simple rotate-and-restore mechanism, which rotates and flips one augmented view of input volume, and later restores the order of tokens in the feature maps. We also modify the contrastive loss to address the discrimination between tokens at the same position but from different volumes. We test our pre-training scheme on two public medical segmentation datasets, and the results on the downstream segmentation task show more improvement of our methods than other state-of-the-art pre-trainig methods.
Read more8/13/2024

0
The More You See in 2D, the More You Perceive in 3D
Xinyang Han, Zelin Gao, Angjoo Kanazawa, Shubham Goel, Yossi Gandelsman
Humans can infer 3D structure from 2D images of an object based on past experience and improve their 3D understanding as they see more images. Inspired by this behavior, we introduce SAP3D, a system for 3D reconstruction and novel view synthesis from an arbitrary number of unposed images. Given a few unposed images of an object, we adapt a pre-trained view-conditioned diffusion model together with the camera poses of the images via test-time fine-tuning. The adapted diffusion model and the obtained camera poses are then utilized as instance-specific priors for 3D reconstruction and novel view synthesis. We show that as the number of input images increases, the performance of our approach improves, bridging the gap between optimization-based prior-less 3D reconstruction methods and single-image-to-3D diffusion-based methods. We demonstrate our system on real images as well as standard synthetic benchmarks. Our ablation studies confirm that this adaption behavior is key for more accurate 3D understanding.
Read more4/5/2024