Enhancing 3D Transformer Segmentation Model for Medical Image with Token-level Representation Learning

0
📈
Sign in to get full access
Overview
- The provided paper discusses enhancing a 3D transformer-based segmentation model for medical images using token-level representation learning.
- It presents a supplemental material document that accompanies the main research paper.
- The goal is to improve the performance of the 3D transformer model by incorporating token-level representation learning techniques.
Plain English Explanation
The paper focuses on improving a type of AI model called a 3D transformer, which is used for segmenting, or dividing up, medical images like CT scans or MRIs. Segmentation is an important task in medical imaging that helps identify different structures or tissues within the body.
The researchers tried to enhance the 3D transformer model by using a technique called "token-level representation learning." This means they tried to get the model to better understand the individual "tokens," or small pieces of information, that make up the image. By improving how the model processes these tokens, they hoped to boost the overall segmentation performance.
The supplemental material provided additional details and insights beyond what was covered in the main research paper. For example, it likely included more technical information about the model architecture, the training process, and the experimental results.
Technical Explanation
The paper presents a 3D transformer-based segmentation model that incorporates token-level representation learning. The key aspects include:
- Model Architecture: The model uses a 3D transformer design, which is well-suited for processing volumetric medical image data. The SegFormer3D and Swin-SMT architectures are examples of 3D transformer models.
- Token-level Representation Learning: The researchers aimed to improve how the model learns and represents the individual tokens (small image patches) that make up the 3D medical images. This involves techniques like self-supervised pretraining and using semantically meaningful tokens.
- Experiments and Insights: The supplemental material likely includes details on the experimental setup, the datasets used, and the performance improvements achieved by incorporating token-level representation learning into the 3D transformer model. It may also discuss insights gained from the research.
Critical Analysis
The supplemental material likely addresses some of the limitations or caveats of the research, which were not covered in the main paper. For example, it may discuss:
- The generalizability of the findings: How well does the enhanced 3D transformer model perform on a diverse range of medical imaging datasets and tasks?
- The computational and memory requirements of the model: Is the additional complexity introduced by token-level representation learning worth the performance gains, or are there efficiency trade-offs to consider?
- Potential biases or artifacts in the training data: How might these affect the model's performance and robustness in real-world clinical settings?
Additionally, the critical analysis section could raise questions or concerns that were not addressed in the paper, such as:
- The interpretability and explainability of the token-level representations: Can clinicians understand how the model is making decisions, or is it a "black box"?
- The ethical implications of deploying such advanced AI models in healthcare: Are there potential risks or unintended consequences that need to be carefully considered?
Conclusion
In summary, the provided paper focuses on enhancing a 3D transformer-based segmentation model for medical images through the use of token-level representation learning techniques. The supplemental material likely delves into the technical details of the model architecture, the experimental setup, and the performance improvements achieved.
The critical analysis section raises important questions about the generalizability, efficiency, and potential biases of the enhanced model, as well as the interpretability and ethical implications of deploying such advanced AI systems in healthcare. Overall, this research represents an important step forward in the development of more accurate and robust 3D medical image segmentation models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📈
0
Enhancing 3D Transformer Segmentation Model for Medical Image with Token-level Representation Learning
Xinrong Hu, Dewen Zeng, Yawen Wu, Xueyang Li, Yiyu Shi
In the field of medical images, although various works find Swin Transformer has promising effectiveness on pixelwise dense prediction, whether pre-training these models without using extra dataset can further boost the performance for the downstream semantic segmentation remains unexplored.Applications of previous representation learning methods are hindered by the limited number of 3D volumes and high computational cost. In addition, most of pretext tasks designed specifically for Transformer are not applicable to hierarchical structure of Swin Transformer. Thus, this work proposes a token-level representation learning loss that maximizes agreement between token embeddings from different augmented views individually instead of volume-level global features. Moreover, we identify a potential representation collapse exclusively caused by this new loss. To prevent collapse, we invent a simple rotate-and-restore mechanism, which rotates and flips one augmented view of input volume, and later restores the order of tokens in the feature maps. We also modify the contrastive loss to address the discrimination between tokens at the same position but from different volumes. We test our pre-training scheme on two public medical segmentation datasets, and the results on the downstream segmentation task show more improvement of our methods than other state-of-the-art pre-trainig methods.
Read more8/13/2024
0
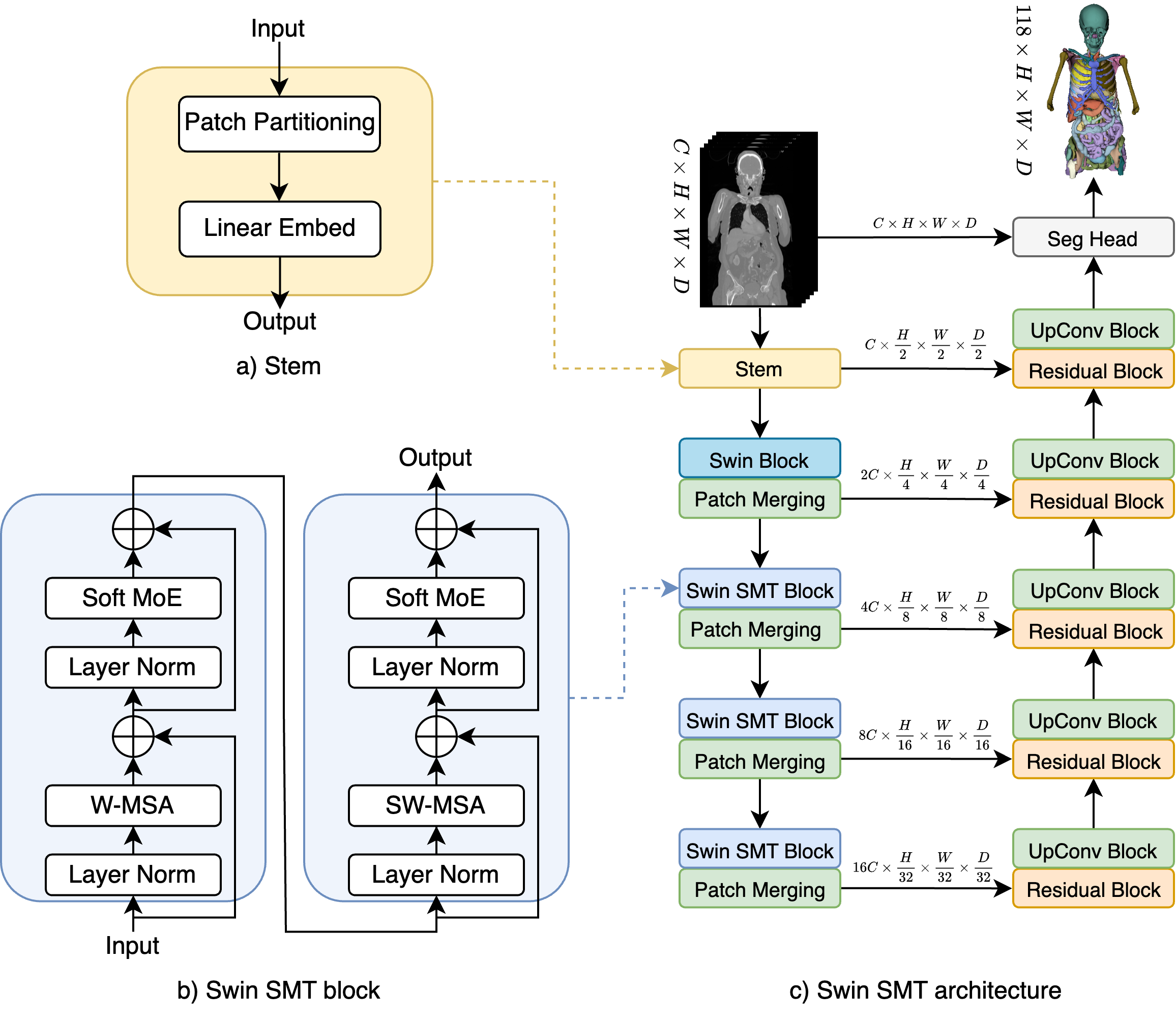
Swin SMT: Global Sequential Modeling in 3D Medical Image Segmentation
Szymon P{l}otka, Maciej Chrabaszcz, Przemyslaw Biecek
Recent advances in Vision Transformers (ViTs) have significantly enhanced medical image segmentation by facilitating the learning of global relationships. However, these methods face a notable challenge in capturing diverse local and global long-range sequential feature representations, particularly evident in whole-body CT (WBCT) scans. To overcome this limitation, we introduce Swin Soft Mixture Transformer (Swin SMT), a novel architecture based on Swin UNETR. This model incorporates a Soft Mixture-of-Experts (Soft MoE) to effectively handle complex and diverse long-range dependencies. The use of Soft MoE allows for scaling up model parameters maintaining a balance between computational complexity and segmentation performance in both training and inference modes. We evaluate Swin SMT on the publicly available TotalSegmentator-V2 dataset, which includes 117 major anatomical structures in WBCT images. Comprehensive experimental results demonstrate that Swin SMT outperforms several state-of-the-art methods in 3D anatomical structure segmentation, achieving an average Dice Similarity Coefficient of 85.09%. The code and pre-trained weights of Swin SMT are publicly available at https://github.com/MI2DataLab/SwinSMT.
Read more7/11/2024
0
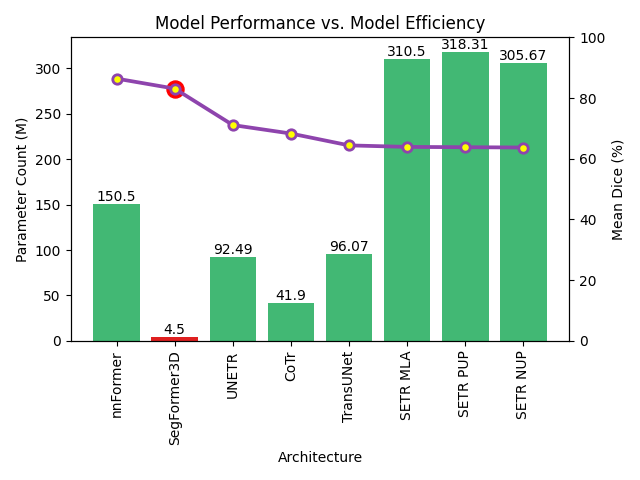
SegFormer3D: an Efficient Transformer for 3D Medical Image Segmentation
Shehan Perera, Pouyan Navard, Alper Yilmaz
The adoption of Vision Transformers (ViTs) based architectures represents a significant advancement in 3D Medical Image (MI) segmentation, surpassing traditional Convolutional Neural Network (CNN) models by enhancing global contextual understanding. While this paradigm shift has significantly enhanced 3D segmentation performance, state-of-the-art architectures require extremely large and complex architectures with large scale computing resources for training and deployment. Furthermore, in the context of limited datasets, often encountered in medical imaging, larger models can present hurdles in both model generalization and convergence. In response to these challenges and to demonstrate that lightweight models are a valuable area of research in 3D medical imaging, we present SegFormer3D, a hierarchical Transformer that calculates attention across multiscale volumetric features. Additionally, SegFormer3D avoids complex decoders and uses an all-MLP decoder to aggregate local and global attention features to produce highly accurate segmentation masks. The proposed memory efficient Transformer preserves the performance characteristics of a significantly larger model in a compact design. SegFormer3D democratizes deep learning for 3D medical image segmentation by offering a model with 33x less parameters and a 13x reduction in GFLOPS compared to the current state-of-the-art (SOTA). We benchmark SegFormer3D against the current SOTA models on three widely used datasets Synapse, BRaTs, and ACDC, achieving competitive results. Code: https://github.com/OSUPCVLab/SegFormer3D.git
Read more4/17/2024
0
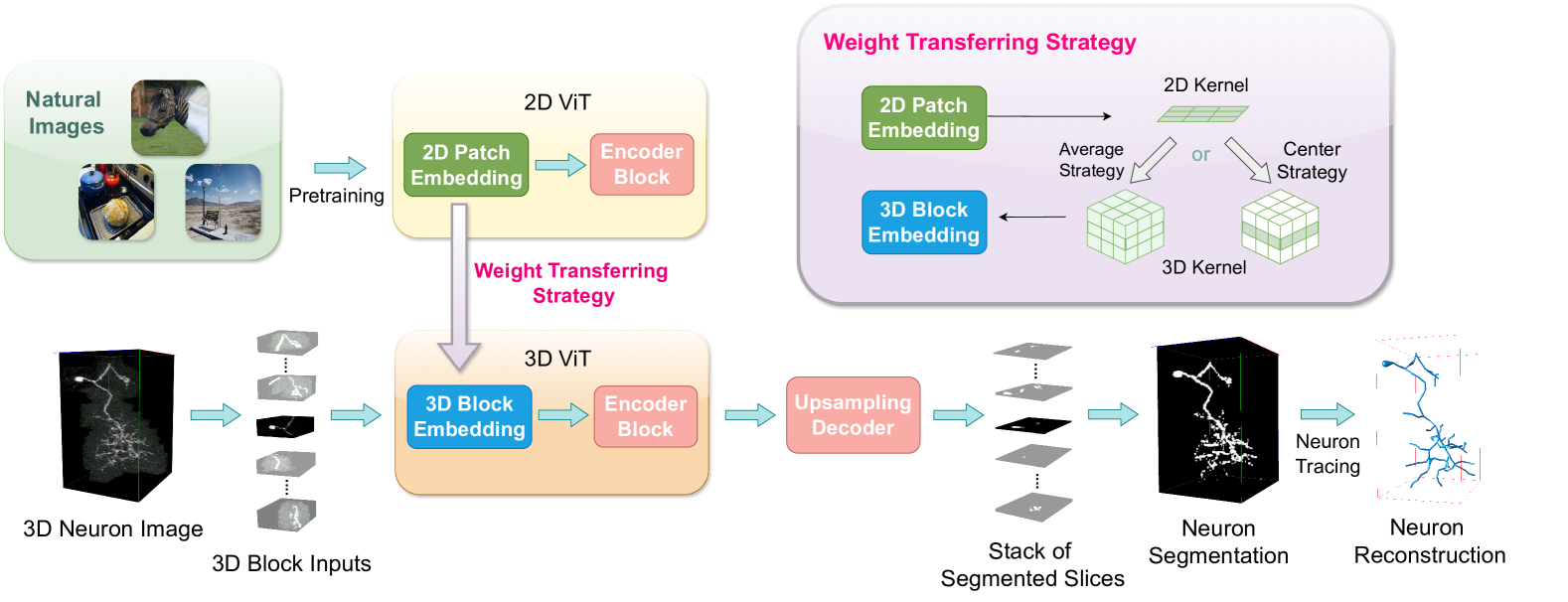
Boosting 3D Neuron Segmentation with 2D Vision Transformer Pre-trained on Natural Images
Yik San Cheng, Runkai Zhao, Heng Wang, Hanchuan Peng, Weidong Cai
Neuron reconstruction, one of the fundamental tasks in neuroscience, rebuilds neuronal morphology from 3D light microscope imaging data. It plays a critical role in analyzing the structure-function relationship of neurons in the nervous system. However, due to the scarcity of neuron datasets and high-quality SWC annotations, it is still challenging to develop robust segmentation methods for single neuron reconstruction. To address this limitation, we aim to distill the consensus knowledge from massive natural image data to aid the segmentation model in learning the complex neuron structures. Specifically, in this work, we propose a novel training paradigm that leverages a 2D Vision Transformer model pre-trained on large-scale natural images to initialize our Transformer-based 3D neuron segmentation model with a tailored 2D-to-3D weight transferring strategy. Our method builds a knowledge sharing connection between the abundant natural and the scarce neuron image domains to improve the 3D neuron segmentation ability in a data-efficiency manner. Evaluated on a popular benchmark, BigNeuron, our method enhances neuron segmentation performance by 8.71% over the model trained from scratch with the same amount of training samples.
Read more5/7/2024